

基于Virtex-6 的Aurora 8B/10B,PCIe2.0,SRIO 2.0三种串行通信协议分析
FPGA/ASIC技术
描述
摘要:在高性能雷达信号处理机研制中,高速串行总线正逐步取代并行总线。业界广泛使用的Xilinx公司Virtex-6系列FPGA支持多种高速串行通信协议,本文针对其中较为常用的Aurora 8B/10B和PCI Express 2.0,Serial RapidIO 2.0三种协议进行了测试及对比分析。首先搭建了基于Virtex-6 FPGA的高速串行协议测试平台;然后设计并分别实现了三种协议的高速数据通信,测算了协议的实际传输速率;最后结合测试结果,从协议层次结构、链路数目、链路线速率、数据传输方式、协议开销、拓扑结构、设备寻址方式、应用领域等方面对三种协议进行了比较。本文研究工作可为三种协议的选用、测试和工程实现提供参考。
1 引言
随着雷达带宽和AD采样率的提高,在高性能雷达信号处理机研制中,系统对数据传输带宽的要求不断增加,高速串行总线正逐步取代传统的并行总线。
Xilinx公司推出的Virtex-6系列FPGA,在片上集成了固化的GTX模块,以提供高速串行通信支持。同时Xilinx公司提供有多种串行通信协议IP核,便于用户进行开发。Aurora 8B/10B,PCI Express 2.0和Serial RapidIO 2.0是其中较为常用的三种协议。目前已有众多文献涉及到三种协议基于FPGA的实现方案[2][3][4]。然而这些方案未能充分发挥协议性能,存在线速率较低(仅为2.5Gb/s)或未实现多通道绑定。针对上述问题,本文基于Virtex-6 FPGA,分别实现了三种协议在4x链路,5.0Gb/s线速率模式下的数据通信,测得协议的实际传输速率,并对三种协议的特点与应用进行了对比分析。
2 测试平台简介
本文以实验室自行开发设计的PCIe光纤接收处理板(以下简称测试电路板)为测试平台。测试电路板的结构图和实物图分别如图1,图2所示。其中,FPGA选用XC6VLX240T-2FF1156,该芯片含20个GTX收发器,链路线速率可达6.6Gb/s。DSP选用TMS320C6678,该芯片含有SRIO接口,支持1x、2x和4x链路。光电转换模块选用FCBG410QB1C10,它包含4条链路,带宽可达40Gb/s。故而测试电路板的硬件设计符合本测试对数据传输速率的要求。
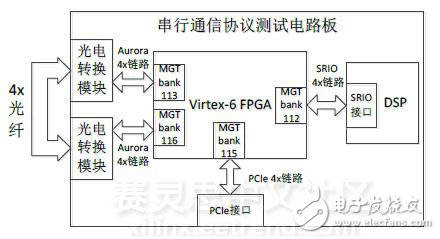
图1 测试电路板模块结构和链路连接图
如图3所示,将测试电路板插入服务器主板的PCIe插槽中,并将光纤接入测试电路板,完成测试平台的搭建。本测试中,PCI Express 2.0协议用于实现FPGA与服务器的数据通信,Serial RapidIO 2.0协议用于实现FPGA与DSP的数据通信,Aurora 8B/10B协议用于实现FPGA的光纤自发自收通信。由于三种协议都在物理层进行8B/10B编码,故在本测试工作模式下,它们的极限速率均为。

3 AURORA 8B/10B通信测试
Aurora 8B/10B协议是Xilinx公司针对高速传输开发的一种可裁剪的轻量级链路层协议,通过一条或多条串行链路实现两设备间的数据传输。协议Aurora协议可以支持流和帧两种数据传输模式,以及全双工、单工等数据通信方式[5]。
本测试中,Aurora 8B/10B IP核配置为双工、流模式,参考时钟频率250MHz。
使用ChipScope软件观察FPGA相关信号如图4所示。观察RX_SRC_RDY_N可以发现,平均每4992周期出现7个周期的数据无效信号。由于接收数据时钟频率为250MHz,数据位宽为64bit,故本测试中,Aurora 8B/10B协议单向传输速率为:
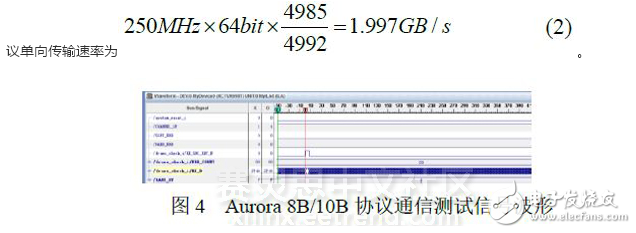
下面分析协议理论传输速率和实际通信效率。该协议的帧格式比较简单,除2字节的起始标志,2字节终止标志和至多1字节的填装字符外,其余为数据部分。本测试采用的流模式是以无结尾的帧方式实现。故协议除8B/10B编码外,基本上不存在其他开销。故根据(1)式可得,协议的理论速率为2.0GB/s,协议的实际通信效率为99.75%。
4 PCI Express 2.0通信测试
PCI Express(简称PCIe)总线技术是取代PCI的第三代I/O技术。PCIe采用串行点对点互连,允许每个设备拥有专属的一条连接,不争夺带宽资源,同时保证了数据的完整性。PCI Express 2.0协议的链路线速率达到5Gb/s,最高支持32x链路。
本测试中,PCIe 2.0通信测试通过FPGA对服务器内存的DMA读/写操作来实现。
服务器方面,本测试选用Windriver软件进行PCIe驱动程序的开发。利用该软件提供的PCIe驱动程序及用户接口函数,编写符合本测试功能需求的程序。
FPGA方面,本测试通过设计用户模块,实现对PCIe IP核的控制,完成DMA读/写操作。FPGA模块结构如图5所示。
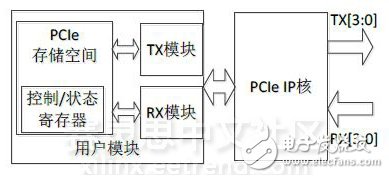
图5 PCIe 2.0通信测试FPGA模块结构
为便于服务器对测试电路板FPGA进行控制,在FPGA的PCIe存储空间模块中,定义了若干控制/状态寄存器,这些寄存器的作用有:DMA读/写初始化,控制DMA读/写的启动与停止,标志一次DMA传输是否完成,设置一次DMA传输的数据量等。
服务器通过PCIe接口对测试板FPGA控制/状态寄存器进行读/写操作,来控制DMA的进程。每次DMA完成后,处理板FPGA会向服务器CPU发送一次中断。服务器对测试电路板FPGA DMA传输的控制流程如图6所示。

图6 PCIe 2.0 DMA传输控制流程图
本测试将TLP包载荷数设为256Bytes(IP核允许的最大值),每次DMA传输的TLP包的数量为16384,故每次DMA传输的数据量为4MB。使用ChipScope软件观察FPGA内部的PCIe 2.0 DMA读/写相关信号,如图7,图8所示。本测试开发了PCIe读写功能测试软件,实现PCIe传输数据量和传输速率的实时显示。传输速率通过1s内DMA传输完成的次数来计算。测试结果如图9(a)、(b)所示。PCIe 2.0 DMA读的数据传输速率为1.770GB/s,DMA写的数据传输速率为1.820GB/s。
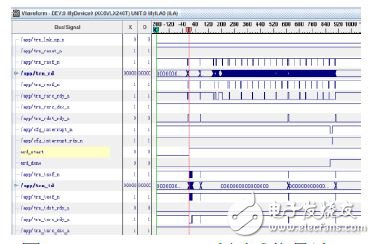
图7 PCIe 2.0 DMA读测试信号波形
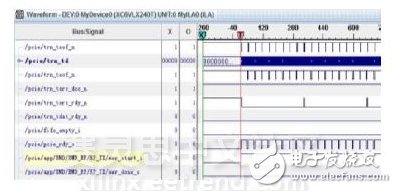
图8 PCIe 2.0 DMA写测试信号波形

图9 PCIe 2.0 DMA读写速率测试结果
下面分析并计算本测试条件下PCIe 2.0 DMA读/写的理论传输速率和实际通信效率。
PCIe 2.0协议主要开销为8B/10B编码开销和数据包传送开销[6]。PCIe总线以包的形式在不同器件之间交换信息。数据在进入处理层后会被封装一个包头,该包头长度在32bit地址下为12字节(本测试采用32bit地址)。当数据包进入数据链路层后,会添加2字节的序列号和4字节的LCRC字段。数据包进入物理层后,使用1字节的开始字符和1字节的结束字符将其封装成帧。
在DMA写测试中,FPGA每发送一次存储器写报文(含256字节数据)会带来20字节的额外开销。在DMA读测试中,FPGA向服务器发送存储器读报文,并由服务器返回完成报文(含256字节数据)。每返回一次完成报文会带来20字节的额外开销。由于PCIe 2.0定义了流量控制缓存管理机制,允许服务器返回完成报文的同时接收FPGA发来的存储器读报文,故DMA读测试中可忽略FPGA发送存储器读报文带来的开销。
故PCIe 2.0 DMA读/写的理论速率相同,均为

5 Serial RapidIO 2.0通信测试
RapidIO是针对嵌入式系统芯片间和板间互连而设计的一种开放式的基于包交换的高速串行标准,已在电信、国防等行业大量使用。
Serial RapidIO(简称SRIO)是物理层采用串行差分模拟信号传输的RapidIO标准。SRIO 2.0协议性能进一步增强,链路线速率可达6.25Gb/s,在电气层支持热插拔,并新添了控制符号和空闲模式功能。
本测试以测试电路板FPGA作为发起端,以测试电路板DSP作为目标端。通过FPGA向DSP发送SWRITE包,进行SRIO 2.0写测试,通过FPGA向DSP发送NREAD包,DSP向FPGA返回RESPONSE包,进行SRIO 2.0读测试。
FPGA模块结构如图10所示。通过VIO控制模块,可对包事务类型、包载荷、发送地址等参数进行设置。本测试将包载荷设为256字节,读/写内存空间设为DSP的MSM(Multi-core Shared Memory)空间。
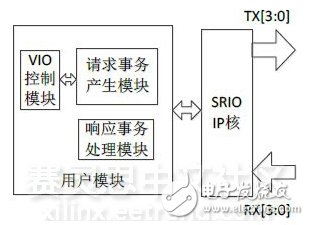
图10 SRIO 2.0通信测试FPGA模块结构
DSP方面,需要进行相关寄存器的配置,完成SRIO的初始化,使DSP作为目标端处理FPGA发来的SRIO读/写请求。DSP主要配置流程包括使能SRIO接口,串并转换模块,链路数目,链路线速率,设备ID等参数的设置。
使用ChipScope软件观察FPGA相关信号,如图11,图12所示。

图11 SRIO 2.0读测试信号波形
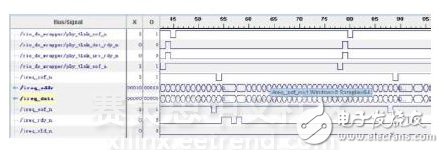
图12 SRIO 2.0写测试信号波形
本测试中,FPGA每连续发送16384个SWRITE或NREAD包后,都会向DSP再发送1个门铃消息。因此,可以通过计算DSP收到的相邻两个门铃的时间间隔来计算SRIO读/写速率。
经测算,当FPGA执行SRIO读/写操作时, DSP接收的相邻两个门铃的平均时间间隔为分别为2.490ms,2.266ms。故SRIO 2.0读操作的数据传输速率为,

下面计算本测试条件下SRIO读/写的理论数据传输速率和实际通信效率。
SRIO 2.0协议的主要开销为物理层编码开销和数据包开销。本测试采用8位路由和34位偏移地址。该条件下SWRITE事务、RESPONSE事务的数据包结构分别如图13、图14所示。
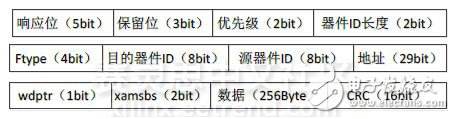
图13 SRIO 2.0 SWRITE包结构
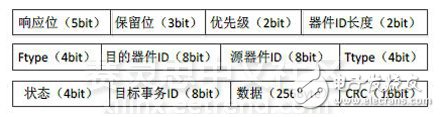
图14 SRIO 2.0 RESPONSE包结构
由图13可知,FPGA每发送一个SWRITE包,会带来10字节的开销,另外,DSP会返回一个4字节确认接收符号。故本测试中SRIO写操作的理论数据传输速率为,

6 三种协议的分析比较
本测试中,Aurora 8B/10B、PCIe 2.0、SRIO 2.0均实现了在4x模式下的高速数据传输。下面将结合测试结果和协议的具体内容,从以下各方面对三种协议进行比较。
(1)协议分层结构
Aurora 8B/10B协议仅定义了链路层和物理层。属于较为底层的协议。SRIO 2.0协议定义了物理层,传输层和逻辑层,PCIe 2.0协议定义了物理层,数据链路层,事务层和软件层,这两种协议的内容和功能均比Aurora 8B/10B协议复杂。
(2)链路数目和链路线速率
Aurora 8B/10B协议在链路数目和链路线速率选择上比较灵活,链路数目可以在1x至16x之间自由选择,链路线速率可以在0.5Gb/s到6.6Gb/s间自由选择。PCIe 2.0支持1x,2x,4x,8x,12x,16x,32x链路,链路线速率支持2.5Gb/s和5.0Gb/s。SRIO 2.0支持1x、2x、4x、8x和16x链路,链路线速率支持1.25Gb/s、2.5Gb/s、3.125Gb/s、5.0Gb/s和6.25Gb/s。
综上可知,在链路线速率选择范围的广泛性和灵活性上,
Aurora 8B/10B>Srio 2.0>Pcie 2.0,
链路数目选择的灵活性上,
Aurora 8B/10B>Pcie 2.0>Srio 2.0。
最大允许的链路数目上,
Pcie 2.0>Aurora 8B/10B=Srio 2.0。
(3)数据传输方式
Aurora 8B/10B协议在数据封装过程中未添加地址,设备号等信息,不能对目标设备的存储空间进行读写。
PCIe 2.0可通过Memory Write,Memory Read,I/O Write,I/O Read事务对目标设备地址空间进行读写,但必须具备对目标设备地址空间的可见性。
SRIO 2.0数据传输方式更为灵活。在具备对目标设备地址空间可见性的情况下,可通过NWRITE,NWRITE_R,SWRITE,NREAD,ASTOMIC等事务对目标设备的地址空间进行直接读写。在不具备目标设备地址空间可见性的情况下,SRIO还提供了消息传递机制。用户将数据和信箱号通过MESSAGE事务发至目标设备,目标设备根据信箱号与自身存储空间的映射关系将数据写入存储空间。
综上可知,数据传输方式的灵活性上,SRIO 2.0>PCIe 2.0>Aurora 8B/10B。
(4)协议开销和数据传输速率
三种协议均在物理层有20%的8B/10B编码开销。Aurora 8B/10B协议除此之外基本上无其它开销,而PCIe 2.0,SRIO 2.0还存在数据包开销。与PCIe 2.0相比,SRIO 2.0的数据包格式更为简洁,在相同的包载荷大小下,开销更低。以256B包载荷为例,SRIO 2.0的数据包开销最低为5.4%(SWRITE事务),而PCIe 2.0的数据包开销最低为7.3%(Memory Write事务)。然而,PCIe 2.0协议最大允许的包载荷为4KB,而SRIO最大允许的包载荷为256B。故PCIe 2.0协议可通过增大包载荷来达到更低的数据包开销。(4KB包载荷下,PCIe 2.0的数据包开销为0.5%)
协议的理论传输速率由通道带宽和协议开销决定,而协议的实际传输速率还受设备本身性能的影响。本测试中, PCIe 2.0 DMA读操作数据传输速率速率高于SRIO 2.0 NREAD的主要原因是服务器对FPGA的PCIe读请求的响应要快于DSP对FPGA的SRIO读请求响应。
(5)设备寻址
PCIe协议中,各设备共享一个PCIe地址空间。整个PCIe地址空间先被分成块,根据后来的下级总线这些块再进一步划分。树形结构中的每个设备在整个地址空间映射中被指定一个地址空间,通过执行全部地址译码来查找设备。在支持带有大容量存储器的设备系统中,这种设备寻址机制不适合灵活拓展。
SRIO采用基于设备ID寻址的方案[8]。采用该方案,使得拓扑结构的变化仅需要更新事务路径中的设备,从而使系统的拓展与拓扑结构的更改比PCIe协议更为灵活。
Aurora 8B/10B协议未定义设备寻址机制。
(6)网络拓扑
PCIe规定了生成树拓扑结构,这种结构适合于单个主机,多个外围设备通信模式,但限制了端点数量,且不支持任意节点与节点间直接通信。PCIe的典型网络拓扑结构如图15所示[9]。
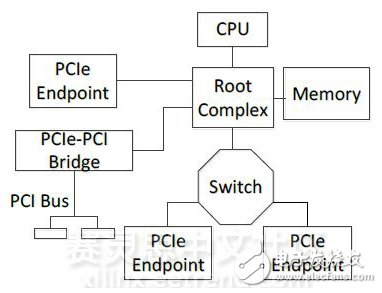
图15 PCIe网络拓扑结构
SRIO的拓扑结构比PCIe更为灵活,可设计成网型,星型,雏菊链或树形拓扑结构,支持节点对节点通信,各节点间可对等的发起数据传输。
Aurora 8B/10B协议不支持网络拓扑结构。
(7)应用领域
Aurora 8B/10B协议作为Xilinx公司开发的轻量级链路层协议,协议开销小,链路数目和链路线速率选择灵活,适用于两片Xilinx FPGA之间的数据流传输。用户也可在其基础上开发高层协议。但其应用范围较为有限,尚未见在其他芯片中使用。
PCIe 2.0作为PCI总线的继承,带宽,拓展灵活性大大提高,适合于主机与外部设备的互联,在PC/Server平台、VPX平台有广泛应用,如声卡、显示卡、网络设备(包括以太网、Modem)、光纤接口卡、磁盘阵列卡等。
SRIO 2.0作为一种高性能包交换的互连技术,数据传输方式和拓扑结构灵活,为多处理器系统的实现提供便利,广泛用于嵌入式系统内的微处理器、DSP、通信和网络处理器、系统存储器之间的高速数据传输。
7 结束语
本文基于Virtex-6 FPGA芯片,对Aurora 8B/10B,PCIe2.0,SRIO 2.0三种串行通信协议进行了速率测试,并通过分析协议开销和协议的流控制机制,计算了三种协议的理论传输速率和协议实际通信效率。结合测试结果和三种协议的具体内容,对三种协议的相关参数和应用领域进行了对比分析。本文测试模块结构的设计可为三种协议的工程实现提供借鉴,协议实际传输速率的测算和协议理论传输速率的分析计算可为三种协议在不同平台和工作模式下的测试提供参考。在进行雷达信号处理机数据传输方案的设计时,可参照本文对三种协议的性能分析,根据系统自身的特点及对数据传输速率的要求,合理选择协议类型和协议的工作模式。
-
USB3.0与USB2.0编码方式的区别2011-11-22 10485
-
USB3.0中8b/10b编解码器的设计2011-11-30 4320
-
Aurora 8b/10b IP核问题2015-03-09 8219
-
8b/10b编解码的控制字问题2019-01-02 3888
-
请问virtex-6 FPGA是否有SRIO引脚,哪个引脚可以配置为SRIO?2020-06-14 1368
-
如何通过HTG-V6-PCIExpress板控制的赛普拉斯USB 2.0访问Virtex-6 FPGA2020-07-08 2082
-
如何使用Aurora 8B / 10B建立仅传输?2020-08-14 3937
-
怎么禁用Aurora IP Core 8B / 10B中的时钟补偿功能?2020-08-18 2053
-
高速接口8B/10B的作用?2022-01-18 1309
-
基于FPGA的8B/10B编解码设计2011-05-26 4483
-
基于PRBS的8B/10B编码器误码率为0设计2017-11-06 2140
-
高速串行通信常用的编码方式-8b/10b编码/解码解析2021-09-26 11587
-
Aurora 8B/10B IP核(一)—Aurora概述及数据接口2022-02-16 11661
-
一文详解8b/10b编码2022-11-12 18492
-
Xilinx FPGA串行通信协议介绍2025-11-14 3063
全部0条评论

快来发表一下你的评论吧 !
