

机器学习:决策树--python
电子常识
描述
今天,我们介绍机器学习里比较常用的一种分类算法,决策树。决策树是对人类认知识别的一种模拟,给你一堆看似杂乱无章的数据,如何用尽可能少的特征,对这些数据进行有效的分类。
决策树借助了一种层级分类的概念,每一次都选择一个区分性最好的特征进行分类,对于可以直接给出标签 label 的数据,可能最初选择的几个特征就能很好地进行区分,有些数据可能需要更多的特征,所以决策树的深度也就表示了你需要选择的几种特征。
在进行特征选择的时候,常常需要借助信息论的概念,利用最大熵原则。
决策树一般是用来对离散数据进行分类的,对于连续数据,可以事先对其离散化。
在介绍决策树之前,我们先简单的介绍一下信息熵,我们知道,熵的定义为:

我们先构造一些简单的数据:
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
import math
import operator
def Create_data():
dataset = [[1,1,‘yes’],
[1, 1,‘yes’],
[1, 0, ‘no’],
[0, 1, ‘no’],
[0, 1, ‘no’],
[3, 0, ‘maybe’]]
feat_name = [‘no surfacing’, ‘flippers’]
return dataset, feat_name
然后定义一个计算熵的函数:
def Cal_entrpy(dataset):
n_sample = len(dataset)
n_label = {}
for featvec in dataset:
current_label = featvec[-1]
if current_label not in n_label.keys():
n_label[current_label] = 0
n_label[current_label] += 1
shannonEnt = 0.0
for key in n_label:
prob = float(n_label[key]) / n_sample
shannonEnt -= prob * math.log(prob, 2)
return shannonEnt
要注意的是,熵越大,说明数据的类别越分散,越呈现某种无序的状态。
下面再定义一个拆分数据集的函数:
def Split_dataset(dataset, axis, value):
retDataSet = []
for featVec in dataset:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1 :])
retDataSet.append(reducedFeatVec)
return retDataSet
结合前面的几个函数,我们可以构造一个特征选择的函数:
def Choose_feature(dataset):
num_sample = len(dataset)
num_feature = len(dataset[0]) - 1
baseEntrpy = Cal_entrpy(dataset)
best_Infogain = 0.0
bestFeat = -1
for i in range (num_feature):
featlist = [example[i] for example in dataset]
uniquValus = set(featlist)
newEntrpy = 0.0
for value in uniquValus:
subData = Split_dataset(dataset, i, value)
prob = len(subData) / float(num_sample)
newEntrpy += prob * Cal_entrpy(subData)
info_gain = baseEntrpy - newEntrpy
if (info_gain 》 best_Infogain):
best_Infogain = info_gain
bestFeat = i
return bestFeat
然后再构造一个投票及计票的函数
def Major_cnt(classlist):
class_num = {}
for vote in classlist:
if vote not in class_num.keys():
class_num[vote] = 0
class_num[vote] += 1
Sort_K = sorted(class_num.iteritems(),
key = operator.itemgetter(1), reverse=True)
return Sort_K[0][0]
有了这些,就可以构造我们需要的决策树了:
def Create_tree(dataset, featName):
classlist = [example[-1] for example in dataset]
if classlist.count(classlist[0]) == len(classlist):
return classlist[0]
if len(dataset[0]) == 1:
return Major_cnt(classlist)
bestFeat = Choose_feature(dataset)
bestFeatName = featName[bestFeat]
myTree = {bestFeatName: {}}
del(featName[bestFeat])
featValues = [example[bestFeat] for example in dataset]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = featName[:]
myTree[bestFeatName][value] = Create_tree(Split_dataset
(dataset, bestFeat, value), subLabels)
return myTree
def Get_numleafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == ‘dict’ :
numLeafs += Get_numleafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def Get_treedepth(myTree):
max_depth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == ‘dict’ :
this_depth = 1 + Get_treedepth(secondDict[key])
else:
this_depth = 1
if this_depth 》 max_depth:
max_depth = this_depth
return max_depth
我们也可以把决策树绘制出来:
def Plot_node(nodeTxt, centerPt, parentPt, nodeType):
Create_plot.ax1.annotate(nodeTxt, xy=parentPt,
xycoords=‘axes fraction’,
xytext=centerPt, textcoords=‘axes fraction’,
va=“center”, ha=“center”, bbox=nodeType, arrowprops=arrow_args)
def Plot_tree(myTree, parentPt, nodeTxt):
numLeafs = Get_numleafs(myTree)
Get_treedepth(myTree)
firstStr = myTree.keys()[0]
cntrPt = (Plot_tree.xOff + (1.0 + float(numLeafs))/2.0/Plot_tree.totalW,
Plot_tree.yOff)
Plot_midtext(cntrPt, parentPt, nodeTxt)
Plot_node(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
Plot_tree.yOff = Plot_tree.yOff - 1.0/Plot_tree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__==‘dict’:
Plot_tree(secondDict[key],cntrPt,str(key))
else:
Plot_tree.xOff = Plot_tree.xOff + 1.0/Plot_tree.totalW
Plot_node(secondDict[key], (Plot_tree.xOff, Plot_tree.yOff),
cntrPt, leafNode)
Plot_midtext((Plot_tree.xOff, Plot_tree.yOff), cntrPt, str(key))
Plot_tree.yOff = Plot_tree.yOff + 1.0/Plot_tree.totalD
def Create_plot (myTree):
fig = plt.figure(1, facecolor = ‘white’)
fig.clf()
axprops = dict(xticks=[], yticks=[])
Create_plot.ax1 = plt.subplot(111, frameon=False, **axprops)
Plot_tree.totalW = float(Get_numleafs(myTree))
Plot_tree.totalD = float(Get_treedepth(myTree))
Plot_tree.xOff = -0.5/Plot_tree.totalW; Plot_tree.yOff = 1.0;
Plot_tree(myTree, (0.5,1.0), ‘’)
plt.show()
def Plot_midtext(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
Create_plot.ax1.text(xMid, yMid, txtString)
def Classify(myTree, featLabels, testVec):
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == ‘dict’ :
classLabel = Classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel
最后,可以测试我们的构造的决策树分类器:
decisionNode = dict(boxstyle=“sawtooth”, fc=“0.8”)
leafNode = dict(boxstyle=“round4”, fc=“0.8”)
arrow_args = dict(arrowstyle=“《-”)
myData, featName = Create_data()
S_entrpy = Cal_entrpy(myData)
new_data = Split_dataset(myData, 0, 1)
best_feat = Choose_feature(myData)
myTree = Create_tree(myData, featName[:])
num_leafs = Get_numleafs(myTree)
depth = Get_treedepth(myTree)
Create_plot(myTree)
predict_label = Classify(myTree, featName, [1, 0])
print(“the predict label is: ”, predict_label)
print(“the decision tree is: ”, myTree)
print(“the best feature index is: ”, best_feat)
print(“the new dataset: ”, new_data)
print(“the original dataset: ”, myData)
print(“the feature names are: ”, featName)
print(“the entrpy is:”, S_entrpy)
print(“the number of leafs is: ”, num_leafs)
print(“the dpeth is: ”, depth)
print(“All is well.”)
构造的决策树最后如下所示:
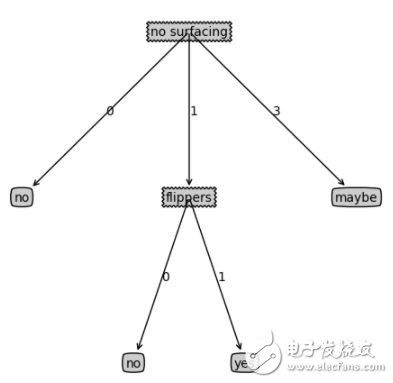
-
机器学习中常用的决策树算法技术解析2020-10-12 1626
-
关于决策树,这些知识点不可错过2018-05-23 4980
-
决策树在机器学习的理论学习与实践2019-09-20 2057
-
分类与回归方法之决策树2019-11-05 1144
-
机器学习的决策树介绍2020-04-02 1772
-
决策树的生成资料2023-09-08 479
-
基于决策树学习的智能机器人控制方法2015-11-30 464
-
决策树的构建设计并用Graphviz实现决策树的可视化2017-11-15 15240
-
机器学习之决策树生成详解2021-08-27 19555
-
决策树的原理和决策树构建的准备工作,机器学习决策树的原理2018-10-08 6828
-
详谈机器学习的决策树模型2020-07-06 4250
-
决策树的基本概念/学习步骤/算法/优缺点2021-01-27 3174
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 13871
-
决策树的结构/优缺点/生成2021-03-04 8785
-
大数据—决策树2022-10-20 1755
全部0条评论

快来发表一下你的评论吧 !
