

神经语言学中的卷积神经网络
FPGA/ASIC技术
描述
当人们提到卷积神经网络(CNN), 大部分是关于计算机视觉的问题。卷积神经网络确实帮助图像分类以及计算机视觉系统核心取得了重要突破,例如Facebook自动照片加tag的功能啊,自动驾驶车辆等。
近年来,我们也尝试用CNN去解决神经语言学(NLP)中的问题,并且获得了一些有趣的结果。理解CNN在NLP中的作用比较困难,但是它在计算机视觉中的作用就更容易理解一些,所以呢,在本文中我们先从计算机视觉的角度出发谈一谈CNN,慢慢再过渡到NLP的问题中去~
什么是卷积神经网络
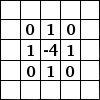
对我来说,最容易理解卷积的办法是把它理解成一个滑动的窗口函数,就像是一个矩阵一样。虽然很拗口,但是看起来很直观(如下图,自行领悟):
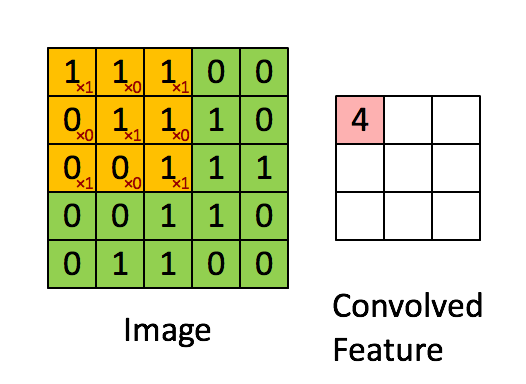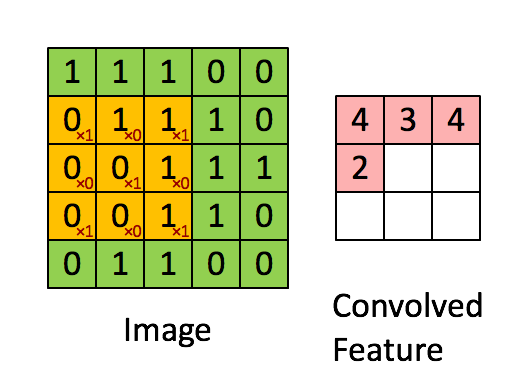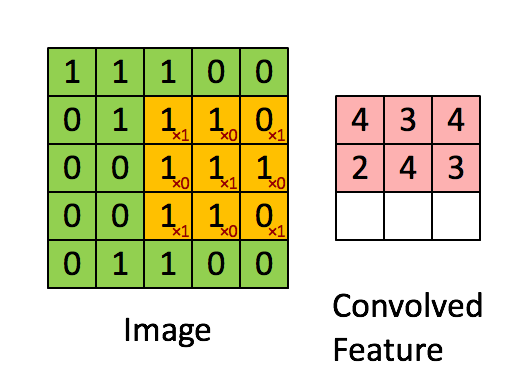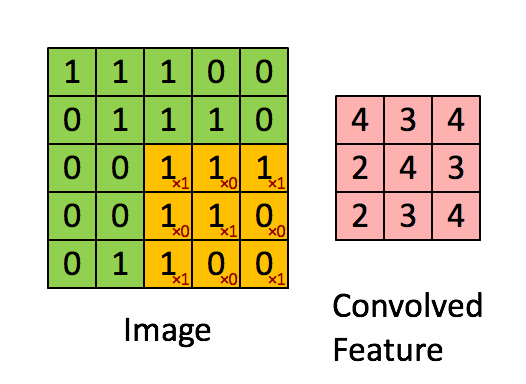
Convolution with 3×3 Filter. Source:
让我们发挥想象力,左边的矩阵代表一个黑白图像。每个方格对应一个像素,0表示黑色,1表示白色(通常来说,计算机视觉处理的图像是一个灰度值在0到255之间的灰度图)。滑动的窗口被称为一个(卷积)内核、过滤器(译者:有那么点滤波器的感觉)或者特征检测器(译者:用于特征提取)。
现在,我们用一个3×3的过滤器,将它的值与原矩阵中的值相乘,然后求和。为了得到右边的矩阵,我们需要将在完整的矩阵中每一个3×3子矩阵做一次操作。
你可能在想这种操作有什么作用,下面有两个例子
模糊处理
让像素与周围像素值平均后,图像发生模糊。
(译者:类似于将周围几个像素的数值平摊一下)

边缘检测
对像素与周围像素值做差后,边界就变得显著了。
为了更好地理解这个问题,先想想在一个像素变化平滑连续的图像上,一块像素点和周围的几个像素点相同的时候,会发生什么:那些因相互比较产生的增量就会消失,每个像素的最终值将会是0,也就是黑色。(译者:猜是没有对比度了)。如果那有很强的有着明显色差的边界,例如从白色到黑色的图像边界,那你就会得到明显的反差,从而得到白色。
这个 GIMP manual 网址有更多的例子。(译者:如锐化啊、边缘加强之类的,还有一个似乎是可以这样做卷积修图的软件)。如果想了解得更多的话,建议你们看看这个 Chris Olah’s post on the topic.
什么是卷积神经网络
你现在已经知道了什么是卷积了,那么什么是卷积神经网络呢?简单说来,CNN就是用好几层使用非线性激活函数(如,ReLu,tanh)的卷积得到答案的神经网络。
在传统的前馈神经网络中,我们将每一层的每个输出和下一层的每个输入相互连接,这也被称为完全连接层或仿射层。但是CNN中并不是这样。相反,我们使用卷积在输入层中计算输出(译者:卷积造成部分映射,参见之前的卷积图),这就导致了局部连接,一个输出值连接到部分的输入(译者:利用层间局部空间相关性将相邻每一层的神经元节点只与和它相近的上层神经元节点连接)。
每一层都需要不同的过滤器(通常是成千上万的),就类似上文提到的那样,然后将它们的结果合并起来。那还有一个叫做池(pooling layer)或者下采样层(subsampling layers)的东西,之后再说吧。
在训练阶段中,CNN能够通过训练集自动改善过滤器中的参数值。举个例子,在图像分类问题中,CNN能够在第一层时,用原始像素中识别出边界,然后在第二层用边缘去检测简单的形状,然后再用这些形状来识别高级的图像,如人脸形状啊,房子啊(译者:特征提取后可以通过特征分辨图像)。最后一层就是用高级的图像来进行分类。

在计算方面有两个值得注意的东西:局部不变性(Location Invariance)和组合性(Compositionality)。
假设你要辨别图像上有木有大象,进行一次二分类(就是分成有大象和没有大象的两种)。
咱们的过滤器将扫描整个图像,所以并不用太在意大象到底在哪儿。在现实中,pooling也使得你的图像在平移、旋转、缩放的时候保持不变(后者的情况更多些)。
组合性(局部组合性),每个过滤器获取了低层次的图片的一部分,组合起来成了高层次图片。
这就是为什么CNN在计算机视觉上表现地如此给力。在从像素建边,从边到确立形状,从形状建立更加复杂的物体过程中,CNN会给人一个直观的感受。
CNN在NLP中的用途
相比于图像与像素,大多数的NLP问题的输入是句子或者文档构成的矩阵。矩阵的每一行一般来说是一个单词,也可以是一个字符(如,字符)。所以呢,每一行就是表示一个单词的向量。通常每一个向量是一个放弃词向量word embeddings(低纬度的表示方法),例如word2vec or GloVe, 它们也可以是one-hot vectors 用于表示单词。对于一个10个词的句子,用一个100维的embedding表示,我们就有10×100的矩阵作为我们的输出,这就是我们的“图像”。
在这样看来,我们的过滤器在一个图像的小块像素上滑动,但是在NLP问题上,我们用过滤器在矩阵的每一个完整的行上面滑动(就是一个单词)。所以呢,过滤器的宽度一般和输入矩阵的宽度相同。高度、区域大小一般各有不同,但是一般都是一次读2-5个单词。
将上面说的全部联系起来,那么一个用于NLP问题的CNN就是酱紫的(花点时间,试着理解下面这张图,想想每一维度是怎么被计算的,目前可以忽略池pooling,过会儿再说):
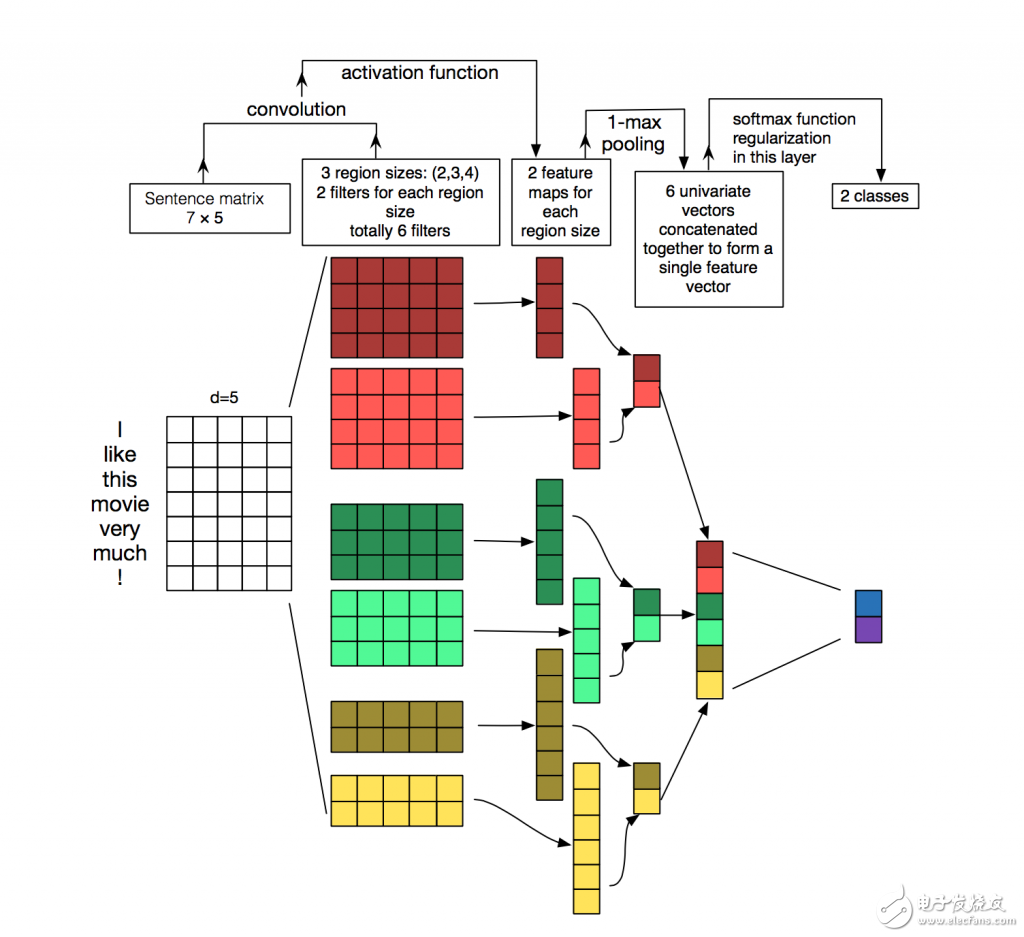
用于句子分类的卷积神经网络结构图。
我们有三种过滤器,它们的高度分别为: 2,3, 4,每种过滤器共两个。每个过滤器在句子矩阵里进行卷积并且产生一个长短不一的特征映射(feature maps),然后一个1-max pooling在每个映射上运行,每个特征映射的最大数值都被记录下来。因此,一个单变量特征向量由所有六个映射生成,这6个特征被级联以形成用于倒数第二层的特征向量。 最后的 Softmax层就以输入的形式接收到这些特征向量,然后用它来进行句子分类;这里我们假设二分类,也就是描述两个可能的输出状态。
Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
那我们能不能拥有像计算机视觉那样的直观感受呢?局部不变性(Location Invariance)和局部组合性(local Compositionally,译者:我猜是mac自动更换造成的书写错误)产生了对于图像处理的直观感受,但是这些对于NLP问题来说并不是特别直观。你可能更加注意一个单词出现在句子中的哪一个位置。(这里有一个疑问,因为后文说了,并不在意它在哪个位置,而是在意它有没有出现过)
相互靠近的像素非常可能有‘语义’上面的联系,比如可能是一个物体的一个部分,但是对于一个单词而言,上述的规律并不是总是对的。在大部分的语言中,一个词组可以被分成几个孤立的部分。
同样的,组合的特性也不是特别的明显。我们知道,单词之间肯定有特定的组合规律,才能相互连接,就像形容词用来修饰名词一样,但是这些规则究竟怎么运转,更高层次的表达究竟意味着什么,都不是像在计算机视觉中那样明显,那样直观。
在这样的情况下,CNN看上去并不是特别适合用于NLP问题的处理。然而,RNN就能够给你更加直观的感受啦。它们象征着我们如何组织语言(或者,最少也是我们脑海中怎么组织语言):从左到右依次读。幸运的是, 这并不代表CNN没用。所有的模型都有错误,但是并不代表着它们没用用。恰好,实际应用证明了CNN对于解决NLP问题相当不错。简单的词袋模型Bag of Words model是一个基于错误假设的过简单化模型,但是还是被当做标准方法这么多年,并且取得了不错的成绩。
一个对于CNN的争议就是在于他们的速度,他们快,非常快。卷积是计算机图形的核心部分,并在GPU上的硬件级别上实现(你可以想象这有多快了吧)。相比于类似N-Grams之类的东西, CNN在单词或者分类的表示方面效率极高。在处理大量的词汇时,快速运算超出3-Grams的数据开销巨大。甚至连Google都不可以计算超过5-Grams的数据。但是卷积过滤器可以自动学习到一种很好的表达方式,而不用多余地去表示所有的词汇。因此,它完全可以拥有一个大小大于5的过滤器。我想啊,在第一层中设计这么多自动学习的过滤器,它们提取特征的行为很像(但不局限于)N-Grams的方式,但是却用一个更加简洁有效的方法表示它们。
CNN 的超参(HYPER-PARAMETERS)
在解释CNN是如何作用于NLP问题之前,我们先看看在建立CNN的时候需要做哪些选择。希望这会帮助你更好地理解这一领域的文献。
宽、窄卷积神经网络
当我在上文中解释卷积的时候,我忽略了一点运用过滤器的小细节。我们在一个矩阵的中心有3×3的过滤器工作得很棒,但是它在边界的表现如何呢?你应该如何应用这个过滤器于矩阵的第一个元素(没有任何相邻的上方元素和左边元素)? 你可以用0来填充边界。所有超过矩阵边界的元素都当做0来处理。这么做之后呢,你就可以将过滤器用于矩阵中的每一个元素,并且获得更大的等大小的输出。使用0填充的(zero-padding)也称为宽卷积(wide convolution),不用0填充称为窄神经网络。下面是一个例子。

步长(Stride size)
另一个卷积的超参是步长,也就是每一步你想移动你的过滤器多少距离。上述的所有的例子,步长均为1。对连续应用过滤器采样子矩阵,就会导致采样信息的重叠。一个更大的步长意味着更少地使用过滤器和更小的输出。下面的例子来自于the Stanford cs231 website 展示了步长为1和步长为2运用于一维输入的情况:

Convolution Stride Size.
Left: Stride size 1. Right: Stride size 2. Source:
在文献中我们通常看到的都是步长大小为1的情景,但是较大的步幅让你建立一个处理过程类似RNN的模型,就像树型结构。
池层(POOLING LAYERS)
卷积神经网络的另一个关键在于Pooling layers,它通常在卷积层后面使用。Pooling layers用于下采样上一层的输入。最简单也是最常见的做法是,取每个过滤器中的最大值为输出。你不必对一个完整的矩阵都做pooling操作,你可以对一个小窗口做pooling。如下图,展示一个在2×2窗口的max pooling操作(在NLP问题中,我们通常要对整个输入进行pooling操作,产生每个过滤器产生一个单独的数字输出):

Max pooling in CNN. Source:
为什么要进行Pooling操作呢?有以下这么几个原因。
Pooling操作的一个优势在于它能够产生一个固定大小的输出矩阵。这个矩阵通常被用于分类。例如,如果你有1000个过滤器并且你对每一个过滤器都进行了Max Pooling操作,那么你就得到了1000维的输出。不管你过滤器的大小,也不管你输入的大小,你的输出大小就是固定的。这样你就可以用各种各样长度的句子和各种各样大小的过滤器,但是总会得到相同的输出维度,从而进行分类。
Pooling的使用也可以减少输出的维度,同时(我们希望这样)保存最显著的信息。你可以想象一下,每个过滤器能够识别出一种特征,例如,识别出这个句子有没有含有一个类似”not amazing”的否定词。如果句子中的某个地方出现了这个词组,那么扫描采样这一块的过滤器就会产生一个大的数值,在别的区域产生一个小的值。这样做之后呢,你就能够保持那些关于某些特征有没有出现在句子中的信息,而损失了这个特征究竟出现在句子的哪个位置的信息。但是,损失的这个信息并没有什么用途吧?对啊,这是有一点像a bag of n-grams model所做的那样。你损失了关于定位的全局信息(某些东西出现在句子中的某些地方),但是你保留下来了被你的过滤器采样到的局部信息,就像”not amazing”与”amazing not”非常不同一样。(这就是我上文说的一个有疑问的说法)
在图像识别中,Pooling也可以提供基础的平移、旋转不变性。当你对于某个区域进行Pooling操作的时候,结果通常来说会保持一致,无论你是旋转还是平移你图像的像素,因为Max Pooling会最终识别出同样的数值。
通道(CHANNELS)
我们需要理解的最后一个理论是通道。通道是输入数据的一种不同的‘样子’。例如,在图像识别中,我们一般使用的是RGB(red, green, blue) 通道。在通道里应用卷积的时候,你可以采用不同的或者相同的权值。在NLP问题中,你可以想到通道的种类是非常多的:用不同的word embeddings(word2vec and GloVe for example)来区分通道,或者,你可以为不同的语言表达的同样意思的句子、单词设计一个通道。
用于NLP的CNN
现在让我们看看一些CNN在自然语言处理中的应用。我会尝试总结一些研究成果与结论。总之,我会漏了描述很多有趣的应用(请在评论中告诉我),但我希望至少覆盖一些比较流行的结果。
CNN天生就适合用于分类任务,例如情感分析,垃圾邮件检测或主题分类。卷积和池操作会丢失单词的局部顺序,所以呢,句子标记,例如词性标注或实体提取,是有点难以适应纯CNN架构(也不是不可能,你可以添加位置特征的输入)。
[1] 评估一个CNN结构在各种分类数据集中的表现,主要包括情感分析和主题分类的任务。 CNN结构跨数据集的问题上有着非常不错的表现,同时最新的技术也使得它在小数据上表现优异。 出人意料的是,论文中使用的网络是非常简单的,这就是为什么它非常的有效。输入层是一个由连续的word2vec word embeddings组成的句子。在卷积层的后面跟着多个过滤器,然后是一个max-pooling layer,最后是一个softmax分类器。该论文也对两个不同的通道做实验,通道是以静态和动态word embeddings形式的,并且其中一个能够在训练中被调整,一个不能被调整。一个相似的但是更加复杂的结构在[2]中被提出。[6] 加入了一个新增的层用于在网络结构中进行“语义聚合”(semantic clustering) 。

[4]从头训练一个CNN,不需要pre-trained word向量,例如word2vec或者GloVe。它直接将卷积用于one-hot向量。作者还提出了一种空间节约的bag-of-words似的输入数据表示方法 ,减少了网络需要训练的参数个数。在[5]中,作者用一个二外的无监督“region embedding”扩展了这个模型,该扩展是学习用CNN来预测文本区域的内容。这些论文中使用的方法似乎在长文本(例如,电影评论)的处理中做得不错,但是他们在短文本(例如,微博)中的处理效果还不得而知。直观地来看,这确实很有道理。对短文本使用pre-trained word embeddings将会产生更大的收益,相比将它们用于处理长文本。
建立一个CNN解耦狗意味着许多超参可供选择,就像我上文提到的那样:输入表示法(word2vec, GloVe, one-hot),卷积过滤器的数量和大小,池操作的策略(max, average),以及激活函数(ReLU, tanh)。[7]通过调整CNN结构的超参,多次运行程序,研究、分析其的性能和方差,从而得出验证性的评价。如果你想要将你的CNN用于文本分类,用这篇论文的结论作为基础起始点是再好不过的了。一些脱颖而出的结论是,max-pooling的效果总是好于average_pooling;一个理想状况下的过滤器大小是很重要的,但是大部分还是依具体情况而定;正则化与否在NLP问题中似乎没有多大影响。这项研究的需要注意的是,在文件长度方面,所有的数据集都颇为相似。所以呢,同样的准则看清了并不适用于那些看起来相当不同的数据。
[8]研究了CNN对关系抽取和关系分类的应用。除了单词向量,作者用了单词与关注的实体(译者:attention mechanism里的概念)之间的相对位置作为卷积层的另一个输入。这个模型假定实体的位置已经被给定,并且各实例的输入包含一个上述的关系。[9]和[10]也研究的是同样的模型。
在微软的[11]和[12]研究中,能够发现一个CNN在NLP中有趣的应用。这些论文描述的是如果得知那些可以被用于信息检索的句子的语义上有意义的表示方法。论文中的例子包括,根据读者现在阅读的文章,推荐出读者可能感兴趣的文章。句子的表示方法是用基于搜索引擎的日志数据来进行训练的。
大多数的CNN结构以用这种或者那种方式从embeddings (低维表示法) 中学习作为它们训练过程的一部分。并非所有的论文都关注于如果训练或者研究分析learned embeddings意义何在。[13]展示了一个CNN结构。这个结构用于预测Facebook的位置标签,同时,产生有意义的单词和句子的embeddings。这些learned embeddings随后被成功地用于其他的问题: 以点击流数据作为训练集,将用户可能产生潜在兴趣的文章推荐给用户。
字符级CNN(CHARACTER-LEVEL CNNS)
这个专业名词翻译是我自己猜的,也可能是汉字、个性之类的。
目前为止,所有模型的表示方法都是基于单词的。但是也有将CNN应用于字符的研究。 [14] 研究了character-level embeddings,将它们和pre-trained word embeddings结合在一起,并且将CNN用于词性标注 (Part of Speech tagging). [15][16] 研究了直接用CNN从字符中进行训练,不需要接住任何的pre-trained embeddings。值得注意的是,作者用了一个共9层的深度神经网络,并将其用于情感分析和文本分类的作用。结果表明,在大数据的情况下,直接从字符级输入的学习效果非常好(百万级的例子),但是在较小的数据集上面表现得比较差(百条、千条例子)。 [17] 研究了字符级CNN在语言模型(Language Modeling)上面的应用,用字符级CNN的输出作为LSTM(长期短期记忆单元)的输入。同样的模型可以用于多个语言。
最让人惊奇的是上面所说的所以论文都是在最近的1-2年内发表的。非常明显的,CNN在NLP问题上面很早就取得了很好的成绩,。虽然自然语言处理(几乎)是刚刚开始起步,但是新成果和新技术的发展步伐正在显著加快。
[1] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
[2] Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. Acl, 655–665.
[3] Santos, C. N. dos, & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING-2014 (pp. 69–78).
[4] Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015, (2011).
[5] Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding.
[6] Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.
[7] Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,
[8] Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48.
[9] Sun, Y., Lin, L., Tang, D., Yang, N., Ji, Z., & Wang, X. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (Ijcai), 1333–1339.
[10] Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344.
[11] Gao, J., Pantel, P., Gamon, M., He, X., & Deng, L. (2014). Modeling Interestingness with Deep Neural Networks.
[12] Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. (2014). A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management – CIKM ’14, 101–110.
[13] Weston, J., & Adams, K. (2014). # T AG S PACE : Semantic Embeddings from Hashtags, 1822–1827.
[14] Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826.
[15] Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.
[16] Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102.
[17] Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2015). Character-Aware Neural Language Models.
-
卷积神经网络的原理与实现2024-07-02 2058
-
卷积神经网络的应用 卷积神经网络通常用来处理什么2023-08-21 6668
-
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法2023-08-17 2589
-
卷积神经网络模型发展及应用2022-08-02 13372
-
卷积神经网络一维卷积的处理过程2021-12-23 2070
-
卷积神经网络的优点是什么2020-05-05 3637
-
什么是图卷积神经网络?2019-08-20 2411
-
卷积神经网络如何使用2019-07-17 2877
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 6016
全部0条评论

快来发表一下你的评论吧 !
