

硬件加速边缘检测优化处理方案
FPGA/ASIC技术
描述
摘 要: 针对计算机处理高清图像或视频的边缘检测时存在延时长和数据存储带宽受限的缺点,提出了用Vivado HLS将边缘检测软件代码转换成RTL级硬件电路的硬件加速方法。硬件加速是将运算量大的功能模块由硬件电路实现,根据硬件电路工作频率高和数据位宽自定义,可以解决延时长和数据宽度受限的缺点。实验结果表明,边缘检测硬件加速方法不仅使延时和数据带宽都得到了改善,而且也缩短了边缘检测的开发周期。
0 引言
在计算机视觉和图像处理领域中,图像边缘检测技术起着重要的作用,其效果好坏直接影响整个系统的性能。由于图像的边缘蕴含了丰富的内在信息,是进行图像分割、特征值提取的重要依据。边缘检测不仅能减少处理数据,又能保留图像中物体的形状信息,是实时图像处理中的重要内容之一[1]。
在现阶段,主要采用软件方式或者FPGA硬件方式来实现边缘检测。文献[2]-[4]采用软件方法实现图像的边缘检测,虽然边缘检测的效果得到了改善,但是不能在延时和数据带宽方面做出改善。文献[5]-[7]采用FPGA方法实现图像的边缘检测,此硬件方法虽然改善了边缘检测的延时长和数据带宽受限的不足,但是由于FPGA硬件设计的复杂性会导致整个电路开发周期变长。
本文采用Xilinx公司的Vivado HLS将边缘检测的软件代码转化为RTL硬件电路。这样不仅解决了软件方法所带给系统延时长和数据带宽窄的缺点,而且避免了FPGA硬件电路设计周期长的不足。
1 边缘检测算法设计
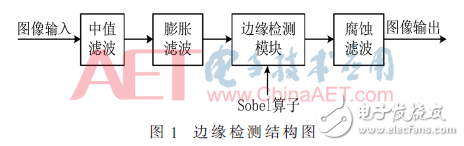
基于Sobel算子的边缘检测具有算法简单、实现方便等优势,但在处理图像时会存在对噪声敏感和边缘界限模糊等不足,所以需要在Sobel算法的基础上进行优化。优化后的边缘检测由中值滤波、膨胀滤波、边缘检测模块和腐蚀滤波模块构成,如图1所示。在图像输入后,首先中值滤波器对输入图像进行平滑图像噪声处理,然后由膨胀滤波器求出图像的局部最大值,再由边缘检测模块来提取图像的边缘信息,最后由腐蚀滤波器消除图像中的“斑点”噪声,从而得到最佳的图像边缘。
2 边缘检测软硬件协同设计
边缘检测的软硬件协同设计主要包括软件应用设计、硬件加速设计和SoC应用设计。
2.1 软硬件协作开发流程
软件应用设计是将边缘检测的功能用OpenCV函数或者自定义功能函数实现;硬件加速设计将软件代码转换为RTL电路,其中不可综合的函数或者语句需用Vivado HLS支持的函数替换;SoC应用设计将Vivado HLS输出的RTL电路应用到实际的SoC系统[8]。图2是边缘检测硬件加速流程图。
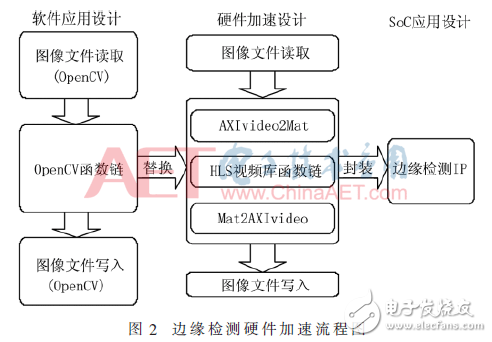
如图2所示,首先完成软件应用的开发,然后将Vivado HLS不能综合的OpenCV函数链替换成HLS视频库函数链,最后封装成IP在FPGA中调用。
2.2 边缘检测软硬件协作实现
在软件实现阶段使用OpenCV函数库或者自定义的C语言函数实现边缘检测算法,但Vivado HLS不能综合所有的软件代码。当软件代码中存在Vivado HLS不能综合的函数时就需要将这些函数展开或者替换,如定点运算、片上的行缓存和窗口缓存来完成动态的内存分配、浮点和图像在外部存储器中存放和修改的操作。
硬件加速方案是在软件应用的基础上实现的。在搭建SoC时,使用的是芯片内部的AXI互联总线,其所支持的数据类型是AXI4 video stream。在设计边缘检测IP接口时需要将AXI4 video stream与Vivado HLS所支持的hls::Mat类型进行相互转换。数据的转换模块见图2中AXIvideo2Mat和Mat2AXIvideo模块。Vivado HLS将OpenCV函数链转换成HLS视频库函数链。硬件加速阶段包括边缘检测的仿真与优化,只有在优化和仿真通过之后才将RTL级电路封装成IP核输出。
3 系统搭建与IP核优化
边缘检测的软硬件协作应用具有一定的局限性,只能在具备处理器和可编程逻辑阵列的SoC中应用。本文是在Xilinx公司的zc7z020clg484-1系列芯片中进行边缘检测的系统搭建与功能验证。
3.1 SoC系统设计
Vivado HLS将边缘检测IP输出到Vivado的IP catalog,在SoC系统设计时调用边缘检测IP核即可。搭建的边缘检测SoC系统如图3所示。
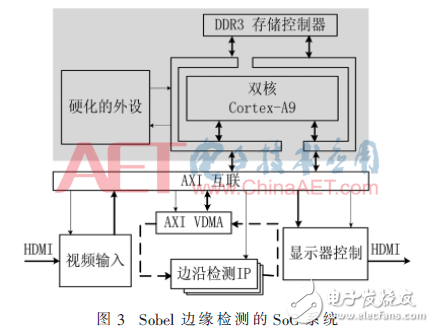
在图3中,粗箭头表示图像数据流的路径,细箭头表示控制信号的方向。图3所示的阴影部分为可裁剪系统(PS),白色区域为可编程逻辑(PL)。由于Vivado HLS不支持指针访问帧缓存,需要用AXI VDMA来访问帧数据。
视频流经过HDMI输入到视频输入控制器,数据流通过AXI互联总线存入到DDR3存储器中,Cortex-A9通过AXI互联总线控制AXI VDMA和边缘检测IP去存取图像数据,处理完的数据缓存到DDR3,最后 Cortex-A9将处理好的数据输出到视频显示控制器。硬件加速是将Cortex-A9处理的运算转移到PL去完成,这样会减少处理器的负载。
3.2 HLS模块优化
Vivado HLS有两种优化方式,一种是在Directive控制栏设置优化变量和参数,另一种方法是在代码中使用#pragma命令来定义变量实现类型和结构。根据系统的需求对边缘检测进行串行和并行实现策略。
3.2.1 串行实现方案
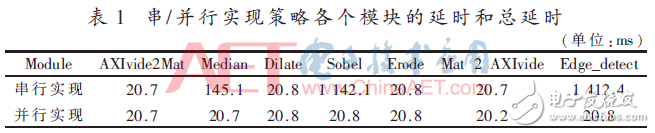
串行实现是保持软件代码的顺序执行结构,边缘检测模块按照顺序串行执行。当硬件电路工作在100 MHz频率时,处理像素为(1 080×1 092)的图像速率为0.7帧/s。通过表1可知Sobel子模块消耗了1 142 ms,导致了整个边缘检测功能块的速率降低。当边缘检测IP的数据的宽度为16 bit、像素深度为8 bit时,边缘检测的处理速率为825.5 KB/s。
3.2.2 并行实现方案
并行实现是将for循环打平、替换数组和增加流水线操作来实现并行执行。与串行实现对比可知,在速率方面提高68.5倍左右,在100 MHz的频率下,处理像素为(1 080×1 092)的图像速率为48帧/s。当边缘检测IP的数据的宽度为16 bit、像素深度为8 bit时,边缘检测的处理速率为56 609.28 KB/s。
通过以上两种实现可知,并行比串行实现的处理速率速度提高了68.5倍左右,与处理时间相对应的数据吞吐率也提高了68.5倍。当数据带宽不满足要求时,可以通过修改软件代码中变量的位宽来增加IP数据端口的宽度,从而提高数据吞吐量。
硬件电路所使用的资源往往也是算法考虑的因素之一。表2是两种实现策略所需要的硬件资源。

在资源使用方面,并行比串行实现所使用的资源多,占整个芯片的资源分别为BRAM_18K为10%,DSP48E为0,FF为3%,LUT为10%。可知资源满足设计要求。
4 结果分析
通过三组公路真实场景来验证本文边缘检测的效果。第一组是在白天拍摄的公路场景,见图4,图4(a)为输入的原始图像,图4(b)为OpenCV边缘检测的结果,图4(c)为硬件加速边缘检测结果。第二组是在晚间拍摄的公路场景(曝光效果差),见图5,图5(a)为输入的原始图像,图5(b)为OpenCV边缘检测的结果,图5(c)为硬件加速边缘检测结果。第三组是在晚间拍摄的公路场景,见图6,图6(a)为输入的原始图像,图6(b)为OpenCV边缘检测的结果,图6(c)为硬件加速边缘检测结果。



对图4、图5和图6从横纵两个角度来分析硬件加速边缘检测的效果。横向分析,与OpenCV边缘检测结果比较可知,硬件加速方案输出边缘图像线条更加的明显,在图5曝光效果差的情况下OpenCV存在边缘漏检测的情形,而硬件加速方案则不存在漏检的情况;纵向分析,在白天拍摄的场景边缘检测的结果要比晚上输出的效果好些,在晚上拍摄的场景曝光好的边缘检测效果要比曝光差输出的效果好。
对三组场景下的硬件加速边缘检测效果分析可知,硬件加速边缘检测明效果显优于OpenCV边缘检测,同时在相机曝光效果差或者外界环境复杂的情况下,硬件加速边缘检测都能进行有效边缘检测。
5 结论
针对传统OpenCV图像处理存在延时长和数据带宽受限的缺点,采用硬件加速可以弥此不足。采用Vivado HLS在软件应用的基础上进一步实现硬件电路设计,大大缩短了系统的开发周期。本文不仅提出边缘检测的硬件加速方案,同时提出了在数据处理量大和处理速度快的应用中可以通过软硬件结合来提供系统设计的方案。
-
硬件加速模块的时钟设计2025-10-23 281
-
基于 DSP5509 进行数字图像处理中 Sobel 算子边缘检测的硬件连接电路图2024-09-25 13804
-
基于FPGA的实时边缘检测系统设计,Sobel图像边缘检测,FPGA图像处理2024-05-24 3475
-
Hyperon—大数据应用的硬件加速解决方案2023-09-13 835
-
基于FPGA的Poseidon哈希算法硬件加速方案2022-08-19 3748
-
硬件加速器提升下一代SHARC处理器的性能2021-04-23 1040
-
分享硬件加速仿真的 11 个谬论介绍和说明2019-10-11 6221
-
阿里七层流量入口 Tengine硬件加速探索之路2018-06-04 2005
-
MD5算法硬件加速模型2018-01-12 1058
-
利用硬件加速器提高处理器的性能2017-12-04 1942
-
基于FPGA的边缘检测和Sobel算法2017-11-29 12652
-
MCU厂推多样解决方案 DSP/FPU硬件加速芯片整合2016-10-14 2278
-
精确分类的视角无关人脸检测方法与硬件加速体系结构2016-09-18 670
-
采用硬件加速发挥MicroBlaze处理能力2010-03-10 1642
全部0条评论

快来发表一下你的评论吧 !
