

快速高效的实现浮点复数矩阵分解
FPGA/ASIC技术
描述
浮点具有更大的数据动态范围,从而在很多算法中只需要一种数据类型的优势。 本文介绍如何使用Vivado HLS实现浮点复数矩阵分解。使用HLS可以快速,高效地实现各种矩阵分解算法,极大地提高生产效率, 降低开发者的算法FPGA实现难度。

void matrix_dcmp
(
cf_t in_u[(R_DIM+Y_DIM)/DIV_NUM][DIV_NUM],
cf_t pd_err_in,
float lamda,
float lamda_sqrt,
float diag[R_DIM],
cf_t r[R_DIM][X_DIM],
cf_t p[R_DIM]
)
{
coef_cal(lamda_sqrt,lamda,diag[i],pre_in_u,pd_err_in,&s_o,&s_conj_o,&la
mda_sqrtxs_o,&c_o,&lamda_sqrtxc_o,&diag_out,&p_o,&pd_err);
cal_core(u_tmp, r_tmp, s_n, i, j, k, c_o, lamda_sqrtxc_o, lamda_sqrtxs_o,
s_conj_o, &in_u_w2, &r[i][r_addr]);
}
void coef_calc
(
float lamda_sqrt,
float lamda,
float r_diag,
cf_t u_diag,
cf_t pd_err_in,
cf_t *s,
cf_t *s_conj,
cf_t *lamda_sqrtxs,
float *c,
float *lamda_sqrtxc,
float *diag,
cf_t *p_o,
cf_t *pd_err
)
void calc_core
(
cf_t in_u,
cf_t r,
int s_n,
int i,
unsigned char j,
unsigned char k,
float c_o,
float lamda_sqrtxc_o,
cf_t lamda_sqrtxs_o,
cf_t s_conj_o,
cf_t* u_ret,
cf_t* r_ret
)
Vivado-HLS生成的RTL代码在默认情况下保留原有c代码的层次结构,在构建c代码层次时,可以采用由上至下,从下至上相结合的模块划分方式。对基本的浮点运算如加,减,乘,除,平方根等写成最底层的子函数,并对其加pipeline, 甚至对输出打一拍register以获得更好的时序性能。如下例:
template T reg(T x) {
#pragma HLS inline self off
#pragma HLS interface ap_none register port=return
return x;
}
cf_t mult( cf_t in1, cf_t in2 ) {
#pragma HLS PIPELINE
cf_t out;
float in1_re_in2_re, in1_im_in2_im, in1_re_in2_im, in1_im_in2_re;
in1_re_in2_re = hfmult(in1.re,in2.re);
in1_im_in2_im = hfmult(in1.im,in2.im);
in1_re_in2_im = hfmult(in1.re,in2.im);
in1_im_in2_re = hfmult(in1.im,in2.re);
out.re = (in1_re_in2_re - in1_im_in2_im);
out.im = (in1_re_in2_im + in1_im_in2_re);
return reg(out);
}
float hfmult
(
float in1,
float in2
)
{
#pragma HLS PIPELINE
float out;
out = in1 * in2;
return reg(out);
}
另外为了提高运算的并行度,需要对matrix_dcmp中in_u及r数组(HLS综合成FPGA的BRAM或分布式RAM)加数组分割这个directive,这样数据才可以并行进来到并行处理单元。
#pragma HLS ARRAY_PARTITION variable=in_u complete dim=2
#pragma HLS ARRAY_PARTITION variable=r complete dim=2
3,Vivado-HLS矩阵分解时序优化
为了使in_u综合出的RAM时序更好,可以对in_u综合的RAM加resource directive来控制其为3 stage,这样生成的RAM输入,输出都会打一拍register。
#pragma HLS RESOURCE variable=in_u core=RAM3S
同样我们也可以通过设置充足的latency directive给DSP48,这样有足够的时钟节拍给到DSP48内部打拍register。
如果对上述的单精度浮点乘法hfmult latency设置为3,这样分配到每个DSP48 内部只有2级latency, 那么综合总合出来代码DSP48内部的A_reg 或 P_reg不会打一拍, 这样对时序性能有很大下降。
derive_core fmul_der -base FMul_maxdsp -latency 3 -fixed
set_directive_resource -core fmul_der hfmult out
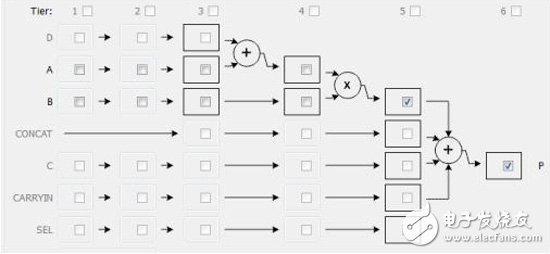
或
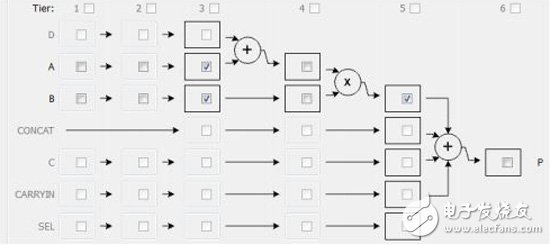
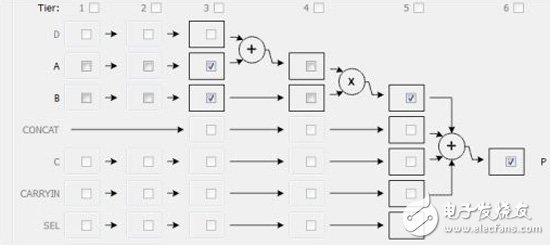
为了达到较好的时序性能,对上述的单精度浮点乘法hfmult latency至少设置为4,这样分配到每个DSP48 内部只有3级latency, 那么综合总合出来代码DSP48内部的A_reg 或 P_reg都会各打一拍。
derive_core fmul_der -base FMul_maxdsp -latency 4 -fixed
set_directive_resource -core fmul_der hfmult out
4,Vivado-HLS矩阵分解设计结果
这个设计中矩阵的大小是128x128的单精度浮点,复数。
采用了串行与并行结合的实现方式。
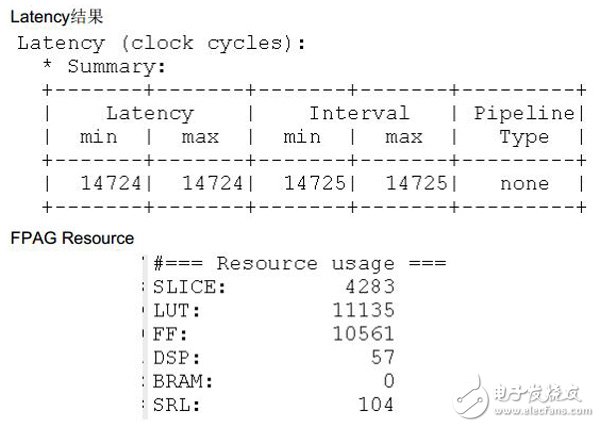
-
复数浮点FFT说明资料2021-08-10 945
-
基于CNN与约束概率矩阵分解的推荐算法2021-06-17 941
-
采用余弦相似度的习俗非负矩阵分解算法2021-05-08 999
-
求一种复数浮点协方差矩阵的实现方案2021-04-29 2907
-
如何在FPGA上实现复数浮点的计算2020-12-22 747
-
Altera浮点矩阵相乘IP核怎么提高运算速度?2019-08-22 3387
-
基于矩阵分解的手机APP推荐2017-12-22 1069
-
利用CUR矩阵分解提高特征选择与矩阵恢复能力2017-12-05 1682
-
在FPGA上优化实现复数浮点计算2017-12-04 1134
-
用Xilinx Vivado HLS可以快速、高效地实现QRD矩阵分解2017-11-17 4526
-
第30章 复数FFT的实现2016-09-28 7848
-
基于Altera浮点IP核的浮点矩阵相乘运算的实现和改进设计2012-10-15 6610
-
基于IP核的数选式浮点矩阵相乘改进2011-09-07 3522
-
基于复数浮点运算的协方差矩阵的FPGA实现2010-10-08 3440
全部0条评论

快来发表一下你的评论吧 !
