

一种基于Mailbox核间机制的多核处理系统
FPGA/ASIC技术
描述
摘要:随着电子产业.工商业以及军事化产业的迅猛发展,越来越多的复杂运算已经无法单纯利用算法上的优化处理来大幅提升执行速度.为了解决日益复杂的计算问题,利用多核处理势必成为一种大势所趋.所以着手从多核和单核对比出发,利用Xilinx 的XUP Virtex-2 Pro建立多核处理平台(基于Shared Memory通信机制)以及单核平台,并将相同的图像处理算法DCT分别运行在所构造的基于FPGA的单核和多核硬件平台上,观察实验结果,比较多核和单核运行所需的时间以及资源的消耗,最终的结果有力的说明多核在图像处理方面的绝对优势。
0 引言
基于FPGA的嵌入式应用在近几年来作为一个比较新颖的课题,已经在通信.消费电子.医疗.工业和军事等诸多领域占据了相当重要的地位.相对于其他芯片来说,使用FPGA设计的电路执行速度快.上市时间短.成本低廉.可靠性高以及易于维护升级.正是这些优点才使得FPGA的应用范围越来越广泛,备受各个领域设计师们的青睐.但是有关于它在多核体系上的研究却一直很少有人涉及.本文在研究各种核间通信机制的基础上,提出了一种基于Mailbox核间机制的多核处理系统,在该系统中集成了Xilinx的软核处理器Microblaze,其降低了使用多信号处理板但来的成本问题同时还节省了空间,对更好的发挥多核系统提出了新的解决方案.
1 总线机制与核间通信机制
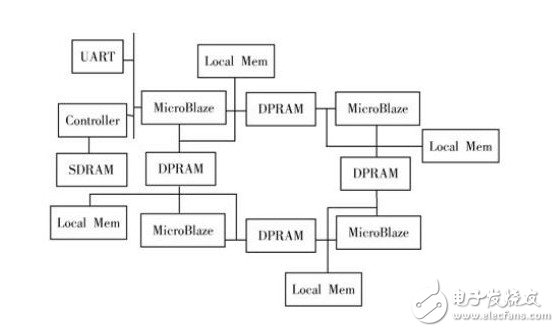
在多核嵌入式系统的设计中,核间通信机制与核间传输总线在选用时很有讲究,常用的总线有:OPB总线.PLB总线.XCL总线.FSL总线.LMB总线,同时多核通信系统中常用的通信机制以及通信手段包括:Mailbox,Mu-tex,Shared Memory,Interrupt,PLBv46_PLBv46 Bridge,FSL互连机制,DMA Controller等.如图1所示。
1.1 PLB总线
PLB 总线(Processor Local Bus)总线包括了一个总线控制单元.一个看门狗定时器以及独立的地址和读/写数据路径单元,另外,还包括了一个可选用的DCR(Device Control Register)从接口以提供对总线错误状态寄存器的访问。
1.2 LMB总线
LMB 总线主要用来连接片上BRAM(BlockRAM).为了能在一个时钟周期内完成访问,LMB采用了最少的控制信号和简单协议的方式.它分为指令寄存器DLMB 和数据寄存器ILMB 两类接口,而且这些接口只和BRAM连接。
1.3 Shared Memory通信机制
共享内存是一种典型的快速异步通信机制,因其使得零拷贝有可能实现,固非常适用于大于1 000 B的大型数据量共享的情况,共享内存可分为两种:BlockRAM和外部内存DDRR。
2 RGB2YCrCb 算法以及DCT算法介绍
RGB,YCrCb是表示颜色时经常用到的两种颜色空间,在应用中经常需要实现它们之间的转换.例如在人脸检测中就常常用到YCrCb空间,因为一般的图像都是基于RGB 空间的,在RGB 空间里人脸的肤色受亮度影响相当大,所以肤色点很难从非肤色点中分离出来,也就是说在此空间经过处理后,肤色点是离散的点,中间嵌有很多非肤色,这为肤色区域标定(人脸标定.眼睛等)带来了难题.如果把RGB转为YCrCb空间的话,可以忽略Y(亮度)的影响,因为该空间受亮度影响很小,肤色会产生很好的类聚。
而DCT 变换是视频压缩编解码器中很重要的一部分,被广泛应用于各种视频格式的编码算法中,例如:
JPEG,MPEG1,MPEG2,H.264等.
DCT 是先将整体图像分为N×N 的像素块,然后对N×N 的像素块逐一进行DCT变换.由于大多数图像的高频分量较小,对应于图像高频分量的系数经常为零,加上人眼对于高频成分的失真不太敏感,所以可以用更粗糙的量化.因此,传送变换系数的数码率要大大小于传送图像像素所用的数码率.图像到达接收端后通过反离散余弦变换回到样值,虽然会有一定的是真,但人眼是可以接受的,公式如下:
式中C(u) 和C(v) 在u.v 为0时等于1 2 ,其他情况下均为1,而x,u = 0,1,2,…,M – 1 ; y,v = 0,1,2,…,N – 1.
3 多核系统设计环境与系统软硬件的设计
本文所采用的软件开发环境是Xilinx 公司旗下的ISE 10.1开发套件,硬件开发平台采用的是Xilinx 的XUP Virtex-2 Pro[8-9]开发板,而ISE 10.1开发套件嵌入了EDK 开发包(其集成了Xilinx Platform studio,SoftwareDevelopment,库文件生成器,编译工具等开发模块),这样就大大方便了软硬件的开发.
3.1 利用XPS向导进行多核硬件系统设计
打开XPS 软件后,首先利用Base System Builder向导建立一个单核系统,在此基础上通过添加新的Micro-blaze 处理器软核以及必要的内存块.数据指令控制器和相应的外围设备来完成多核系统的创建.有关基于BRAM的共享内存机制已经简要的介绍过,这里不再重复.整个系统的框架如图2所示。
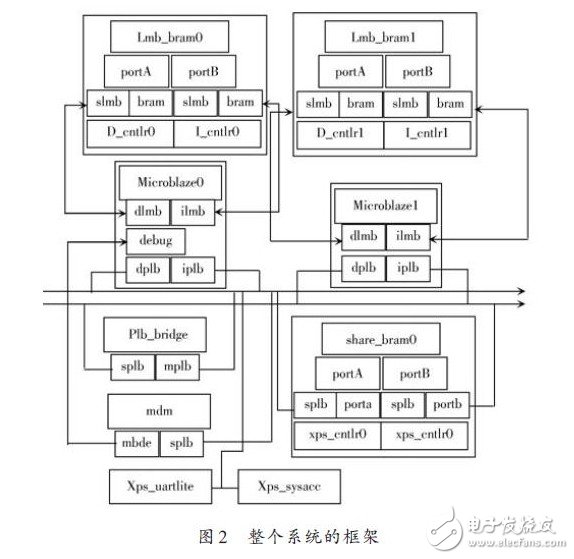
硬件系统采用的总线机制为PLB总线,所有的Mi-croblaze均挂在这两条总线上,并且以Microblaze0作为主处理器,其他用作从处理器.
设计中PLB总线的从设备主要是xps-uartlite,它作为系统的主要验证手段,通过串口打印可以在PC机终端里输出核间通信信息.LMB 总线则用于连接片上BRAM 和MB 的各个LMB 接口,实现了D/I LMB 端口与启动内存块.数据/指令控制器的互连.
PLB 桥的作用是使得所有的处理器可以共享外围设备,如串口RS 232等.
3.2 利用EDK套件进行多核软件开发
在软件开发过程中,一方面除了需要注意重要的宏定义以及数据结构的设计外,如在RGB2YCrCb处理中,为了在后续的代码中对内存进行操作,需要对这些内存地址进行预先的宏定义以及设计有关BMP图片信息头的数据结构和信息获取函数;另一方面也要注意算法的设计.编译与部署.具体算法的核心部分设计如下所述.
RGB2YCrCb的核心算法如下:




4 硬件实现
4.1 测试所搭建的硬件系统的步骤
(1)点击Hardware 下的Generate Bitstream 按钮,生成配置FPGA所需要的比特流文件;
(2)将PC 机与Virtex-2 Pro 开发板正确连接,并且给开发板上电;
(3)打开超级终端或是Putty工具,设置正确的参数(如波特率.奇偶校验位以及流控制位等),确保和创建硬件系统时的设置一致;
(4)点击Device Configuration 下的Download Bit-stream进行比特流的下载配置;
(5)观察终端中的打印信息,判断是否和Tes-tapp_Memory.c文件中的一致.
4.2.1 图像算法在单核上的执行流程
(1)算法按照宏块顺序往下处理,先处理第一个宏块;
(2)对第一个宏块的前4个Y分量进行RGB2YCrCb处理,完成后对YCrCb结果做DCT(YMatrix,color)变换;
(3)对第一个宏块的Cr 分量进行RGB2YCrCb 处理,完成后对YCrCb结果做DCT(CrMatrix,color)变换;
(4)对第一个宏块的Cb 分量进行RGB2YCrCb 处理,完成后对YCrCb结果做DCT(CbMatrix,color)变换;
(5)返回到步骤(1)进行第二个宏块的处理.
基于单核架构的处理流程是一个串行执行过程,体现在宏块于宏块之间是处于一种阻塞等待性的机制,换言之,只要宏块0的任何一个分量(Y/Cr/Cb)没有独立处理且最终完全处理完毕后处理器都必须等待,而无法转向宏块1进行后续的处理.
4.2.2 下载比特流,配置FPGA
(1)正确连接好Virtex-2 Pro 开发板,并给板子上电;
(2)打开一个超级终端或是Putty工具,注意设置匹配的波特率.奇偶校验位以及流控制位;
(3)对于需要运行的应用程序,右单击选中Markto Initialize BRAMs以初始化内存块;
(4)在Device Configuration 中点击Download Bit-stream下载比特流,配置FPGA;
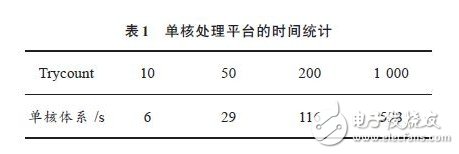
(5)修改shm.c文件中Trycount值(该值为一幅8 KB图片进行循环处理的次数),然后重新编译.下载并配置FPGA,统计每次处理完成的时间,并填写表1.
4.3 多核执行图像处理算法以及时间测量
4.3.1 图像算法在多核上的执行流程
(1)算法仍以宏块处理为单位,MB0先对第一个宏块进行处理;
(2)MB0对第一个宏块的4个Y分量进行RGB2Y变换,并将中间结果写入内存,作为MB1 进行DCT(YMa-trix,color)的输入数据;
(3)MB1读取颜色转换后的Y 分量,对其进行DCT(YMatrix,color);
(4)MB0在将Y分量写入共享之后,立即开始Cr分量的RGB2Cr变换,并将Cr结果写入共享作为MB1进行DCT(CrMatrix,color)变换的输入数据;
(5)MB1读取颜色转换后的Cr 分量,对其进行DCT(CrMatrix,color);
(6)MB0 在将Cr 分量写入共享之后,立即开始Cb分量的RGB2Cb 变换,并将Cb 结果写入共享作为MB1进行DCT(CbMatrix,color)变换的输入数据;
(7)MB1读取颜色转换后的Cb 分量,对其进行DCT(CbMatrix,color);
(8)MB0完成一个宏块的处理之后不等待,即可返回步骤状态进行第二个宏块的处理,而MB1 则以MB0的处理过程循环往复.
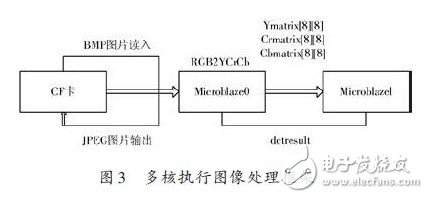
基于双核架构的处理流程也是一个并行执行过程,体现在当MB0做好RGB2YCrCb(所有分量的颜色变换)之后,只需将处理的中间结果写入内存作为MB1 进行DCT 变换的出入数据,而无需等待MB1 上DCT 处理进程的完成,在MB1 进行上一个宏块的DCT 变换处理过程中,MB0 已经转向宏块1 进行下一轮的各个分量的RGB2YCrCb处理.
4.3.2 下载下载比特流,配置FPGA
所有步骤同单核配置过程.运行后同样要改写shm.c文件中的Trycount值,记录时间,并填写表2.
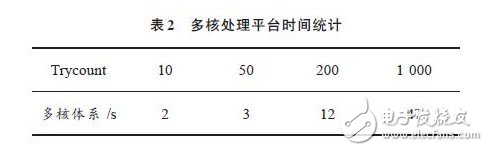
通过表1,表2的对比,很容易发现,多核体系在时间上有明显的优势.
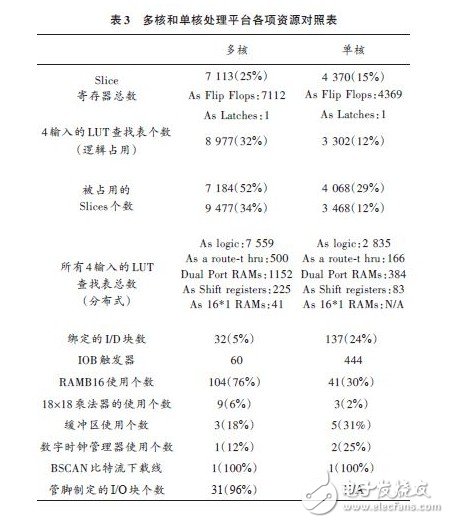
4.4 单核/多核体系占用资源对比
通过编译,在生成的编译报告中将两者所用的资源统计如表3所示.从表中可以看到在硬件资源的占用上,双核体系的确消耗的资源较多.
5 结语
多核系统由于采用了并行环路体系并摒弃了单核阻塞状态下的等待时间,从而能够达到处理时间上的优化,但是另一方面其对片上资源的消耗也会随着从处理器的增加与日俱增,这也印证了“速度与面积”不能兼得这条原则,所以在工程中一定要做好权衡,权衡算法性能优化和硬件资源占用率的取舍,最好能够折中.
当然在处理如图像处理.信号处理类的一些复杂算法时,多核机制还是相当具有可取性的,毕竟在实际工程中,往往不介意以空间资源消耗来获取时间上的优化处理。
- 相关推荐
- 热点推荐
- FPGA
-
一种心电信号处理系统设计2023-10-11 420
-
核间通信(IPC)的目标和实现机制2023-09-13 5686
-
SoC的核间通信机制—mailbox介绍2023-08-11 8806
-
怎样去设计一种视频采集与处理系统?求过程2021-06-04 1532
-
怎样去设计一种数据采集与处理系统?2021-06-03 1333
-
怎样去设计一种图像预处理系统?2021-05-06 1516
-
探究一种新的可配置处理器的异构多核线程级动态调度模型2021-04-27 2693
-
创龙带您解密TI、Xilinx异构多核SoC处理器核间通讯2020-09-08 2311
-
典型的支持多核处理器的RTOS功能解析2019-06-29 6023
-
一文读懂异构多处理系统2018-05-14 5182
-
一种基于STM32的弱磁信号检测和处理系统2017-09-28 975
-
一种脉冲多普勒引信数字化信号处理系统2016-12-23 1042
-
多核处理器设计九大要素2011-04-13 3169
全部0条评论

快来发表一下你的评论吧 !
