

基于SDAccelTM 开发环境减少FPGA在应用中使用时造成的障碍
FPGA/ASIC技术
描述
赛灵思SDAccel 环境能在FPGA 上提供类似CPU的开发与运行时间体验,减轻数据中心设计负担。
从支持中小机构运作的服务机房,到支持美国大型企业和提供云计算服务接入的企业级数据中心,数据中心在现代经济中发挥着骨干作用。根据自然资源保护委员会的统计,数据中心是美国用电量最大、增长最快的用电大户之一。2013 年美国数据中心估计耗电约910亿千瓦时,超过纽约市全部居民用电的两倍以上,而且到2020 年用电量有望达到1400 亿千瓦时[1]。很明显,降低用电对于扩展数据中心,提升可靠性和降低运营成本具有重要意义。
根据具体的服务器应用,数据中心各个不同。许多服务器长期不间断运行,使得硬件可靠性和耐用性极为重要。虽然服务器可以使用商用计算机部件组装,但关键任务型企业级服务器往往使用以硬件加速为目的的专用硬件,如图形处理单元(GPU)和数字信号处理器(DSP)。现在许多企业寻求使用现场可编程门阵列(FPGA),因为FPGA 是一种高度并行的架构,而且功耗相对较低。赛灵思的新款SDAccelTM 开发环境为开发人员提供了一种熟悉的CPU 或类似CPU 的环境,避免编程给FPGA 在此类应用中使用时造成的障碍。
提升性能功耗比
Amazon We b 服务、Google Compute、Microsoft Azure 和中国的百度等公有云(public cloud)拥有巨大的图片库,需要极快的图像识别能力。在一个实现方案中,谷歌科技人员将16000 个计算机处理器连接为一个实体,创建出了一个极为庞大的机器学习神经网络,然后投放到互联网上,让其自主学习。这项研究是新一代计算机科学的代表。这一代计算机科学以充分利用大型数据中心中的大量计算机集群的运算能力为目标。潜在应用包括让图像搜索、语音识别和机器语言翻译能力迈上新的台阶。但是对数据中心设计而言,仅依靠充分利用CPU 并非是一种高能效的做法。要提高速度、降低功耗,还需要其他解决方案。
中国最大的搜索引擎百度借助于深度神经网络处理技术来解决语音识别、图像搜索和自然语言处理方面的问题。百度迅速判定,如果在在线预测中使用神经网络反向传播算法,FPGA 解决方案在降低功耗的同时,还能以比CPU/GPU 简便得多的方式进行扩展[2]。
因在数据中心服务器的主机卡和线路卡中集成了FPGA,新一代28nm和20nm 高集成度FPGA 系列(如赛灵思7 系列和UltraScaleTM 器件)正在改变数据中心动态发展状况。性能功耗比可以轻松达到CPU/GPU 的20倍以上,同时在某些应用中与传统CPU 相比,时延可降低50 至75倍。
但是对FPGA 硬件资源有限或缺乏的开发团队而言,由于需要使用RTL(VHDL 或Verilog)开发专业知识才能充分发挥FPGA 的性能优势,因此过渡到FPGA 难度较大。为解决这一问题,赛灵思已引入开放计算机语音(OpenCLTM)作为减轻编程负担的方法。
OpenCL代码移植性
由苹果公司开发并经Khronos 集团推广的OpenCL [3] 有助于异构设计中的CPU、GPU、FPGA 和DSP 模块集成。为增强用于编写可在异构平台上运行的程序的OpenCL 框架,赛灵思等业界领先的CPU、GPU 和FPGA厂商都在为这种语音及其API 的开发做出努力。
OpenCL 被CPU/GPU/FPGA 厂商、服务器OEM 厂商以及数据中心管理人员等日益广泛地接受,说明各方都已经认识到一个严峻的现实:用于单处理器架构的C 语言编译器在服务器机架内部只能实现小幅总体功耗降低,即便是在处理器采用低于20nm 的工艺技术并添加特殊省电状态后依然如此。
OpenCL 是一种用于编写可在由CPU、GPU、DSP、FPGA 及其它处理器构成的异构平台上运行的程序的框架。OpenCL 包含基于C99 的编程语言和应用编程接口(API),以控制平台和在目标器件上执行程序。OpenCL 使用基于任务和基于数据的并行机制提供并行计算功能。
SDAccel编译器相对CPU性能提高10倍,且功耗仅为GPU的1/10。
针对OpenCL的赛灵思SDAccel开发环境
在开发特定领域规格描述环境方面,赛灵思有近十年的工作经验。数据中心管理人员和服务器/ 交换机OEM厂商对数据中心性能的担忧,迫使开发环境向统一环境方向纵向发展,以在数据中心应用中实现设计优化。在此情况下,一种用于应用加速的OpenCL 开发环境— SDAccelTM — 应运而生。
最新赛灵思SDAccel 环境(如图1 所示)为数据中心应用开发人员提供完整的基于FPGA 的硬件和OpenCL 软件。SDAccel 内含一个快速且架构优化编译器,能高效利用片上FPGA 资源以及用于代码开发、特性分析和调试的基于Eclipse 集成设计环境(IDE)的熟悉软件开发流程。该IDE 可提供类似CPU/GPU 的工作环境。
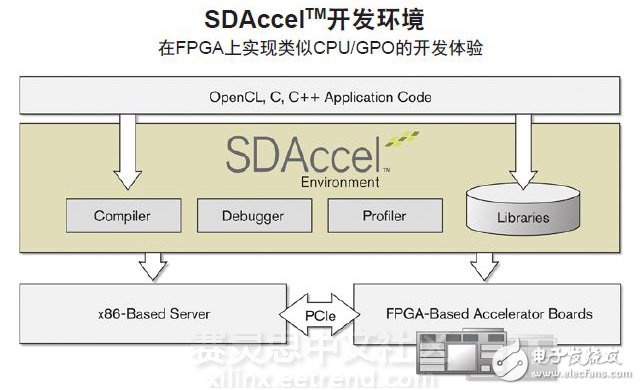
图1 - SDAccel环境包含架构优化编译器、库、调试器和分析器,可提供类似CPU/GPU的编程体验。
此外,SDAccel 运用赛灵思的动态可重配置技术,可提供针对将即时换入换出的不同应用优化的加速器内核。这些应用能够在运行时间内将多个内核换入或换出FPGA,且不会给服务器CPU 和用于持续应用加速的FPGA 之间的接口造成扰动。
SDAccel 架构优化的编译器支持软件开发人员优化和编译流、低延迟定制数据路径应用。SDAccel 编译器支持使用C、C++ 和OpenCL 任意组合的源代码,主要面向赛灵思高性能FPGA 器件。SDAccel 编译器与高端CPU 相比,性能提升10 倍,功耗仅为GPU 的1/10,同时保持代码兼容性和传统软件编程模式,便于应用移植并有助于降低成本。
SDAccel 是唯一基于FPGA 的开发环境,内含各种用于应用加速并针对FPGA 优化的库。该库包含OpenCL 内置函数、任意精度数据类型(定点)、浮点、math.h、视频、信号处理和线性代数函数。
在诸如带有复杂嵌套数据路径(nested datapath) 的视频处理等实际计算工作负载上,FPGA 架构的内在灵活性使其相对于CPU 和GPU 固定架构而言,在性能和功耗方面具有明显的优势。如图2 中所示的基准测试结果表明,SDAccel 编译的FPGA 解决方案在性能上超过相同代码的CPU 实现方案,并提供可与GPU 实现方案相媲美的卓越性能。
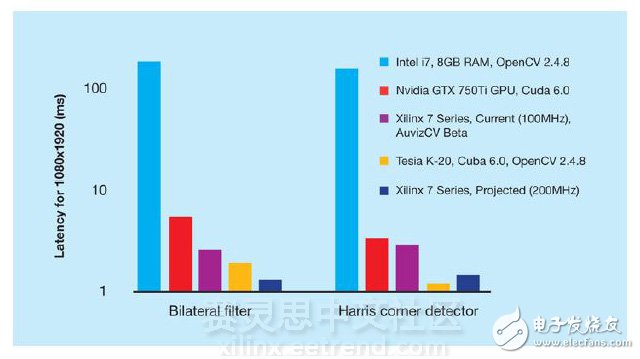
图2 – 运用OpenCL语言为CPU、GPU和FPGA架构编写的视频处理算法在FPGA上运行速度更快(Auviz使用AuvizCV库完成的基准测试)
双边滤波器和Harris 角点检测器均使用标准的OpenCL 设计模式编码,使用器件的全局存储器在内核之间传输数据。SDAccel 生成的FPGA实现方案通过创建片上存储器组供高带宽存储器传输和低时延计算使用,可达到优化存储器访问的目的。创建和使用这些专用存储器组代表SDAccel 编译器的部分架构感知功能。
软件工作流
FPGA 一直有望超越CPU 和GPU 实现方案,拥有更高的算法性能以及更低的功耗范围。但直到现在因为编程模式未能如愿以偿。而这一编程模式又是有效利用FPGA 所必须的。SDAccel 支持具备系统内即时可重配置功能的软件工作流,能最大化数据中心的硬件加速ROI,从而克服这一障碍。SDAccel 是一种独特而完整的基于FPGA 的解决方案,它的功能和简便易用性远远超越了竞争对手的工具。
-
如何使用FPGA开发板编程出更高级的应用2019-03-20 5150
-
在赛灵思FPGA中使用ARM及AMBA总线2012-03-01 6992
-
FPGA开发的完整的流程及开发过程中使用到的开发工具有哪些?2021-04-29 1891
-
在FPGA内部中使用单时钟FIOF2021-12-17 659
-
系统开发者指南--在测试与量测环境中使用USB应用手册2010-07-23 841
-
在视频监控系统中使用FPGA进行视频处理2010-09-22 717
-
在嵌入式系统中使用FPGA时的常见问题及对策2012-10-17 1398
-
SDx环境能让人集中精力优化FPGA布局和性能并能实现更高的系统效率2017-11-17 3687
-
FPGA开发流程详细解析2018-01-12 10850
-
FPGA/CPLD开发环境及开发板实验2018-03-16 814
-
如何在MPLAB XC8集成开发环境中使用编译器的详细概述2018-06-07 2528
-
连接器在不同环境下的影响2023-11-17 1271
-
在生产线或应用时,造成EOS破坏的原因2023-12-29 2952
-
在生产线或应用时,造成EOS破坏的原因?2024-01-24 2359
-
采用精密多路复用器减少工业环境中的测量障碍2024-09-11 299
全部0条评论

快来发表一下你的评论吧 !
