

基于nolear建立的ConvNet体系结构并用它去训练一个特征提取器
人工智能
描述
摘要:本文展示了如何基于nolearn使用一些卷积层和池化层来建立一个简单的ConvNet体系结构,以及如何使用ConvNet去训练一个特征提取器,然后在使用如SVM、Logistic回归等不同的模型之前使用它来进行特征提取。
卷积神经网络(ConvNets)是受生物启发的MLPs(多层感知器),它们有着不同类别的层,并且每层的工作方式与普通的MLP层也有所差异。如果你对ConvNets感兴趣,这里有个很好的教程CS231n – Convolutional Neural Newtorks for Visual Recognition。CNNs的体系结构如下所示:
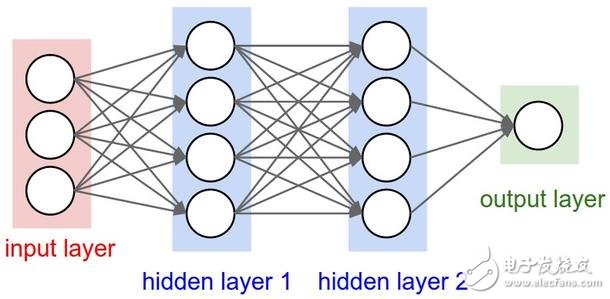
常规的神经网络
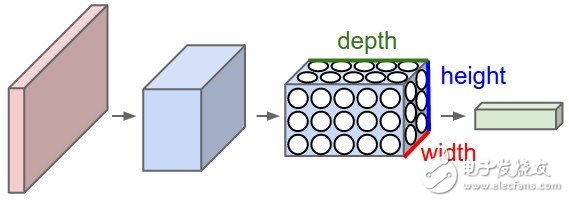
ConvNet网络体系结构
如你所见,ConvNets工作时伴随着3D卷积并且在不断转变着这些3D卷积。我在这篇文章中不会再重复整个CS231n的教程,所以如果你真的感兴趣,请在继续阅读之前先花点时间去学习一下。
Lasagne 和 nolearn
Lasagne和nolearn是我最喜欢使用的深度学习Python包。Lasagne是基于Theano的,所以GPU的加速将大有不同,并且其对神经网络创建的声明方法也很有帮助。nolearn库是一个神经网络软件包实用程序集(包含Lasagne),它在神经网络体系结构的创建过程上、各层的检验等都能够给我们很大的帮助。
在这篇文章中我要展示的是,如何使用一些卷积层和池化层来建立一个简单的ConvNet体系结构。我还将向你展示如何使用ConvNet去训练一个特征提取器,在使用如SVM、Logistic回归等不同的模型之前使用它来进行特征提取。大多数人使用的是预训练ConvNet模型,然后删除最后一个输出层,接着从ImageNets数据集上训练的ConvNets网络提取特征。这通常被称为是迁移学习,因为对于不同的问题你可以使用来自其它的ConvNets层,由于ConvNets的第一层过滤器被当做是一个边缘探测器,所以它们可以用来作为其它问题的普通特征探测器。
加载MNIST数据集
MNIST数据集是用于数字识别最传统的数据集之一。我们使用的是一个面向Python的版本,但先让我们导入需要使用的包:
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from urllib import urlretrieve
import cPickle as pickle
import os
import gzip
import numpy as np
import theano
import lasagne
from lasagne import layers
from lasagne.updates import nesterov_momentum
from nolearn.lasagne import NeuralNet
from nolearn.lasagne import visualize
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
正如你所看到的,我们导入了用于绘图的matplotlib包,一些用于下载MNIST数据集的原生Python模块,numpy, theano,lasagne,nolearn 以及 scikit-learn库中用于模型评估的一些函数。
然后,我们定义一个加载MNIST数据集的函数(这个功能与Lasagne教程上使用的非常相似)
def load_dataset():
url = 'http://deeplearning.net/data/mnist/mnist.pkl.gz'
filename = 'mnist.pkl.gz'
if not os.path.exists(filename):
print("Downloading MNIST dataset...")
urlretrieve(url, filename)
with gzip.open(filename, 'rb') as f:
data = pickle.load(f)
X_train, y_train = data[0]
X_val, y_val = data[1]
X_test, y_test = data[2]
X_train = X_train.reshape((-1, 1, 28, 28))
X_val = X_val.reshape((-1, 1, 28, 28))
X_test = X_test.reshape((-1, 1, 28, 28))
y_train = y_train.astype(np.uint8)
y_val = y_val.astype(np.uint8)
y_test = y_test.astype(np.uint8)
return X_train, y_train, X_val, y_val, X_test, y_test
正如你看到的,我们正在下载处理过的MNIST数据集,接着把它拆分为三个不同的数据集,分别是:训练集、验证集和测试集。然后重置图像内容,为之后的Lasagne输入层做准备,与此同时,由于GPU/theano数据类型的限制,我们还把numpy的数据类型转换成了uint8。
随后,我们准备加载MNIST数据集并检验它:
X_train, y_train, X_val, y_val, X_test, y_test = load_dataset()
plt.imshow(X_train[0][0], cmap=cm.binary)
这个代码将输出下面的图像(我用的是IPython Notebook)
一个MNIST数据集的数字实例(该实例是5)
ConvNet体系结构与训练
现在,定义我们的ConvNet体系结构,然后使用单GPU/CPU来训练它(我有一个非常廉价的GPU,但它很有用)
net1 = NeuralNet(
layers=[('input', layers.InputLayer),
('conv2d1', layers.Conv2DLayer),
('maxpool1', layers.MaxPool2DLayer),
('conv2d2', layers.Conv2DLayer),
('maxpool2', layers.MaxPool2DLayer),
('dropout1', layers.DropoutLayer),
('dense', layers.DenseLayer),
('dropout2', layers.DropoutLayer),
('output', layers.DenseLayer),
],
# input layer
input_shape=(None, 1, 28, 28),
# layer conv2d1
conv2d1_num_filters=32,
conv2d1_filter_size=(5, 5),
conv2d1_nonlinearity=lasagne.nonlinearities.rectify,
conv2d1_W=lasagne.init.GlorotUniform(),
# layer maxpool1
maxpool1_pool_size=(2, 2),
# layer conv2d2
conv2d2_num_filters=32,
conv2d2_filter_size=(5, 5),
conv2d2_nonlinearity=lasagne.nonlinearities.rectify,
# layer maxpool2
maxpool2_pool_size=(2, 2),
# dropout1
dropout1_p=0.5,
# dense
dense_num_units=256,
dense_nonlinearity=lasagne.nonlinearities.rectify,
# dropout2
dropout2_p=0.5,
# output
output_nonlinearity=lasagne.nonlinearities.softmax,
output_num_units=10,
# optimization method params
update=nesterov_momentum,
update_learning_rate=0.01,
update_momentum=0.9,
max_epochs=10,
verbose=1,
)
# Train the network
nn = net1.fit(X_train, y_train)
如你所视,在layers的参数中,我们定义了一个有层名称/类型的元组字典,然后定义了这些层的参数。在这里,我们的体系结构使用的是两个卷积层,两个池化层,一个全连接层(稠密层,dense layer)和一个输出层。在一些层之间也会有dropout层,dropout层是一个正则化矩阵,随机的设置输入值为零来避免过拟合(见下图)。
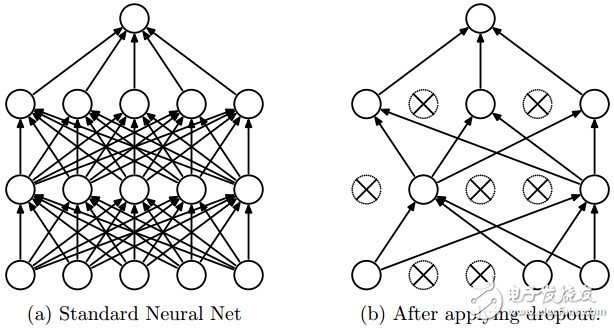
Dropout层效果
调用训练方法后,nolearn包将会显示学习过程的状态,我的机器使用的是低端的的GPU,得到的结果如下:
# Neural Network with 160362 learnable parameters
## Layer information
# name size
--- -------- --------
0 input 1x28x28
1 conv2d1 32x24x24
2 maxpool1 32x12x12
3 conv2d2 32x8x8
4 maxpool2 32x4x4
5 dropout1 32x4x4
6 dense 256
7 dropout2 256
8 output 10
epoch train loss valid loss train/val valid acc dur
------- ------------ ------------ ----------- --------- ---
1 0.85204 0.16707 5.09977 0.95174 33.71s
2 0.27571 0.10732 2.56896 0.96825 33.34s
3 0.20262 0.08567 2.36524 0.97488 33.51s
4 0.16551 0.07695 2.15081 0.97705 33.50s
5 0.14173 0.06803 2.08322 0.98061 34.38s
6 0.12519 0.06067 2.06352 0.98239 34.02s
7 0.11077 0.05532 2.00254 0.98427 33.78s
8 0.10497 0.05771 1.81898 0.98248 34.17s
9 0.09881 0.05159 1.91509 0.98407 33.80s
10 0.09264 0.04958 1.86864 0.98526 33.40s
正如你看到的,最后一次的精度可以达到0.98526,是这10个单元训练中的一个相当不错的性能。
预测和混淆矩阵
现在,我们使用这个模型来预测整个测试集:
preds = net1.predict(X_test)
我们还可以绘制一个混淆矩阵来检查神经网络的分类性能:
cm = confusion_matrix(y_test, preds)
plt.matshow(cm)
plt.title('Confusion matrix')
plt.colorbar()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
上面的代码将绘制下面的混淆矩阵:
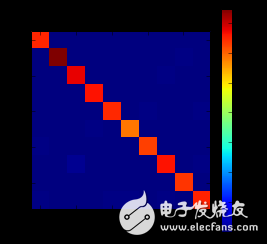
混淆矩阵
如你所视,对角线上的分类更密集,表明我们的分类器有一个良好的性能。
过滤器的可视化
我们还可以从第一个卷积层中可视化32个过滤器:
visualize.plot_conv_weights(net1.layers_['conv2d1'])
上面的代码将绘制下面的过滤器:

第一层的5x5x32过滤器
如你所视,nolearn的plot_conv_weights函数在我们指定的层中绘制出了所有的过滤器。
Theano层的功能和特征提取
现在可以创建theano编译的函数了,它将前馈输入数据输送到结构体系中,甚至是你感兴趣的某一层中。接着,我会得到输出层的函数和输出层前面的稠密层函数。
dense_layer = layers.get_output(net1.layers_['dense'], deterministic=True)
output_layer = layers.get_output(net1.layers_['output'], deterministic=True)
input_var = net1.layers_['input'].input_var
f_output = theano.function([input_var], output_layer)
f_dense = theano.function([input_var], dense_layer)
如你所视,我们现在有两个theano函数,分别是f_output和f_dense(用于输出层和稠密层)。请注意,在这里为了得到这些层,我们使用了一个额外的叫做“deterministic”的参数,这是为了避免dropout层影响我们的前馈操作。
现在,我们可以把实例转换为输入格式,然后输入到theano函数输出层中:
instance = X_test[0][None, :, :]
%timeit -n 500 f_output(instance)
500 loops, best of 3: 858 µs per loop
如你所视,f_output函数平均需要858µs。我们同样可以为这个实例绘制输出层激活值结果:
pred = f_output(instance)
N = pred.shape[1]
plt.bar(range(N), pred.ravel())
上面的代码将绘制出下面的图:
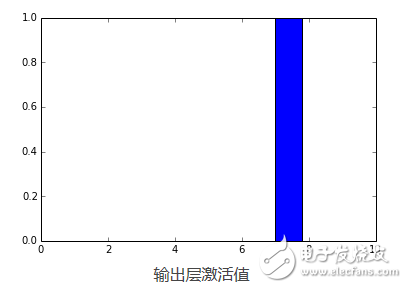
正如你所看到的,数字被认为是7。事实是为任何网络层创建theano函数都是非常有用的,因为你可以创建一个函数(像我们以前一样)得到稠密层(输出层前一个)的激活值,然后你可以使用这些激活值作为特征,并且使用你的神经网络作为特征提取器而不是分类器。现在,让我们为稠密层绘制256个激活单元:
pred = f_dense(instance)
N = pred.shape[1]
plt.bar(range(N), pred.ravel())
上面的代码将绘制下面的图:
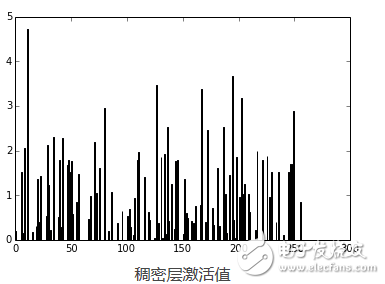
现在,你可以使用输出的这256个激活值作为线性分类器如Logistic回归或支持向量机的特征了。
最后,我希望你会喜欢这个教程。
作者简介:Christian S.Peron,遗传算法框架Pyevolve(基于Python编写的)的作者,现任惠普软件设计师。可通过christian dot perone at gmail dot com 联系。
关于译者: 刘帝伟,中南大学软件学院在读研究生,关注机器学习、数据挖掘及生物信息领域。
-
模拟电路故障诊断中的特征提取方法2016-12-09 5436
-
有大神吗?可以分享一个LabVIEW指纹特征提取的资料吗?2017-04-19 2969
-
基于联合频率分析的特征提取及识别过程2021-04-21 2023
-
基于已知特征项和环境相关量的特征提取算法2009-04-18 942
-
基于DCT和KDA的人脸特征提取新方法2009-05-25 1153
-
模式识别中的特征提取研究2009-12-12 843
-
故障特征提取的方法研究2006-03-11 1969
-
LTE体系结构2009-06-16 10312
-
基于Gabor的特征提取算法在人脸识别中的应用2013-01-22 1382
-
一种去冗余的SIFT特征提取方法2017-12-01 1222
-
无监督行为特征提取算法2017-12-26 2158
-
基于HTM架构的时空特征提取方法2018-01-17 1318
-
液压泵振动信号特征提取方法2018-03-05 1184
-
机器学习之特征提取 VS 特征选择2020-09-14 5012
-
计算机视觉中不同的特征提取方法对比2022-07-11 5226
全部0条评论

快来发表一下你的评论吧 !
