

用Vivado HLS高阶合成重构算法设计有效处理管道
FPGA/ASIC技术
描述
目前的应用软件通常包含有复杂的内存访问机制,尤其是在科学计算和数字信号处理领域,内存的管理将十分复杂。我们利用Vivado HLS设计了一个简单的例子,可以使你在一些棘手的情况下,用它来建造有效处理管道。
HLS试图在由高级语言描述的控制数据流图(CDFG)中获取平。运算操作以及存储访问的分派与设计是根据他们与目标平台的紧缺资源间的独立性决定的。对于许多引人关注的算法来说,数据存取依赖于计算结果,内存占用需要使用芯片外RAM。如今,在内核上使用HLS会创造出数据通路以及许多指令级的并行。但是当它被激活,且等待输入数据时,它需要频繁停止。
下图展示了当数据设置过大,且需要不断放到单片高速缓冲存储器上时,为实验效果而制造的硬件模块的运行效果。值得注意的是速度的减慢对所有cache失效潜在因素组合的影响。然而这不是必须的,因为有一部分计算图的发展是不需要立即使用内存数据的。这个环节需要被快速推进。这种在调度执行的额外自由有很多潜在的影响。
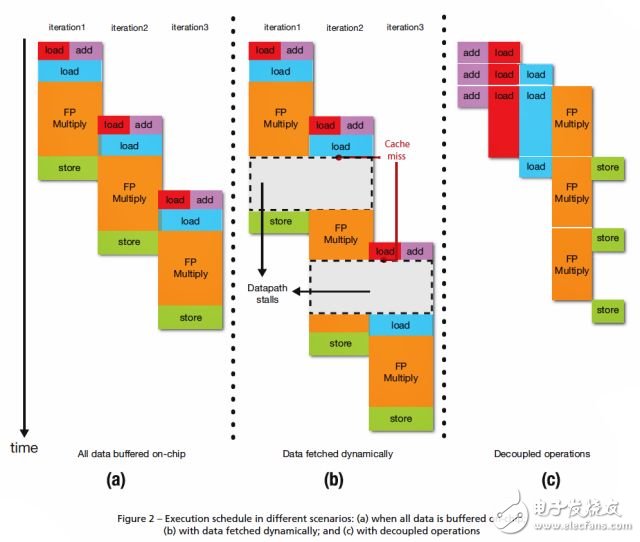
图2(c)展示了使用解耦处理管道时的调度执行。双FIFO的潜在影响忽略不计,但当迭代次数非常大时,应将其影响减到最小。
为生产解耦处理模型管道,首先你需要在原控制数据流图(CDFG)中聚集信息来完成子图。为了使结果的效果最大化,聚类方法应符合多数要求。
第一,如之前所说,Vivado HLS 运用软件流水技术在其前一次结束之前激发新的迭代次数。最长周期的潜在因素依赖于CDFG规定了最小间距,这些间距可以使新的迭代次数开始,并能限定且增加最终生产量。因此,这些循环依赖不穿过多重子图是很重要的,就像双FIFO应用于模块之间的通讯总是会增加潜在因素。
其次,将存储操作与包含有延长计算的循环依赖分开是有益处的,这样一来,cache失效能够被慢速率的数据消费遮盖。这里,延长计算指的是运算要进行多于一个周期且满足我们的目标,Vivado HLS时间表就是用来获取这个度量标准的。例如,延长操作是复杂的,而整数模块运算则不是。
最后,为了集中那些由高速缓存缺失引起的摊位影响,你也会想要减小在每个子图里面存储操作的数量,尤其是当他们记录在存储空间的不同部分的时候。
满足第一个要求-不让循环依赖穿过多子图其实很简单,方法是:在原数据流程图中寻找到强连通分量,并且在他们分散为不同集群之前使他们碰撞成节点。这个步骤结束后,我们得到了一张有向非循环图,上面有一些有简单指令的节点,其他的有一些彼此依赖的操作。为了满足第二和第三个要求--分离存储操作和局部化摊位影响—我们可以使节点拓扑排序并将他们分离开。
我们我们制作了一个简单的源到源变换工具来完成这项重组,我们用Xilinx IP 核来制作双FIFO个体链接模型。重构计算模型的方式有很多种,而且设计空间的探索仍然在前进。
- 相关推荐
- 热点推荐
- Vivado
-
Vivado HLS设计流的相关资料分享2021-11-11 1146
-
探索Vivado HLS设计流,Vivado HLS高层次综合设计2020-12-21 4686
-
合成中的Vivado HLS中的Pragma错误怎么解决2020-05-21 2951
-
vivado hls axi接口问题2020-04-21 2306
-
怎么在Vivado HLS中生成IP核?2020-03-24 3934
-
请问Vivado HLS不会合成这个特殊声明吗?2019-11-05 1691
-
关于Vivado HLS错误理解2019-07-29 6378
-
如何使用Tcl命令语言让Vivado HLS运作2018-11-20 3866
-
用Vivado-HLS为软件提速2018-03-26 791
-
用Vivado-HLS实现低latency 除法器2017-12-04 1863
-
基于Vivado HLS平台来评估压缩算法2017-11-17 1927
-
Hackaday读者有话说:Vivado HLS使用经验分享2017-02-08 924
-
新手求助,HLS实现opencv算法加速的IP在vivado的使用2017-01-16 6038
全部0条评论

快来发表一下你的评论吧 !
