

训练神经网络的五大算法
FPGA/ASIC技术
描述
神经网络模型的每一类学习过程通常被归纳为一种训练算法。训练的算法有很多,它们的特点和性能各不相同。
问题的抽象
人们把神经网络的学习过程转化为求损失函数f的最小值问题。一般来说,损失函数包括误差项和正则项两部分。误差项衡量神经网络模型在训练数据集上的拟合程度,而正则项则是控制模型的复杂程度,防止出现过拟合现象。
损失函数的函数值由模型的参数(权重值和偏置值)所决定。我们可以把两部分参数合并为一个n维的权重向量,记为w。下图是损失函数f(w)的图示。
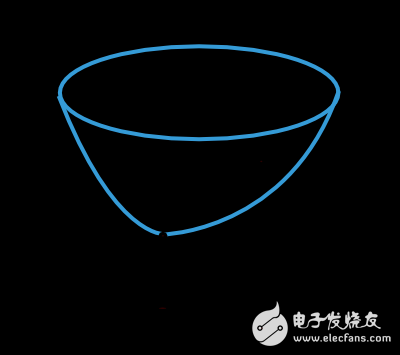
如上图所示,w*是损失函数的最小值。在空间内任意选择一个点A,我们都能计算得到损失函数的一阶、二阶导数。一阶导数可以表示为一个向量:
ᐁif(w) = df/dwi (i = 1,…,n)
同样的,损失函数的二阶导数可以表示为海森矩阵( Hessian Matrix ):
Hi,jf(w) = d2f/dwi·dwj (i,j = 1,…,n)
多变量的连续可微分函数的求解问题一直被人们广泛地研究。许多的传统方法都能被直接用于神经网络模型的求解。
一维优化方法
尽管损失函数的值需要由多个参数决定,但是一维优化方法在这里也非常重要。这些方法常常用于训练神经网络模型。
许多训练算法首先计算得到一个训练的方向d,以及速率η来表示损失值在此方向上的变化,f(η)。下图片展示了这种一维函数。
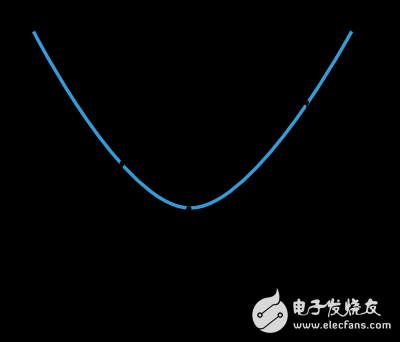
f和η*在η1和η2所在的区间之内。
由此可见,一维优化方法就是寻找到某个给定的一维函数的最小值。黄金分段法和Brent方法就是其中两种广泛应用的算法。这两种算法不断地缩减最小值的范围,直到η1和η2两点之间的距离小于设定的阈值。
多维优化方法
我们把神经网络的学习问题抽象为寻找参数向量w*的问题,使得损失函数f在此点取到最小值。假设我们找到了损失函数的最小值点,那么就认为神经网络函数在此处的梯度等于零。
通常情况下,损失函数属于非线性函数,我们很难用训练算法准确地求得最优解。因此,我们尝试在参数空间内逐步搜索,来寻找最优解。每搜索一步,重新计算神经网络模型的参数,损失值则相应地减小。
我们先随机初始化一组模型参数。接着,每次迭代更新这组参数,损失函数值也随之减小。当某个特定条件或是终止条件得到满足时,整个训练过程即结束。
现在我们就来介绍几种神经网络的最重要训练算法。

1. 梯度下降法(Gradient descent)
梯度下降方法是最简单的训练算法。它仅需要用到梯度向量的信息,因此属于一阶算法。
我们定义f(wi) = fiand ᐁf(wi) = gi。算法起始于W0点,然后在第i步沿着di= -gi方向从wi移到wi+1,反复迭代直到满足终止条件。梯度下降算法的迭代公式为:
wi+1 = wi- di·ηi, i=0,1,…
参数η是学习率。这个参数既可以设置为固定值,也可以用一维优化方法沿着训练的方向逐步更新计算。人们一般倾向于逐步更新计算学习率,但很多软件和工具仍旧使用固定的学习率。
下图是梯度下降训练方法的流程图。如图所示,参数的更新分为两步:第一步计算梯度下降的方向,第二步计算合适的学习率。
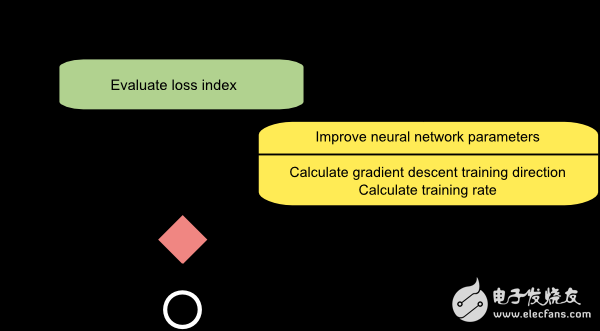
梯度下降方法有一个严重的弊端,若函数的梯度变化如图所示呈现出细长的结构时,该方法需要进行很多次迭代运算。而且,尽管梯度下降的方向就是损失函数值减小最快的方向,但是这并不一定是收敛最快的路径。下图描述了此问题。
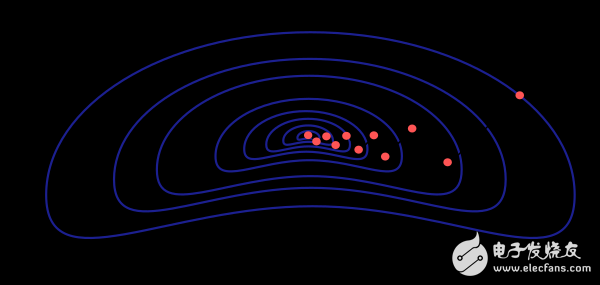
当神经网络模型非常庞大、包含上千个参数时,梯度下降方法是我们推荐的算法。因为此方法仅需要存储梯度向量(n空间),而不需要存储海森矩阵(n2空间)
2.牛顿算法(Newton’s method)
因为牛顿算法用到了海森矩阵,所以它属于二阶算法。此算法的目标是使用损失函数的二阶偏导数寻找更好的学习方向。

下图展示的是牛顿法的流程图。参数的更新也分为两步,计算牛顿训练方向和合适的学习率。
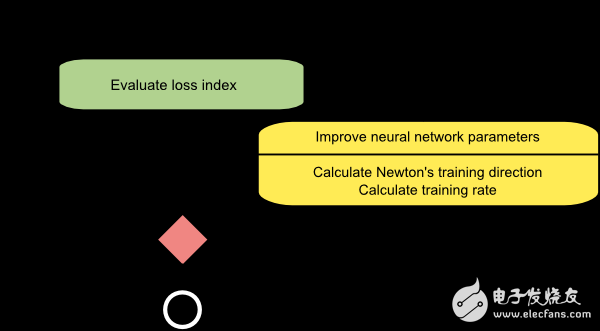
牛顿法的性能如下图所示。从相同的初始值开始寻找损失函数的最小值,它比梯度下降方法需要更少的步骤。
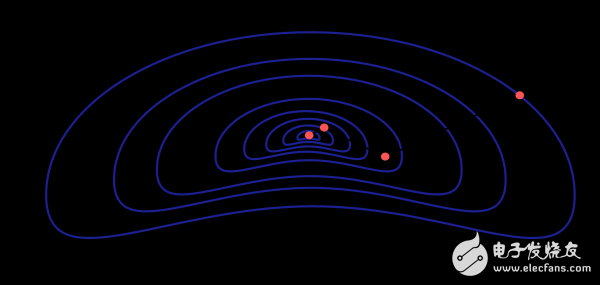
然而,牛顿法的难点在于准确计算海森矩阵和其逆矩阵需要大量的计算资源。
3.共轭梯度法(Conjugate gradient)
共轭梯度法介于梯度下降法与牛顿法之间。它的初衷是解决传统梯度下降法收敛速度太慢的问题。不像牛顿法,共轭梯度法也避免了计算和存储海森矩阵。
共轭梯度法的搜索是沿着共轭方向进行的,通常会比沿着梯度下降法的方向收敛更快。这些训练方向与海森矩阵共轭。
我们将d定义为训练方向向量。然后,将参数向量和训练方向训练分别初始化为w0和d0 = -g0,共轭梯度法的方向更新公式为:
di+1 = gi+1 + di·γi, i=0,1,…
其中γ是共轭参数,计算它的方法有许多种。其中两种常用的方法分别是Fletcher 和 Reeves 以及 *** 和 Ribiere发明的。对于所有的共轭梯度算法,训练方向会被周期性地重置为梯度的负值。
参数的更新方程为:
wi+1 = wi + di·ηi, i=0,1,…
下图是共轭梯度法训练过程的流程图。参数更新的步骤分为计算共轭梯度方向和计算学习率两步。
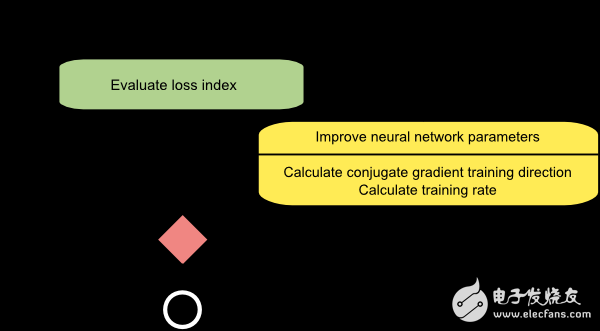
此方法训练神经网络模型的效率被证明比梯度下降法更好。由于共轭梯度法不需要计算海森矩阵,当神经网络模型较大时我们也建议使用。
4. 准牛顿法(Quasi-Newton method)
由于牛顿法需要计算海森矩阵和逆矩阵,需要较多的计算资源,因此出现了一个变种算法,称为准牛顿法,可以弥补计算量大的缺陷。此方法不是直接计算海森矩阵及其逆矩阵,而是在每一次迭代估计计算海森矩阵的逆矩阵,只需要用到损失函数的一阶偏导数。
海森矩阵是由损失函数的二阶偏导数组成。准牛顿法的主要思想是用另一个矩阵G来估计海森矩阵的逆矩阵,只需要损失函数的一阶偏导数。准牛顿法的更新方程可以写为:
wi+1 = wi - (Gi·gi)·ηi, i=0,1,…
学习率η既可以设为固定值,也可以动态调整。海森矩阵逆矩阵的估计G有多种不同类型。两种常用的类型是Davidon–Fletcher–Powell formula (DFP)和Broyden–Fletcher–Goldfarb–Shanno formula (BFGS)。
准牛顿法的流程图如下所示。参数更新的步骤分为计算准牛顿训练方向和计算学习率。
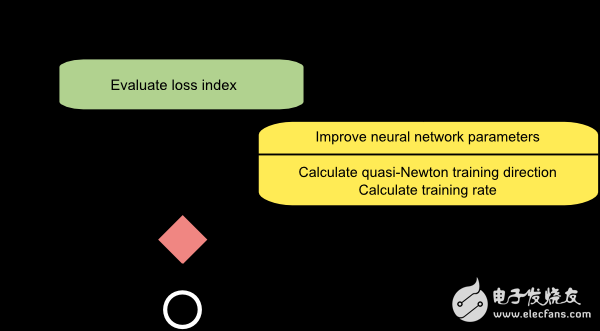
许多情况下,这是默认选择的算法:它比梯度下降法和共轭梯度法更快,而不需要准确计算海森矩阵及其逆矩阵。
5. Levenberg-Marquardt算法
Levenberg-Marquardt算法又称为衰减的最小平方法,它针对损失函数是平方和误差的形式。它也不需要准确计算海森矩阵,需要用到梯度向量和雅各布矩阵。
假设损失函数f是平方和误差的形式:

若衰减因子λ设为0,相当于是牛顿法。若λ设置的非常大,这就相当于是学习率很小的梯度下降法。
参数λ的初始值非常大,因此前几步更新是沿着梯度下降方向的。如果某一步迭代更新失败,则λ扩大一些。否则,λ随着损失值的减小而减小,Levenberg-Marquardt接近牛顿法。这个过程可以加快收敛的速度。
下图是Levenberg-Marquardt算法训练过程的流程图。第一步计算损失值、梯度和近似海森矩阵。然后衰减参数和衰减系数。
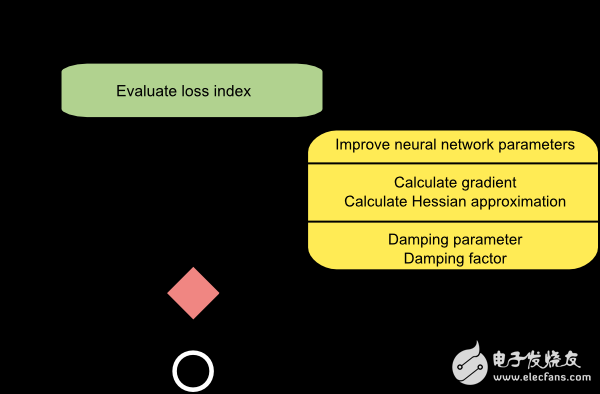
由于Levenberg-Marquardt算法主要针对平方和误差类的损失函数。因此,在训练这类误差的神经网络模型时速度非常快。但是这个算法也有一些缺点。首先,它不适用于其它类型的损失函数。而且,它也不兼容正则项。最后,如果训练数据和网络模型非常大,雅各布矩阵也会变得很大,需要很多内存。因此,当训练数据或是模型很大时,我们并不建议使用Levenberg-Marquardt算法。
内存使用和速度的比较
下图绘制了本文讨论的五种算法的计算速度和内存需求。如图所示,梯度下降法往往是最慢的训练方法,它所需要的内存也往往最少。相反,速度最快的算法一般是Levenberg-Marquardt,但需要的内存也更多。柯西-牛顿法较好地平衡了两者。
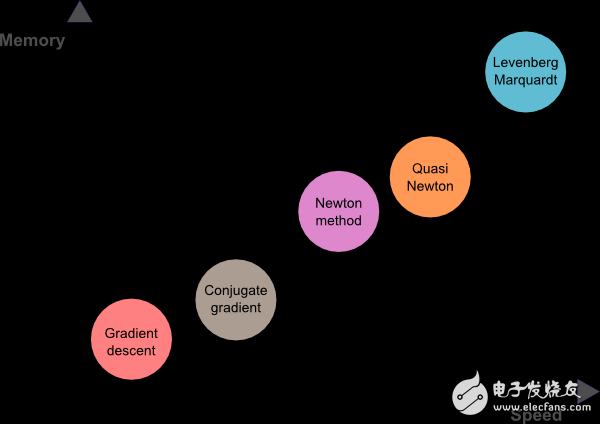
总之,如果我们的神经网络模型有上千个参数,则可以用节省存储的梯度下降法和共轭梯度法。如果我们需要训练很多网络模型,每个模型只有几千个训练数据和几百个参数,则Levenberg-Marquardt可能会是一个好选择。其余情况下,柯西-牛顿法的效果都不错。
-
在Ubuntu20.04系统中训练神经网络模型的一些经验2025-10-22 306
-
人工神经网络原理及下载2008-06-19 9911
-
神经网络教程(李亚非)2012-03-20 58154
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 3391
-
反馈神经网络算法是什么2020-04-28 2956
-
基于光学芯片的神经网络训练解析,不看肯定后悔2021-06-21 3041
-
用S3C2440训练神经网络算法2021-08-17 1922
-
优化神经网络训练方法有哪些?2022-09-06 1750
-
如何进行高效的时序图神经网络的训练2022-09-28 3200
-
基于自适应果蝇算法的神经网络结构训练2017-01-03 835
-
BP神经网络概述2018-06-19 45496
-
如何训练和优化神经网络2024-07-01 1820
-
BP神经网络算法的基本流程包括2024-07-03 1867
-
如何利用Matlab进行神经网络训练2024-07-08 5192
-
怎么对神经网络重新训练2024-07-11 1560
全部0条评论

快来发表一下你的评论吧 !
