

卷积神经网络训练过程中的SGD的并行化设计
FPGA/ASIC技术
描述
前段时间一直在关注 CNN 的实现,查看了 caffe 的代码以及 convnet2 的代码。目前对单机多卡的内容比较感兴趣,因此特别关注 convnet2 关于 multi-GPU 的支持。
其中 cuda-convnet2 的项目地址发布在:Google Code:cuda-convnet2
关于 multi-GPU 的一篇比较重要的论文就是:One weird trick for parallelizing convolutional neural networks
本文也将针对这篇文章给出分析。
1、简介
介绍一种卷积神经网络训练过程中的SGD的并行化方法。
两个变种
模型并行: 不同的 workers 训练模型的不同 patrs,比较适合神经元活动比较丰富的计算。
数据并行: 不同的 workers 训练不同的数据案例,比较适合 weight 矩阵比较多的计算。
2. 观察
现代卷积神经网络主要由两种层构成,他们具有不一样的属性和性能:
1)卷积层,占据了90% ~ 95% 的计算量,5% 的参数,但是对结果具有很大的表达能力。
2)全连接层,占据了 5% ~ 10% 的计算量, 95% 的参数,但是对于结果具有相对较小的表达的能力。
综上:卷积层计算量大,所需参数系数 W 少,全连接层计算量小,所需参数系数 W 多。因此对于卷积层适合使用数据并行,对于全连接层适合使用模型并行。
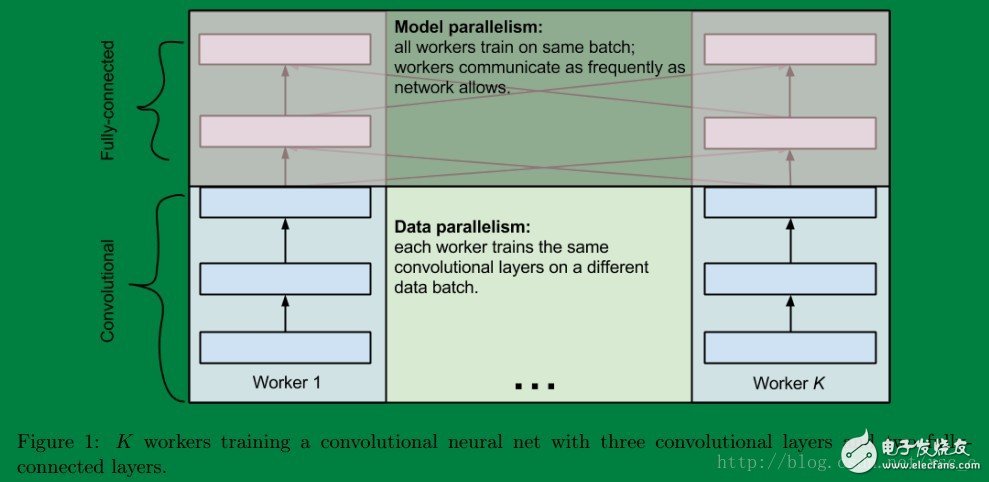
3. 推荐的算法
前向传播
1)K workers 中的每一个 worker 都提供不同的 128 个 examples 的 data batch,也就是每一个 worker 的数据都是不一样的。
2)每一个 worker 都在其 data batch 上计算卷积层。每一个 worker 的卷积层是按照顺序执行的。
3)全连接层的计算,分为以下三种方式:
(a) 每一个 worker 将其最后阶段的卷积层 activities 传递给其他的 worker。这些 workers 将这 128K 个 examples 配置成一个大的 batch,然后在这个 batch 上计算全连接层。
(b) 第一个 worker 将其最后阶段的卷积层 activities 传递给其他 workers,这些 workers 计算 128 个 examples 配置成的 batch 并且开始反向传递。(与这一次计算并行的同时,第二个 worker 将卷积层的 activities 传递到所有的 workers 中,即实现了 activities 传递和计算之间的流水线)。
(c) 全部的 workers 传递 128/K 个卷积层的 activities 到其他的 workers,计算方式同(b)。
对于上述(a~c)三种不同的全连接层实现方式,进行如下的分析:
(a) 当 128K images 配置到每一个 worker 的时候,所有有用的 work 必须要暂停。另外大的 batches 消耗大量的显存,这对于 GPU 显存有限制的设备是不希望发生的。另一方面,大的 batches 有利于 GPU 性能的发挥。
(b) 所有的 workers 轮流将他们的 activities 传播到所有的 workers 上面。这里轮流执行得到的最重要的结果是可以将大部分传播通信时间隐藏(因为他可以在上一次计算的时候,与计算一起并行处理,确切是 K-1 次通信时间可以隐藏)。这样做的意义非常的重大,可以实现一部分流水,使得通信时间隐藏,达到了很好的并行效果。
(c) 与 (b) 的方案类似。他的一个优势就是通信与计算的比例是常数 K,对于 (a) 和 (b),与 K 成比例。这是因为 (a) 和 (b) 方案经常会受到每一个 worker 的输出带宽的限制,方案 (c) 可以利用所有的 workers 来完成这一任务,对于大的 K 会有非常大的优势。
反向传播
1) workers 按照通常的方式在全连接层计算梯度。
2) 按照前向传播中不同的实现方案,这里会有对应的三种方案:
(a) 每一个 worker 都为整个 128K examples 的 batch 计算了 activities 的梯度。所以每一个 worker 必须将每一个 example 的梯度传递给前向传播生成这个 example 的 worker 上面。这之后,卷积层的反向传播按照常规方式获取。
(b) 每一个 worker 已经为 128 examples 的 batch 计算了 activities 的梯度,然后将这些梯度值传递给每一个与这个 batch 相关的 workers 上。(在传播的同时,可以进行下一个 batch 的计算)。在经过 K 次前向和反向的传播,所有的梯度值都将被传播到卷积层。
(c) 与 (b) 类似。每一个 worker 计算了 128 examples batch 的梯度,这 128-example batch 来自于每一个 worker 的 128/K-examples,所以为了正确的分配每一个梯度,需要安装相反的操作来进行。
Weight 权值矩阵同步
一旦反向传播完成之后,workers 就可以更新 weight 矩阵了。在卷积层,workers 也必须同步 weight 矩阵。最简单的方式可以按如下进行:
1) 每一个 worker 指定到梯度矩阵的 1/K 进行同步。
2) 每一个 worker 从其他的 worker 累计对应的 1/K 的梯度。
3)每一个 worker 广播这 1/K 的梯度。
对于卷积层来说,这个比较容易实现,因为它的 weights 系数比较少。
可变的 batch size
对于方案 (b) 和 (c) 在运行同步 128K SGD 的时候相对于方案 (a) 有了一些细微的变动,其中 (a) 是标准的 forward-backward 传播方式。(b) 和 (c) 方案在全连接层执行 K 次 forward 和 backward 过程,每一次执行不同的 128 examples,这就是说,如果我们愿意,我们可以在上面每一次局部的后向传播执行过程结束之后,更新全连接层的系数,这样不会带来任何额外的计算开销。因此,我们可以在全连接层使用 batch size = 128,在卷积层 batch size = 128K。用了这样的可变 batch size 之后,这就不再是一个纯粹的并行 SGD 算法了,因为不再为任何与卷积层一致的模型更新梯度值,但是事实证明,在实践中,这并不重要。在实际中,使用有效的 batch size 从 128K 到数千,在全连接层使用小的 batch size,最后能够更快的收敛到更好的极小值。
案例图示

上图给出了方案 (b) 的 forward 和 backward 传播,其中 K = 2,即 2 个 workers。
在三层结构的卷积层中,两路数据并行的方案被实施。在两层结构的全连接层中,两路模型并行的方案被实施。上图将数据并行和模型并行 2 个过程分解为 6 个过程。
step1:卷积层数据并行实现前向传播(3个卷积层顺序执行,2个 worker 数据并行执行)
step2:阴影部分的卷积层将数据传递给两个全连接层,模型并行实现前向传播(2个全连接层顺序执行,FC11 和 FC12 模型并行执行,FC21 和 FC22 模型并行执行)
step3:全连接层实现反向传播,并将梯度数据传回卷积层
step4:同 step2,worker 2 的卷积层数据传递到全连接层,实现前向传播
step5:同 step3,全连接层实现反向传播,将梯度传回 worker 2 对应的卷积层
step6:完成卷积层的反向传播。
- 相关推荐
- 热点推荐
- cnn
-
在Ubuntu20.04系统中训练神经网络模型的一些经验2025-10-22 324
-
BP神经网络的基本结构和训练过程2024-07-10 10284
-
卷积神经网络训练的是什么2024-07-03 2024
-
卷积神经网络的基本原理、结构及训练过程2024-07-02 5481
-
卷积神经网络(CNN)的工作原理 神经网络的训练过程2023-09-05 3475
-
python卷积神经网络cnn的训练算法2023-08-21 2726
-
卷积神经网络简介:什么是机器学习?2023-02-23 25565
-
卷积神经网络模型发展及应用2022-08-02 13396
-
带Dropout的训练过程2019-08-08 5122
-
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速2018-12-19 3984
全部0条评论

快来发表一下你的评论吧 !
