

深度卷积神经网络在目标检测中的进展
电子常识
描述
近些年来,深度卷积神经网络(DCNN)在图像分类和识别上取得了很显著的提高。回顾从2014到2016这两年多的时间,先后涌现出了R-CNN,Fast R-CNN, Faster R-CNN, ION, HyperNet, SDP-CRC, YOLO,G-CNN, SSD等越来越快速和准确的目标检测方法。
1、基于Region Proposal的方法
该类方法的基本思想是:先得到候选区域再对候选区域进行分类和边框回归。

1.1 R-CNN [1]
R-CNN是较早地将DCNN用到目标检测中的方法。其中心思想是对图像中的各个候选区域先用DCNN进行特征提取并使用一个SVM进行分类,分类的结果是一个初略的检测结果,之后再次使用DCNN的特征,结合另一个SVM回归模型得到更精确的边界框。
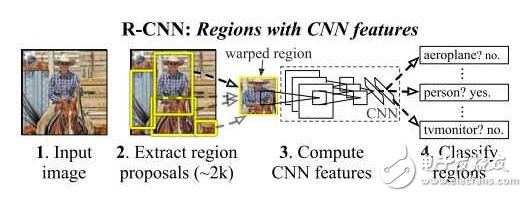
其中获取候选区域的方法是常用的selective search。 一个图形中可以得到大约2000个不同大小、不同类别的候选区域,他们需要被变换到同一个尺寸以适应CNN所处理的图像大小(227x227)。
该文章中使用的CNN结构来自AlexNet,已经在ImageNet数据集上的1000个类别的分类任务中训练过,再通过参数微调使该网络结构适应该文章中的21个类别的分类任务。
该方法在VOC 2011 test数据集上取得了71.8%的检测精度。该方法的缺点是:1,训练和测试过程分为好几个阶段:得到候选区域,DCNN 特征提取, SVM分类、SVM边界框回归,训练过程非常耗时。2,训练过程中需要保存DCNN得到的特征,很占内存空间。3, 测试过程中,每一个候选区域都要提取一遍特征,而这些区域有一定重叠度,各个区域的特征提取独立计算,效率不高,使测试一幅图像非常慢。
1.2 Fast R-CNN[2]
在R-CNN的基础上,为了使训练和测试过程更快,Ross Girshick 提出了Fast R-CNN,使用VGG19网络结构比R-CNN在训练和测试时分别快了9倍和213倍。
其主要想法是:
1)对整个图像进行卷积得到特征图像而不是对每个候选区域分别算卷积;
2)把候选区域分类和边框拟合的两个步骤结合起来而不是分开做。
原理图如下:
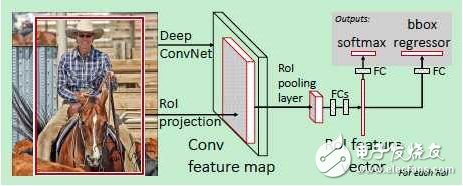

公式中的两项分别是classification loss 和regression loss。该方法相比于R-CNN快了不少。特别是在测试一幅新图像时,如果不考虑生成候选区域的时间,可以达到实时检测。生成候选区域的selective search算法处理一张图像大概需要2s的时间,因此成为该方法的一个瓶颈。
1.3 Faster R-CNN[3]
上面两种方法都依赖于selective search生成候选区域,十分耗时,那么可不可以直接利用卷积神经网络得到候选区域呢?这样的话就几乎可以不花额外的时间代价就能得到候选区域。
Shaoqing Ren提出了Faster R-CNN来实现这种想法:假设有两个卷积神经网络,一个是区域生成网络,得到图像中的各个候选区域,另一个是候选区域的分类和边框回归网路。这两个网络的前几层都要计算卷积,如果让它们在这几层共享参数,只是在末尾的几层分别实现各自的特定的目标任务,那么对一幅图像只需用这几个共享的卷积层进行一次前向卷积计算,就能同时得到候选区域和各候选区域的类别及边框。
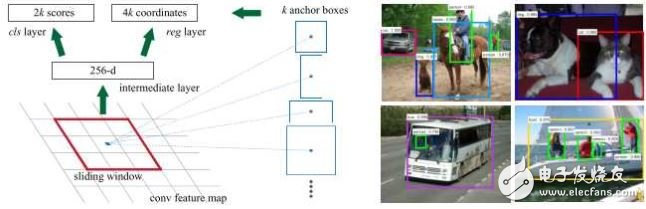

使用RPN得到候选区域后,对候选区域的分类和边框回归仍然使用Fast R-CNN。这两个网络使用共同的卷积层。 由于Fast R-CNN的训练过程中需要使用固定的候选区域生成方法,不能同时对RPN和Fast R-CNN使用反向传播算法进行训练。
该文章使用了四个步骤完成训练过程:
1)单独训练RPN;
2)使用步骤中1得到的区域生成方法单独训练Fast R-CNN;
3)使用步骤2得到的网络作为初始网络训练RPN。
4)再次训练Fast R-CNN, 微调参数。
Faster R-CNN的精度和Fast R-CNN差不多,但是训练时间和测试时间都缩短了10倍。
1.4 ION: Inside-Outside Net[4]
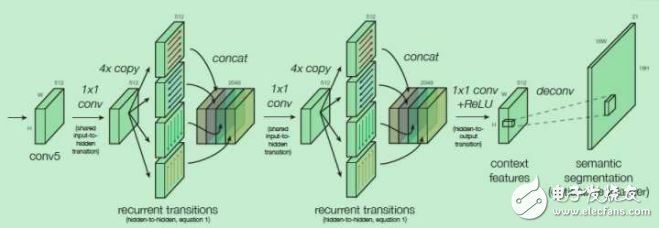
ION也是基于Region Proposal的,在得到候选区域的基础上,为了进一步提高在每一个候选感兴趣区域ROI的预测精度,ION考虑了结合ROI内部的信息和ROI以外的信息,有两个创新点:一是使用空间递归神经网络(spatial recurrent neural network)把上下文(context)特征结合,而不是只使用ROI内的局部特征 ,二是将不同卷积层得到的特征连接起来,作为一个多尺度特征用来预测。
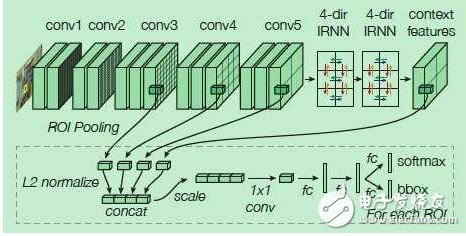
ION在上、下、左、右四个方向独立地使用RNN,并把它们的输出连接起来组合成一个特征输出,经过两次这样的过程得到的特征作为上下文特征,再与之前的几个卷积层的输出特征连接起来,得到既包括上下文信息,又包括多尺度信息的特征。
1.5 HyperNet[5]
HyperNet在Faster R-CNN的基础上,在得到更好的候选区域方面比Faster R-CNN中使用的RPN有了进一步的提高。其想法也是把不同卷积层得到的特征图像结合起来,产生更好的region proposal和检测准确率。
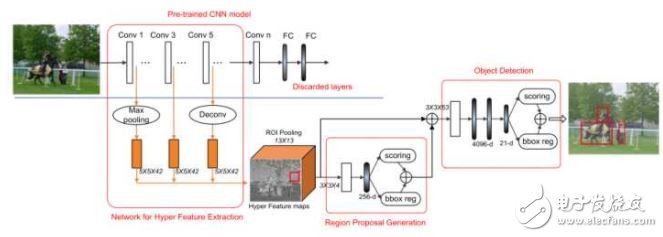
该文章把不同卷积层的输出结合起来得到的特征成为Hyper Feature。由于不同卷积层的输出大小不一样,较浅层的特征图像分辨率较高,对提高边界框的精确性有益,但是容易对边界框内的物体错误分类;较深层得到的特征图像分辨率很低,对小一些的物体的边界框定位容易不准确,但这些特征更加抽象,可以让对物体的分类的准确性更高。因此二者的结合,对目标检测的正确率和定位精度都有帮助。
1.6SDP-CRC[6]
SDP-CRC在处理不同尺度的目标和提高对候选区域的计算效率上提出了两个策略。第一个策略是基于候选区域尺度的池化,即Scale Department Pooling (SDP)。在CNN的框架中,由于输入图像要经过多次卷积,那些尺寸小的物体在最后一层的卷积输出上的特征不能很好的描述该物体。如果用前面某一层的特征,则能够更好的描述小物体,用靠后的层的特征,则能更好地描述较大的物体。
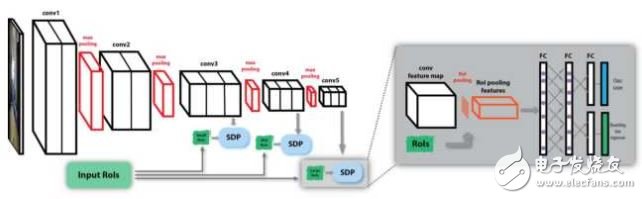
因此SDP的想法是根据物体大小选择合适的卷积层上的特征来描述该物体。例如一个候选区域的高度在0-64个像素之间,则使用第三个卷积层上(例如VGG中的Conv3)的特征进行pooling作为分类器和边框回归器的输入特征,如果候选区域高度在128个像素以上,则使用最后一个卷积层(例如VGG中的Conv5)的特征进行分类和回归。
第二个策略是使用舍弃负样本的级联分类器,即Cascaded Rejection Classifer, CRC。Fast RCNN的一个瓶颈是有很多的候选区域,对成千上万个候选区域都进行完整的分类和回归计算十分耗时。CRC可以用来快速地排除一些明显不包含某个物体的候选区域,只将完整的计算集中在那些极有可能包含某个物体的候选区域。该文章中使用了AdaBoost的方法,按顺序使用每一个卷积层的特征,由一些级联的弱分类器来排除负样本。在最后一层卷积的特征图像上,留下来的那些候选区域再进行分类和回归。
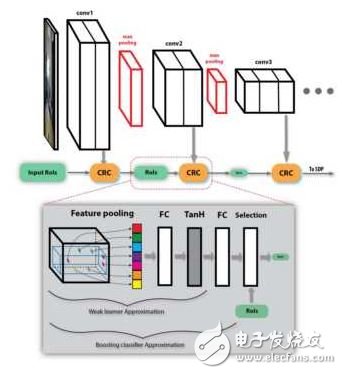
SDP-CRC的准确率比Fast RNN提高了不少,检测时间缩短到了471ms每帧。
2、不采用Region Propsal, 直接预测边界框的方法
2.1 YOLO[7]
YOLO的思想是摒弃生成候选区域的中间步骤,通过单个卷积神经网络直接对各个边界框进行回归并且预测相应的类别的概率。
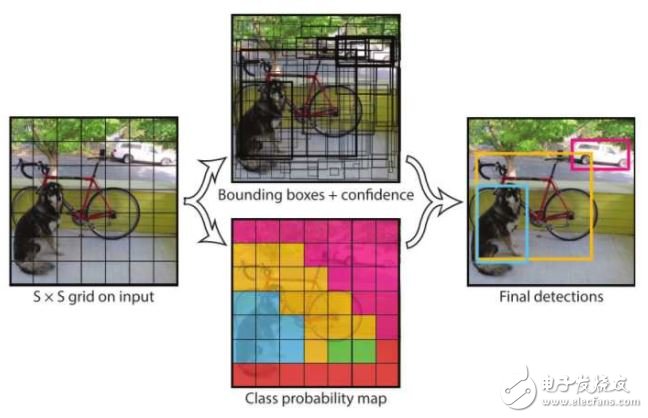

在测试阶段,单元格的类别概率与该单元格的B个边界框的可信度相乘,得到各个边界框分别包含各个类别的物体的可信度。
YOLO的优点是速度快,该文章中使用的24层卷积网络在测试图像上可达到45帧每秒,而使用另一个简化的网络结构,可达到155帧每秒。该方法的缺点有:1, 边界框的预测有很大的空间限制,例如每一个单元格只预测两个边界框,并且只有一个类别。2,该方法不能很好地检测到成群出现的一些小的目标,比如一群鸟。3,如果检测目标的长宽比在训练数据中没有出现过或者不常见,该模型的泛化能力较弱。
2.2 G-CNN[8]
G-CNN将目标检测问题看作是把检测框从一些固定的网格逐渐变化到物体的真实边框的问题。 这是一个经过几次迭代,不断更新的过程。
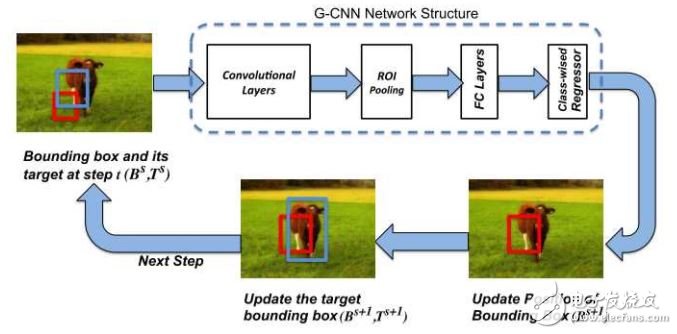
其原理图如上所示,初始检测框是对整个图像进行不同尺度的网格划分得到的,在经过卷积后得到物体的特征图像,将初始边框对应的特征图像通过Fast R-CNN 中的方法转化为一个固定大小的特征图像,通过回归得到更加准确的边框,再次将这个新边框作为初始边框,做新的一次迭代。经过若干次迭代后的边框作为输出。
G-CNN中使用约180个初始边框,经过5次迭代, 检测帧率在3fps左右,准确率比Fast R-CNN要好一些。
2.3 SSD[9]
SSD也是使用单个的卷积神经网络对图像进行卷积后,在特征图像的每一个位置处预测一系列不同尺寸和长宽比的边界框。在测试阶段,该网络对每一个边界框中分别包含各个类别的物体的可能性进行预测,并且对边界框进行调整以适应目标物体的形状。
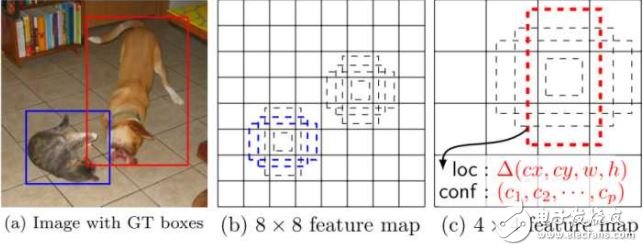
SSD在训练时只需要一幅输入图像和该图像中出现的物体的边界框。在不同的卷积层输出是不同尺度的特征图像(如上图中的8x 8和4x 4),在若干层的特征图像上的每一个位置处, 计算若干个(如4个)默认边界框内出现各个目标物体的置信度和目标物体的真实边界框相对于默认边界框的偏差。因此对于大小为mn的特征图像,共产生(c+4)kmn个输出。这有点类似于Faster R-CNN 中的锚的概念,但是将这个概念用到了不同分辨率的特征图像上。SSD和YOLO的对比如下图:
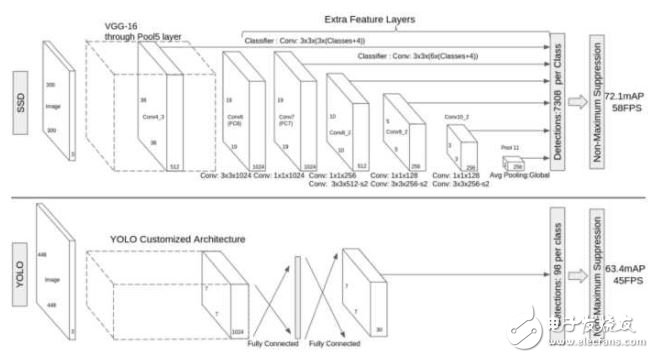
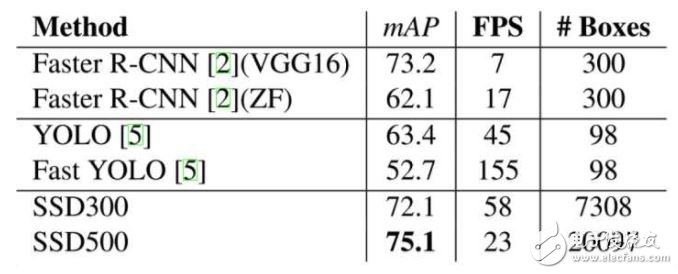
在VOC 2007测试图像上,对于300\times300大小的输入图像,SSD可达到72.1% mAP的准确率,速度为58帧每秒,且能预测7k以上个边界框,而YOLO只能预测98个。下图是上述几个算法在性能上的对比:
-
cnn卷积神经网络分类有哪些2024-07-03 3022
-
卷积神经网络的工作原理 卷积神经网络通俗解释2023-08-21 5593
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2663
-
什么是神经网络?什么是卷积神经网络?2023-02-23 5378
-
卷积神经网络模型发展及应用2022-08-02 13396
-
基于卷积神经网络的雷达目标检测方法综述2021-06-23 1363
-
深度学习中的卷积神经网络层级分解综述2021-05-19 1323
-
卷积神经网络CNN介绍2020-06-14 2274
-
卷积神经网络—深度卷积网络:实例探究及学习总结2020-05-22 3516
-
卷积神经网络如何使用2019-07-17 2896
-
基于深度卷积神经网络的航空器目标检测与识别2017-12-01 1249
全部0条评论

快来发表一下你的评论吧 !
