

FPGA编程时的一些实际问题阐述及解决方案详解
编程语言及工具
描述
问题:
随着NI的FPGA产品的广泛使用,很多同事和客户都碰到了一些FPGA编程时遇到的问题。由于FPGA不能实时调试,每次修改一点代码之后都要编译很长时间之后才能看到修改的效果,所以,我们希望尽量在FPGA编写代码时就将更多的问题考虑到位。本文针对项目过程中碰到的一些实际问题进行阐述,希望可以为大家在FPGA编程过程中提供一些帮助。
项目描述:该项目是一个实时频谱监测、流盘以及跳频信号检测的需求。具体参数是IQ速率为100MHz,流盘5分钟(要做类似Reference Trigger的效果,即按下按钮之前的一分钟和按下按钮之后的四分钟信号一起流盘),检测跳频信号的时间点和相应的频点,其中跳频信号的参数是:突发性,每次持续1ms~20ms,跳频信号在每个频点上的持续时间是1us~20us,跳频频率70000/s,每个频点上的信号带宽是5MHz;使用的硬件是5792+7966.其中与FPGA相关的部分就是数据采集和跳频信号的检测。对于数据采集部分,5792有专门的采集范例可以供大家参考,而跳频信号的检测算法是将数据每隔128个点做一次FFT(100M的采样率,对于1us的跳频信号持续时间,对应为100个时域采样点)。做出的FFT结果如果超过阈值,则将FFT结果的序号回传给上位机进行保存。
解答:
一、DMA传输的速率
对于PXIe-7966R,官网上标定的DMA的传输速率为800MB/s,理论上可以完全满足项目中的400MB/s的传输速率要求。但实际测试过程中,传输的速率接近但总是达不到400MB,这直接影响了信号的实时采集和流盘。经了解,FPGA的DMA BenchMark与FIFO的数据位宽、总线带宽以及DMA控制器的速率都有一定关系。见下图:
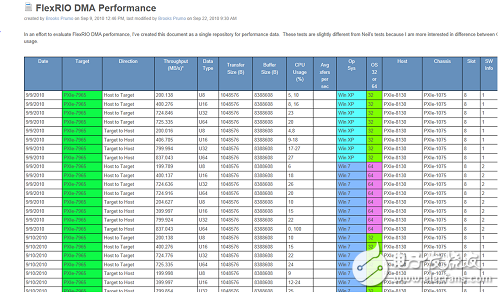
注:上图中PXIe系统下,FPGA的时钟使用的是200MHz的时钟。而PXI系统下,FPGA的时钟使用的是160M (U8 和U16),133M(U32和U64)。
注:上图中使用的机箱是PXIe-1075,使用的控制器是PXIe-8130.
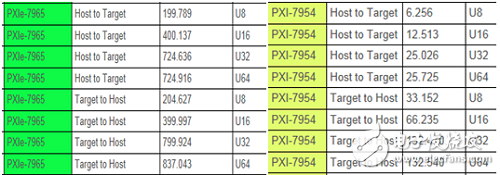
通过观察上述PXIe和PXI板卡的速率统计,可以看到:
对于PXI板卡,在 U8场景下,FPGA每秒钟产生160MB的数据,U16场景下FPGA每秒产生320MB的数据。众所周知,PCI总线的传输带宽为133MB/s,那为什么上图中U8情况下的速率才33MB/s,U16情况下的速率才66MB/s呢?这是因为PCI总线的传输模式是并行传输,总线位宽和时钟频谱分别是32位和33M(一般的desktop都是这样的配置),也就是说每个时钟周期传输32个比特的数据。因此,如果传输的是U8或者U16的数据类型,那么相当于每个传输周期浪费了3/4或者1/2的位宽。因此,U8情况下每次只能传输一个字节,结合33MHz的时钟频率,使得DMA 的Benchmark只有33MB/s。U16的情况下的DMA速率为66M也是可以理解的。而U32以及U64的情况下,只能达到133M的极限速率。
对于PXIe板卡,FPGA读写 FIFO的时钟固定为200MHz,因此,如果FIFO的数据类型是U8,那么每秒钟FPGA端就产生200MB的数据;如果FIFO的数据类型是U16,那么每秒钟FPGA端就产生400MB的数据量。这些数据量远小于1075机箱的单槽带宽(PCIe Gen 1 ×4,1GB/s),因此,总的DMA Benchmark 就等于FPGA端产生数据的速率。如果FIFO的数据类型为U32,那么FPGA产生数据的速率就达到了800MB,这几乎1075机箱的单槽传输极限,因此U32场景下DMA的BenchMark接近800MB/s。继续增加FPGA端FIFO的位宽,在200MHz的时钟频率下FPGA每秒钟产生1.6GB的数据,但这时PCIe总线的传输速率不可能再大幅提升,因此,U64情况下DMA的Benchmark 还是在800MB左右,所以我们很容易得出DMA的传输速率限制为总线的单槽传输带宽。
实测1085+8135环境下的DMA速率
为了验证此种情况(U64,200M时钟)下DMA的传输速率限制确实为总线的单槽传输带宽,我们有理由假设,如果使用1085机箱(单槽传输速率为4GB/s),DMA的传输速率应该可以达到1.6GB/s。因此,我又搭建了相关的系统对1085机箱下的7966 DMA速率进行测试:
硬件环境:PXIe-8135+PXIe-1085+PXIe-7966
测试方法:在7966中以200M的时钟不断将U64数据写入到FIFO中,FIFO大小2048;上位机中对FIFO进行全速读取(缓冲区中有多少点读多少点),上位机缓冲区设置为200M;
测试结果:DMA速率900MB/s左右.修改上位机中FIFO的缓冲区大小,DMA速率没有出现大的波动,依然在900MB/s。观察CPU占用率在18~20%,每次循环查看缓冲区中的点数10000点不到,说明上位机的读取速率完全不是瓶颈。
分析结果可以发现:此时系统总线的单槽带宽已经不是限制因素,上位机的读取速率也完全可以跟上。DMA传输链路上的瓶颈,除了FPGA产生数据的速率、总线传输带宽、上位机的读取速率之外,还有一点是我们之前没有考虑到的——就是DMA控制器的速率。在我们实际测试的这种场景下,DMA控制器的速率成了DMA链路传输速率受限的主要原因。这个结果与官网上说7966的DMA传输速率为800MB/s以上是相互吻合的。
总结:
i) PXI总线的带宽比较低,目前支持PXI总线的FlexRIO只有较老的795x系列,这种情况下限制DMA传输速率的主要是总线带宽;
ii) PXIe 总线的带宽比较高,不同机箱的单槽传输带宽各有不同,因此,对DMA传输速率上限有一定的影响;
iii) FPGA端在一定的时钟频率下,如果希望提升数据率,可以使用更宽的数据位宽;
iv) DMA控制器的速率是板卡本身硬件上对DMA速率的限制——7966的DMA速率为800M以上,7975的DMA速率可以达到1.6GB/s;
当然, DMA的传输性能的影响因素,比如上下行的影响。上图中给出的数据中,对于7965的上下行DMA速率相差不大,但对于7954的上下行DMA速率相差很大。对于这一点,还需要更加深入地研究。本文不再深入讨论。
二、 FPGA与上位机的握手
FPGA中FIFO的使用使得FPGA端和上位机端在很多时候都可以异步操作。上位机中没有有效的数据传递到FPGA端,FPGA端就不会进行有效的计算并传输无效的数据。但在有些情况下,FPGA端与上位机端需要进行握手的操作。比如:一个项目需要通过Adapter端口进行数据采集,然后将数据传回到上位机。这种情况下,如果FPGA先于上位机开始执行,那么FPGA采集到的端口数据会迅速地填满FIFO(此时上位机还没有准备好去读取FIFO的数据)导致后续的数据无法保存到FIFO中(写入超时)。而当上位机开始读取FIFO时,会发现FIFO的前一段数据(数据的长度与FPGA端配置的FIFO大小有关)与后续的数据是非连续的。为了避免类似的问题,需要在FPGA与上位机之间握手。
通常用于FPGA程序与Host程序同步的方法是使用一个握手控件。在FPGA的主程序之前,使用一个while循环,条件接线端链接着布尔控件。在上位机中,当一切准备就绪时(对FPGA的初始化以及其他初始化工作),可以为FPGA的Start控件赋上真值,这样,FPGA与Host端的数据传输就同步了,这是非常容易实现的方法。代码如下:

另一种方法是使用FPGA中提供的中断。在FPGA端需要等待上位机的数据或者等待上位机做好接收数据的准备时,产生一个中断。该中断会阻塞程序直到该中断被确认。当上位机中准备好向FPGA传输数据或者接收来自FPGA的数据时,上位机可以对中断进行确认。代码如下:

三、FIFO的使用
1) 使用场景:
该项目需要在回放时对信号进行精细的分析。尤其是有一个跳频信号,跳频的频带宽度为70MHz,跳频信号本身的带宽为5MHz,跳频信号的持续时间为1us~20us,跳频信号以突发的模式出现。需求是以较快的速率分析出信号文件中所有的频率点以及各个跳频信号所处的时间点。其实分析的原理不难,只需要对信号以足够精细的时间分辨率(1us)做FFT,判断该段信号是否有功率大于阈值的点就可以了。
在项目初期,曾经尝试过直接在上位机中做FFT,判断阈值,找到频点以及对应的时间点。但经过测试,上位机端进行数据处理的瓶颈在于大的数据块的分割。本程序中的数据源是存在磁盘阵列中的数据文件,从磁盘阵列中读取文件本身的速率可以达到非常高,500MB以上,但达到此速率的前提就是每次读取一个大的数据块(几兆到几十兆字节),否则,读取速率无法达到理想值;但这种情况下,就需要在程序中对大块的数据进行分割,然后进行FFT。虽然测试时已经开通了多个流水线进行数据分割,但速率依然达不到要求。整个系统的最高处理速率只有40~50MB/s,这对于120G(流盘5分钟)的跳频信号分析显然是不能满足要求的(分析5分钟的数据需要花将近1个小时的时间)。
基于这个原因,本程序将FFT的操作放在FPGA中完成。上位机中将大块的数据传输到FPGA中,FPGA天然的单点操作特性使得不需要进行大数据分割就可以完成小点数的FFT操作。由于N点时域信号做完FFT之后数据量没有减小,不能将FFT结果直接传回到上位机中进行阈值检测,所以FFT结果的阈值比较也在FPGA端进行单点比较,并将超过阈值的频点的索引值传回到上位机。
最终,FPGA端以400MB/s的速率对信号进行处理。
2) 初始化和配置:
每次在程序重新运行时,系统会对所有FIFO进行初始化,清除原有的数据。在上位机中对FIFO进行读取之前,要首先对FIFO进行开始操作,否则,虽然最终能读出数据,但前期会出现数据的丢失。当然,也可以通过编程的方式对FIFO进行初始化:使用FIFO的调用节点,先开始FIFO,再停止FIFO,再开始FIFO,就能完成FIFO的初始化并使FIFO处于就绪的状态。不过这种编程方法来初始化FIFO的操作不常用。
FPGA与Host端通常采用DMA的方式进行数据传输,数据在DMA控制器的作用下从FPGA传输到上位机的缓冲区中,LabVIEW从缓冲区读取到应用程序内部;在从上位机往下位机传输数据时,LabVIEW将数据从应用程序内部写入到缓冲区中,然后DMA控制器通过总线从缓冲区获取数据。在配置时,一方面需要配FPGA端的FIFO大小,这是通过窗口配置的方式来实现的。FIFO本身的大小在一定程度上可以减低数据覆盖的危险,但FIFO设置的过大,会占用太多FPGA的资源,且是没有必要的;另一方面需要配置上位机端用于DMA FIFO的缓冲区大小。一般,缓冲区的大小为每次读取的数据块大小的5~10倍左右。
3) FIFO读取和写入超时的利用:
参考FFT Co-processor范例,当FIFO中没有有效数据时,读取操作会发生超时,这时,不将无效数据写入到下一级的FIFO;在下一次定时循环时继续读取;当写入FIFO时发生超时,说明被写入的FIFO中已没有足够的空间存入新的数据,这时,下一次定时循环时,依然向FIFO中写入上一次循环的数据。当然,使用这种方式来进行数据传输时,FIFO读取和写入的数据都不会发生异常,但如果该流程中包含Host与FPGA之间的数据传输,则会影响FPGA执行的速率:I)Host端发送数据不够快,则FPGA中总是无法得到有效数据,导致FPGA处理流程受限于数据源;II)Host端接收数据不够快,则FPGA无法将FPGA-to-Host FIFO中的数据快速清空,进而影响FPGA从Host端取数据的速率。因此,在使用FPGA处理并向上位机传输数据的时候,上位机要以FPGA处理速率相当的速率或者以尽可能快的速率读取数据。推荐的方式如下:

很多时候,从FPGA中读取出来的数据需要直接流盘到磁盘阵列中。在高速流盘时对每次写入文件的数据块大小有要求——必须是扇区大小的整数倍,这种情况下,怎么进行读取呢?

当然,很多函数本身就自带输入就绪、输入有效和输出就绪、输出有效这些端口,可以将这些端口与FIFO读取和写入超时端口结合起来,保证读取或者写入数据的有效性。如下:

四线制的握手交互:上图中展示的已经是一种四线制的握手方式,完成了三个模块之间的交互。我们可以把这种交互分成左右两部分来查看,每一部分分别都是两线制的控制回环。首先来看左侧部分:读取FIFO IN时,如果发生超时,那么它输出的数据就是无效的,可以将这个端口与下一个模块的“输入有效”端口相连,来告知下一个模块这个必要的信息,对于无效数据,该模块应该丢弃;而如果第二个模块准备好接收下一个数据之后,第二个模块也将该信号反馈给第一个模块,告知第一个模块可以输出新的数据,否则,第一个模块不应该输出新的数据;这就构成了一个控制回环。再来看右侧部分:第三个模块如果准备好了接收新的数据,需要将这个信息告知第二个模块(连接到第二个模块的“输出就绪”端口),这时第二个模块就可以输出新的数据了,否则第二个模块不应该输出有效数据;而当第二个模块输出了有效的数据,那么第三个模块就应该接收数据,否则忽略。这又构成了一个控制回环。按照这样的思路,可以进行多级级联,完成多线制的握手。
四、FPGA中的数据类型转换
FPGA中的很多运算都用整型或者定点数完成,这其中会经常碰到数据转换的问题。比如,前端Adaptor采集到的信号的位宽是14,如果在FPGA中对数据进行FFT运算,就需要将整型数据转换成定点数;很多时候,在将整型数转换成定点数时,有客户会问:我的整数位数应该设置为多少呢?其实在数据转换时,首先要搞清楚整条链路上数据转换的步骤。前端的Adaptor在进行AD采样时,将数据转换从DBL的模拟量量化成N位的整数。在量化的过程中,有一个量程的概念。比如量程为±M,那么转换成将以±M作为归一化的参考值。假设实际的模拟值为A,则A采样值量化的方法如下:
量化值=A/M×2^((N-1))
之所以乘以2^((N-1)),是将最高位作为符号位进行处理。进一步,在FPGA端,将I16的数据转换成定点数,道理是一样的。在转换成定点数时需要设置整数位数,这个整数位数就是在FPGA中进行定点转换时的量程。当然,这里的量程表示的范围与AD量化时的量程有可能是不匹配的,导致转换之后的定点数与采样之前的信号实际值是不一致的,但是没有关系,只要牢记转换过程中的相对关系,可以基于相对的转换值进行计算。在将数据传递到上位机之后,如果要获取绝对的数值,则可以按照转换过程中的相对关系进行还原,即进行增益补偿。
另一种可能出现的转换就是:如果DMA接收到的数据是64位,其中包含两个样值,而后续处理是以32位的Sample为单位的,这就需要将64位FIFO中取出的数据转换成32位的数据,然后写入后续的FIFO中。前文有提到过,DMA的最高传输速率是基于64位数据位宽的,所以,很多时候,为了追求Host与FPGA之间的高速数据传输,FPGA从Host端接收的是64位数据。本程序就涉及到将64位数据写入32位的FIFO。具体实现的方法是取出一个64位数据之后,拆分成高位和低位两部分。定时循环每隔两个循环读取一个数据,但每次循环都要向32位FIFO中写入数据。有人可能认为,这是很简单的事儿啊:只要用一个奇偶判断,奇数循环时写入高位,偶数循环时写入低位不就行了?但测试发现,在一个循环内部,不能出现多个FIFO写入,否则,编译器会提示无法决定数据源。另外,这种方法本身也是不可靠的,如果奇数循环在写入高位时出现了超时,那么在下一个循环(即偶数循环),应该重新写入高位数据。同理,如果偶数循环写入时发生了超时,那么在下一个循环(即奇数循环)应该重新写入低位数据。最终,如下方法是经过测试的既有可靠性而在编程上又非常简便的方法:

五、FPGA编程时的普通循环和单周期定时循环
在说循环之前,我们首先来看一下FPGA在对代码编译到硬件上时会做什么样的操作。默认情况下,LabVIEW需要确保程序在顶层时钟下能编译成功。在编程时,我们常常对数据进行多种联结在一起的运算操作,如下所示。这些联结在一起的运算使得联合路径较长并导致总的时钟速率降低。基于这样的原因,LabVIEW会在如下代码的各运算函数之间增加寄存器,来拆分关键路径的长度,确保程序可以在顶层时钟下执行。每个寄存器的执行都需要一个tick,那么以下这段代码的执行之间就是3个ticks。

While循环和For循环都可以用来执行重复的计算操作。这一点,与上位机中的功能是完全一致的。通常,我们会将一些操作放在循环中进行持续的处理。那么上述代码在循环中的执行时序如下:

循环中每一个函数都在预留的硬件资源中等待上一个函数给出有效的输出。因此,每次循环的执行都需要三个时钟周期。上图中显示的还是一些简单的运算,例如乘法、加法、逻辑比较等。如果程序中用到了一些多周期的数值运算函数,比如商与余数、倒数、平方根、除法等,那么一个循环执行的时间将会更长。总结来说,一个普通的while或者for循环执行的速率依赖于顶层时钟以及一行代码最多有多少个运算。
基于上述的原理,很多时候,普通的while循环或者for循环并不能满足实际的需求。即使将顶层时钟提升,也是有上限的。这种情况下,可以使用单周期定时循环(SCTL)来实现功能。在单周期定时循环中,程序员可以控制联合路径的长度,因为程序不再自动在函数之间增加寄存器,而使用到的反馈节点以及移位寄存器在硬件上都使用触发器来实现。另外,单周期定时循环可以使用的时钟频率更加丰富。基于这些原因,单周期定时循环的效率接近HDL语言。同样将之前所述的代码放入到单周期定时循环中。

我们来看一下这段代码在普通的循环中和在单周期定时循环中的执行效率。

可以看见,普通的循环由于 有系统自动添加的寄存器的效果,每个时钟周期执行一个运算函数,而单周期定时循环可以在一个时钟周期内执行循环内的所有代码。当然,如果循环内的代码无法在一个时钟周期内完成,那么,程序在编译时就会报出定时错误。这种情况下,需要修改代码,减少关键路径所占用的时间。
六、FPGA编程时的流水线使用
如上所述,如果单周期定时循环内部代码执行所需的时间超出了定时时钟限定的范围,比如100MHz的时钟限定了单周期定时循环每次执行的时间为10ns,那么程序在编译过程中就会报出定时错误。消除这种错误的方法就是减少关键路径所占用的时间(关键路径是代码中需要时间最长的一条代码路径)。那如何消除?使用流水线。
流水线的编程方法就是人为地在关键路径(最长执行时延的路径)中插入一些寄存器。这些寄存器可以将联合的路径拆分开,这一点与普通循环中系统自动添加的寄存器的作用是一致的。但在普通循环中,每个时钟周期只执行一个函数,后续的函数虽然占用着硬件的资源,但由于没有接收到前端的有效数据所以不会开始执行。因此,整个循环的代码的执行时间是几乎函数个数的总和。但是,既然各个函数都有各自预留的硬件资源,那为什么不能让所有的函数在同一时间并行执行呢?这就是流水线的含义。而在单周期定时循环内部,在每个时钟周期内,每一个流水线节点都从各自的起始点开始执行。

上图分别展示了普通的循环、普通的单周期定时循环以及具有流水线的单周期定时循环对于同一个程序的执行流程。对于流水线的单周期定时循环,前两个周期的输出数据是无效的,从第三个周期开始输出了第一个有效的数据,此后每个周期都会输出一个有效的数据。所以,带流水线的单周期定时循环的执行效果只是会引入一定的输出数据时延,其他方面没有任何不同。而带流水线的单周期定时循环,由于使用了人为加入的反馈节点或者移位寄存器,将原来的关键路径拆分成了好几个部分,因此,一方面不容易在编译时出现定时错误,另一方面由于缩短了关键路径使得可以使用更高的时钟频率。具体编程时,请在时延和最高可达的时钟频率之间做一个权衡。
一些简单的流水线编程技例子如下:

-
新手福音:概述学习FPGA的一些常见误区2013-09-27 8610
-
如何选择合适的FPGA电源解决方案2018-08-13 3297
-
基于FPGA应用设计优秀电源管理解决方案2019-05-05 2915
-
MVC框架所存在的一些问题和解决方案2019-05-24 1962
-
为FPGA供电的最佳解决方案2019-12-11 3741
-
分布式存储器和触发器的一些解决方案?2020-08-05 2108
-
详解单片机编程中的一些时序问题2022-01-17 1563
-
简化FPGA的电源解决方案2022-11-23 809
-
实际的FPGA编程2009-07-23 513
-
如何处理实际布线中的一些理论冲突的问题2009-03-20 770
-
简化 FPGA 电源设计解决方案2017-04-18 1256
-
关于STM32f1和f4编程的一些问题解决方案2018-04-03 1022
-
LED照明一些问题的解决方案英文资料2018-04-16 1336
-
FPGA面向汽车电子的可编程逻辑解决方案2021-01-20 1253
-
NEON编程中的一些常见优化技巧2022-12-12 3206
全部0条评论

快来发表一下你的评论吧 !
