

在深度学习中为什么要正则化输入?
电子说
描述
本文作者原创,转载请注明出处。
今天我们来讲解一下为什么要正则化输入(也叫标准化输入)呢?
正则化输入其实就是论文中说的局部相应归一化,它最早由Krizhevsky和Hinton在关于ImageNet的论文里面使用的一种数据标准化方法。
在实际应用中,我们可能会遇到各维度数据或者各特征在空间中的分布差别很大。就如同下图

这给训练增加了难度,我们可以看一下如果是这样的数据我们会得到一个什么样的梯度下降图。
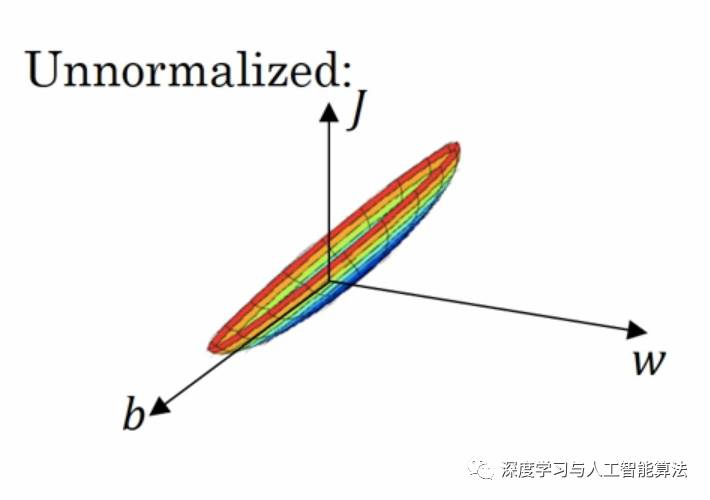
很明显,这是一个狭长的立体图形,在进行反向传播的过程中,如果在两端开始梯度下降的话,整个过程就变得很漫长。所以为了解决这种情况,我们使用了正则化输入去解决。下面就是正则化输入的计算公式:
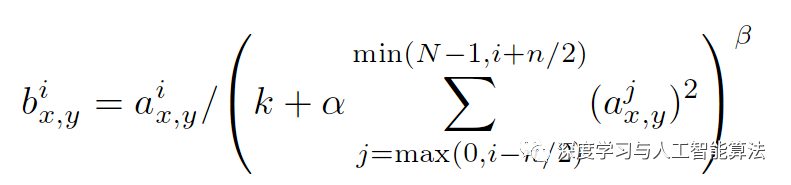
按照这个公式来计算的话,我们的梯度下降就变成这样了。
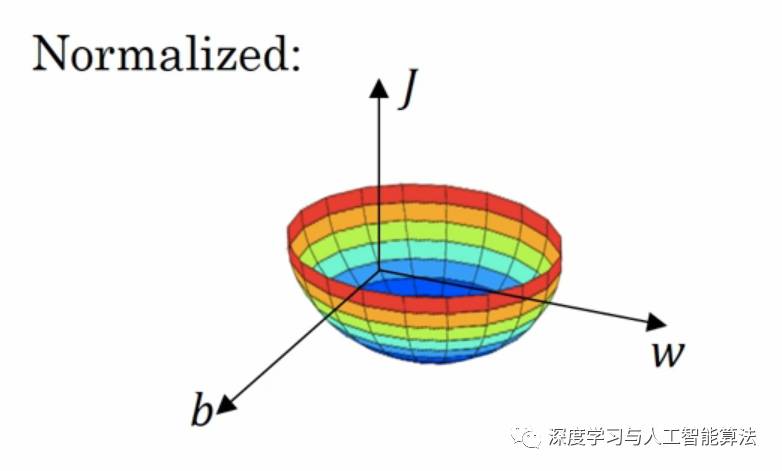
这样的话我们无论是从哪一个点开始梯度下降,得到的效果是一样的。
那我们再来看一下在Tensorflow中是怎么实现的。Tensorflow中的API是tf.nn.lrn,别名也叫tf.nn.local_response_normalization,这两个是一个东西。再来看一下函数是怎么定义的:
local_response_normalization( input, depth_radius=5, bias=1, alpha=1, beta=0.5, name=None)
里面那么多参数,那分别又是代表什么呢?首先,input是我们要输入的张量,depth_radius就是上面公式中的n/2,其实这个变量名为什么叫depth_radius呢?radius不是半径吗?与半径又有什么关系呢,我等下再来讲解为什么。接着,bias是偏移量,alpha就是公式中的α,beat就是公式中的β。
其实啊,LRN也可以看作是“每个像素”在零值化后除以“半径以内的其他对应像素的平方和”,这个半径就是给定的变量depth_radius的值。
那我们用代码来看一下效果怎么样:
import numpy as npimport tensorflow as tfa = 2 * np.ones([2, 2, 2, 3])print(a)b = tf.nn.local_response_normalization(a, 1, 0, 1, 1)with tf.Session() as sess: print(sess.run(b))
输出的结果a是:

输出的结果b是:

-
深度学习在汽车中的应用2019-03-13 3951
-
改善深层神经网络--超参数优化、batch正则化和程序框架 学习总结2020-06-16 1492
-
深度学习在预测和健康管理中的应用2021-07-12 1889
-
一种基于机器学习的建筑物分割掩模自动正则化和多边形化方法2021-09-01 2039
-
dropout正则化技术介绍2017-10-10 1418
-
基于快速自编码的正则化极限学习机2017-11-30 1911
-
三种典型的神经网络以及深度学习中的正则化方法应用于无人驾驶2018-06-03 10275
-
【连载】深度学习笔记4:深度神经网络的正则化2018-08-14 3849
-
深度学习笔记5:正则化与dropout2018-08-24 4270
-
详解机器学习和深度学习常见的正则化2020-01-29 3464
-
基于AdaBoost框架的弹性正则化多核学习算法2021-06-03 693
-
基于耦合字典学习与图像正则化的跨模态检索2021-06-27 732
-
深度学习在语音识别中的应用及挑战2023-10-10 1508
-
深度学习模型中的过拟合与正则化2024-07-09 2443
-
NPU在深度学习中的应用2024-11-14 3101
全部0条评论

快来发表一下你的评论吧 !
