

基于FPGA 实现TDR-LTE 系统的ReedR-Muller 译码及其介绍
编码与解码
描述
摘要:主要基于FPGA 实现TDR-LTE 系统中的ReedR-Muller 译码,包括Reed-Muller 译码的介绍、方案的构成、FPGA 实现流程、以及实现结果分析。并在VirtexR-6 芯片上,进行了仿真、综合、板级验证。实现结果表明,该ReedR-Muller 译码算法应用到TDR-LTE 射频一致性测试仪表中具有良好的高效性和可靠性。
LTE 系统将最大系统带宽从5 MHz 扩展到20 MHz。能够在20 MHz 带宽内实现50 Mbit /s 上行瞬间峰值速率和100 Mbit /s 下行瞬间峰值速率,在上行共享信道中,对控制信息CQI,ACK 的信道编码方面采用Reed - Muller 编码和咬尾卷积编码[1]。
RM 码是一类能纠错多个错误比特的编码,在3GPPLTE 系统中RM 编码矩阵采用了更加复杂的交织技术,同时也增加了更多的掩码,这使得网络端的译码难度增大,传统的RM 译码算法有大数逻辑译码算法,但是在实现的时候难度比较大,译码的速度慢和资源占用多,所以本文主要是基于沃尔什- 哈达玛变换的译码算法来实现的。
FPGA 芯片内部有丰富的LUT 资源、寄存器资源、大量的固核资源,以及具有并行处理的内在优势,在使用FPGA进行RM 译码器设计的时候能够充分发挥它内在的优势[4]。并在Virtex - 6 芯片进行板级验证,对不同输入数目的RM译码在处理周期,资源占用情况进行对比分析,可以得出FPGA 中对编码与译码的处理速度更快,可靠性更高。
1 Reed -Muller 算法简介
1. 1 LTE 系统Reed -Muller 介绍
在LTE 系统中,在上行共享信道和上行控制信道中ACK 和CQI 信息在编码的时候都有可能采用Reed - Muller编码的方式。主要是根据高层配置的ACK 和CQI 的数目来决定。也就是在ACK 的数据大于2 比特的时候就采用Reed- Muller 编码的方式; CQI 信息在小于11 比特的时候也要采用Reed - Muller 编码。所以在接收端对接收到ACK 和CQI信息就需要进行Reed - Muller 译码的处理。
但是在上行共享信道和上行的控制信道中采用的Reed- Muller 编码的矩阵是不同的,在上行共享信道中采用( 32,11) 的编码方式,则在上行控制信道中采用( 20,11) 的编码方式。根据3GPP TS36. 212 协议可知,虽然它们采用不同的编码矩阵,但是它们的本质上是一样的,对于上行共享信道Reed - Muller 编码矩阵是由一阶Reed - Muller 和五个基本的掩码序列交织而得到的,而对于上行控制信道Reed -Muller 编码矩阵是有一阶Reed - Muller 和七个基本的掩码序列交织后对12 行进行打孔而得到的[2]。不管是哪种编码的方式,他们的编码公式都是:
其中,o 是输入的编码比特,M 表示( 32,11) 或者( 20,11) 编码表。b 是编码输出的比特。因此再经过后面的加扰和调制再发送出去。
1. 2 Reed -Muller 译码介绍
在接收端解完信道交织以后,就取到了ACK,CQI 信息,下一步就是根据它们之前的编码的比特数来决定对它们是否进行Reed - Muller 译码,对已Reed - Muller 译码常用的算法有全搜索算法译码和基于快速哈达玛变换的译码算法。而对于前者的译码其实也就是把所有的码字都进行编码再与接收端接收到的码字进行比较,找出最相近的码字作为译码的结果。这种译码的方式很简单,但是计算量大,处理的时间长而通常不采用。因此本文就是基于后者进行译码算法。同样本文是以( 32, 11) 编码的方式作为分析对象,而对于( 20, 11) 的处理过程是相类似的[3]。基于快速哈达玛变换的译码算法的译码过程如图1 所示。
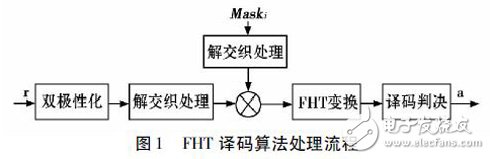
其详细过程如下所述:
步骤一: 发送端的编码矩阵是标准的一阶RM 码和掩码序列交织之后组成,所以接收端对接收到的码字b 进行相反的交织处理,同理M5 - M10 五个基本的掩码序列也要经过相反的交织处理,只有经过这样的交织处理才能进行正确的FHT 变换,按下面公式进行交织:
< 31,0, 20,1,2,21,3,4,22,5,6,23,7,8,9,24,19,25,
10, 11, 12, 13, 26, 27, 14, 15, 28, 16, 17, 18, 29, 30 >
步骤二: 五个基本掩码序列经过步骤一交织处理之后,进行线性组合。已知,五个基本的掩码序列可以线性组合产生32 个掩码矢量,然后分别与经过步骤一处理过的接收码字进行相乘( 消掩处理) ,这样得到32 个长度为32 的双极性序列。
步骤三: 因为M1 - M5 是交织以后的Walsh 码,它们的组合正好是32 阶Hadamard 矩阵的32 个行向量。因此再接收端用步骤二得到的双极性码字与32 阶的Hadamard 矩阵进行FHT 得到32 行32 列的相关值矩阵[5]。
步骤四: 在步骤三的相关值矩阵中找出绝对值最大数,记下这个数的行号与列号,从而这个最大值的列号,对应的二进制形式即为第2 ~ 6 比特( 倒过来的) ; 最大值的行号,对应的二进制形式即为第7 ~ 11 比特( 倒过来的) 。
步骤五: 由于M0 为全1 序列,它对相关值矩阵的影响是改变矩阵中所有值的符号。因此,判断步骤四中绝对值最大数的实际符号来译第1 比特,即: 正号时,译为0; 负号时,译为1。
2 Reed -Muller 译码FPGA 实现
用于Reed - Muller 译码的数据为做完解信道交织步骤以后解出的数据信息,包含CQI 信息,RI 信息和ACK 信息[6]。在FPGA 中处理的过程中,当解信道交织模块解出了CQI 信息或者ACK 信息时就给Reed - Muller 译码模块一个标志位,此时Reed - Muller 译码模块就把这个标志作为本模块开始译码的标志。
在FPGA 进行处理的时候为了提高处理的速度,对于译码的过程进行模块的划分,不同的模块完成不同的功能,再把各个模块综合在一起就能够达到译码的功能。下面就对各个模块的功能进行分析。( 1) 软信息合并,双极性化以及交织处理模块。在收到解信道交织模块的标志位的时候就开始做软信息合并,在FPGA 中的处理过程为,在取译码的数据的阶段,每隔32 个地址就取一个数据,再把这些数据进行加权平均。同样的处理进行32 次得到32 个16 位的软合并的信息。再根据数据的高位来判断是正数还是负数进行双极性化。双极性化的处理也就是把正数变成负数,负数变成正数。最后再根据交织表把这32 个数据进行交织。再把这32 个交织之后的数据放入din_mem 中,以备后面模块的使用。( 2) 消掩码处理模块。首先是把消掩码矩阵存储在一个1024 深度位宽为1 比特的ROM 中,再把din_men 中的数据取出来。第一次是和ROM 中的前32 个数据进行相乘,总的要进行32 次,每次取ROM 中的数据都是前一次基础的后32 个数据。相乘的过程是这样来处理的,当ROM 中的数据为1 的时候就把从din_men 取来的数据进行取反加一,而当ROM 中的数据为0 的时候就把din_men 中的数据保持不变。每做完一次都要给后面FHT 变换模块一个标志位。( 3) FHT 变换模块。消掩码处理以后的32 个数据和Hadamard矩阵相乘。由于Hadamard 矩阵的性质32 次相乘的过程可以化为5 级蝶形运算,这样就大大地缩短了译码的时间。每一级的加法和减法各16 次,总的就160 次运算。每次做完FHT 变换的时候都要存储两个信息,一个就是这个是第几个做FHT 变换,还有一个就是找出本次FHT 变换以后32 个数据中最大的数据在这个32 个数据中的位置[7]。( 4) 软判决模块。因为要做32 次FHT,每做完一次都要比较上面所述的两个信息对应的数据。把数据最大者的两个信息存储起来,为软判决做好准备。编码矩阵中M0 为全1 序列,它会改变相关值矩阵中所有值的符号,因此根据绝对值最大数的实际符号来译第1 比特,即: 正号时,译为0; 负号时,译为1。由于在发送端进行编码时第2 ~ 6 比特与Reed- Muller 码相乘,故绝对值最大值列序号对应的二进制形式即为第2 ~ 6 比特。由于在发送端进行编码时第7 ~ 11 比特与掩码相乘,故绝对值最大值行序号对应的二进制形式即为第7 ~ 11 比特。Reed - Muller 译码的大致过程就是这样。上面对译码流程的分析看似是顺序的过程,其实是并行处理的过程,可以在消掩码模块和FHT 模块之间的处理过程看出是并行的。因为交织之后的信息要进行32 次的消掩码和HFT 变换,在每次HFT 变换的同时还可以做上个模块的消掩码。所以在FPGA 中处理速度很快。图2 为Reed - Muller译码模块的实现流程框图。
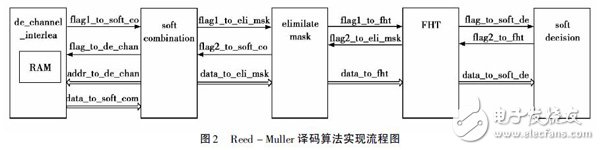
3 FPGA 仿真与实现结果分析
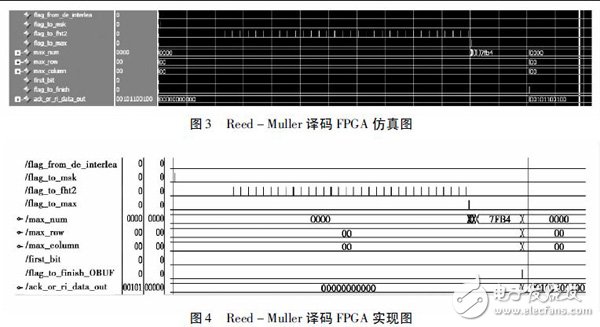
图3,图4 分别是Reed - Muller 译码模块的Modelsim 仿真图和基于Virtex - 6 板级验证的Chipscope 截图,在实现时芯片外部提供的时钟是200 MHz 的差分时钟,这个时钟连接到FPGA 的数字时钟管理模块( DCM) 进行倍频到300 MHz,这可以保证时钟的稳定性和可靠性。其中flag_from_de_interlea来自解信道交织模块,在解信道交织模块以后就要对控制信息进行译码,这个信号可以作为Reed - Muller 译码模块的开始标志位,首先就是软信息的合并,在完成软信息的合并之后就要对软信息进行消掩的处理,其中信号flag_to_msk 作为消掩处理的开始。在消掩处理完以后都要与32 阶Hadamard 矩阵相乘,每次都是取出消掩以后的数据和Hadamard矩阵的一行相乘,所以总的相乘的次数达到32 次。图中的信号flag_to_fht2 就是作为每次相乘的开始标志位。在处理完与Hadamard 矩阵相乘以后就得到一个32 行32 列的矩阵,在处理的时候这个矩阵是存储在双端口的RAM 中。这样在求最大值模块接收到信号flag_to_max 为高信号以后,就在上述存储32 行32 列的双端口的RAM 中取出最大值,并计算它在32 行32 列矩阵中的位置,也即是计算它在矩阵中的行号和列号,还要根据这个最大值是正数还是负数,要是正数first_bit 就译码输出0,要是负数first_bit 就译码输出1,最终译码输出信号ack_or_ri_data_out 就是根据上面求出的行号和列号以及first_bit 等信号输出译码的结果。比较图3 和图4 可以看出在板级验证的结果和仿真的结果完全一致,从而也保证了代码的可靠性,故已应用到TD_LTE 射频一致性测试仪表项目中。
4 结论及分析
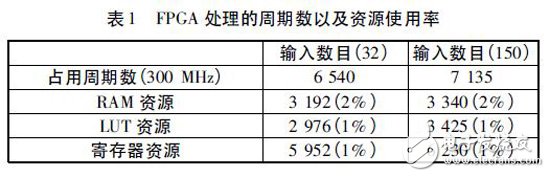
Reed - Muller 译码算法的Verliog[4] 程序已通过Xilinx ISE13. 4 的编译,行为仿真以及板级验证。其结果和理论值一致,其精确度可以达到TD_LTE 射频一致性测试仪表项目的要求。在满足项目的同时还要考虑FPGA 芯片资源的问题,FPGA 中速度和面积总是相矛盾,在追求速度的同时,也要考虑芯片资源的问题。在资源充足的时候,我们可以采用多级流水线的结构和并行运算来提高速度。本文就是采用此方法极大地提高了处理的速度,不同输入数据长度的Reed- Muller 译码的周期数和占用的资源的数据如表1 所示。可以看出在FPGA( Virtex - 6 芯片) 中处理速度非常快,占用的芯片资源也比较少,给后面译码工作节省了更多的时间和空间。更能够满足项目上的要求,故该方案已应用于国家重大科技专项“TD - LTE 射频一致性测试仪表”的开发中。
-
怎么实现BCH译码器的FPGA硬件设计?2021-06-15 1515
-
突发通信中的Turbo码编译码算法的FPGA实现2021-05-07 1498
-
如何使用FPGA实现跳频系统中的Turbo码译码器2021-04-01 962
-
如何使用FPGA实现LTE-A系统的物理下行链路2018-11-09 1030
-
tdr测试的原理及方法介绍2018-04-23 78886
-
DSP嵌入式系统开发典型案例,第9章 Viterbi译码及其实现2017-10-20 833
-
RS编译码的FPGA实现研究2016-03-30 647
-
应用于LTE_OFDM系统的Viterbi译码在FPGA中的实现2012-08-11 2181
-
基于FPGA的高速RS编译码器实现2012-05-22 1113
-
TDR测试过程静电危害及其预防2011-12-16 4148
-
LTE标准下Turbo码编译码器的集成设计2010-11-11 978
-
卷积码的Viterbi高速译码方案2010-07-21 1037
-
3G测试系统中的Viterbi译码及其DSP实现及优化2009-11-13 721
-
应用于LTE-OFDM系统的Viterbi译码在FPGA中的实现2009-09-19 4214
全部0条评论

快来发表一下你的评论吧 !
