

基于Zynq SoC的嵌入式视觉系统开发流程详解
嵌入式技术
描述
将Vivado HLS与OpenCV库配合使用,既能实现快速原型设计,又能加快基于Zynq All Programmable SoC的Smarter Vision系统的开发进度。
计算机视觉技术几年来已发展成为学术界一个相当成熟的科研领域,目前许多视觉算法来自于数十年的科研成果。不过,我们最近发现计算机视觉技术正快速渗透到我们生活的方方面面。现在我们拥有能自动驾驶的汽车、能根据我们的每个动作做出反应的游戏机、自动工作的吸尘器、能根据我们的手势做出响应的手机,以及其它等视觉产品。
今天我们面临的挑战就是如何高效实现上述这些及未来的各种视觉系统,同时满足严格的功耗和上市要求。此类产品可以Zynq™ All Programmable SoC为基础,并结合广泛使用的计算机视觉库OpenCV和高层次综合(HLS)工具,以实现关键功能的硬件加速。这种强强组合能为设计和实现Smarter Vision系统提供强大的平台。
嵌入式系统在当今的市场中无所不在。不过,计算功能方面的局限性,尤其是在处理大型图片、高帧率时计算能力低下严重限制了嵌入式系统在计算机/机器视觉实际实现方面的应用。图像传感器技术的发展犹如为嵌入式器件装上了慧眼,能帮助该器件通过计算机视觉算法与环境互动。嵌入式系统和计算机/机器视觉的融合催生了嵌入式视觉技术,这是一个快速发展的领域,正成为设计能够观看并了解周边环境的设备的基础所在。
嵌入式视觉系统的开发
嵌入式视觉技术要在计算平台上运行智能计算机视觉算法。对许多用户来说,标准的桌面计算处理平台即可方便地满足需求。不过,一般性计算平台或许无法满足高度嵌入式产品的生产需求,这种产品要做到小型化、高效性、低功耗,而且要处理庞大的图像数据集,比如同时处理多个每秒60帧的实时高清视频流。
图1给出了设计人员通常用来创建嵌入式视觉应用的流程。算法设计是整个流程中最重要的一环,因为算法将决定我们能否满足任何特定计算机视觉任务的处理和质量标准要求。首先,设计人员在MATLAB®等数字计算环境中搜索算法选项,明确高级处理选项。一旦确定了适当的算法,设计人员通常用C/C++等高级语言来为算法建模,以便快速执行,并满足最终比特精度实现方案的要求。
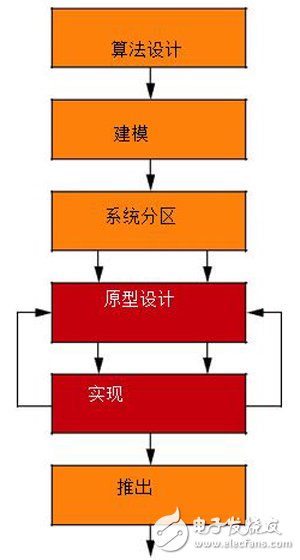
图1 嵌入式视觉系统开发流程
系统分区是开发过程中的重要步骤。在此,设计人员通过算法性能分析,可明确他们要对算法的哪些部分进行硬件加速,从而满足处理代表性输入数据集的实时要求。同样重要的是对目标平台中的整个系统进行原型设计,从而实际地检测性能预期。一旦原型设计过程说明设计满足了所有性能和质量目标要求,那么设计人员就能在实际的目标器件中启动最终系统实现。最后一步就是测试运行在芯片上的设计在各种用例场景下的表现。一切检查完成后,设计团队就能发布最终产品。
ZYNQ SOC:嵌入式视觉的最明智的选择
在开发机器视觉应用过程中,设计团队必须选择高度灵活的器件,这一点至关重要。设计团队所需的计算平台应提供强大的通用处理功能,以支持多种不同的软件生态系统,此外还要有稳健可靠的数字信号处理功能,以便实现计算强度高、存储高效的计算机视觉算法。芯片的高度集成对实现高效、完整的系统至关重要。
赛灵思All Programmable SoC是以处理器为中心的器件,在单芯片上提供了软/硬件和I/O可编程性。Zynq SoC在单个器件中集成了一个ARM®双核Cortex™-A9 MPCore™处理系统、FPGA逻辑和一些关键外设。这样,该器件就能帮助设计人员实现极为高效的嵌入式视觉系统。
处理子系统、FPGA逻辑和外设在Zynq SoC中的高度集成能确保相对于采用分立式组件设计而成的系统而言提高数据传输速率,降低功耗和材料清单成本。我们能用Zynq SoC实现实时处理支持1080p60视频序列(1,920 x 1,080 RGB图像,每秒60帧)的系统,达到每秒数千亿次运算的处理功能。
为了全面利用Zynq SoC的诸多功能与特性,赛灵思推出了以IP和系统为中心的设计环境Vivado™设计套件。该套件可加速集成和实现,从而可帮助设计人员提高开发生产力,进而动态开发出Smater嵌入式产品。Vivado HLS作为该套件的一个组件,能帮助设计人员将采用C/C++语言开发的算法编译为RTL,以便在FPGA逻辑中运行。
Vivado HLS工具非常适用于嵌入式视觉设计。在此流程中,您用C/C++创建您的算法,再用Vivado HLS将算法或算法的一部分编译为RTL,进而确定哪些函数更适合在FPGA逻辑中运行,哪些函数更适合在ARM处理器上运行。这样,您的设计团队就能集中精力打造出最佳性能的基于Zynq SoC的视觉系统。
为了进一步帮助嵌入式视觉开发人员创建Smarter Vision系统,赛灵思在Vivado中增加了对OpenCV计算机视觉算法库的支持。赛灵思还推出了最新IP Integrator工具和SmartCORE™ IP以支持此类设计(参见封面报道的第8页)。
OPENCV推广计算机视觉技术
OpenCV开辟了一条开发智能计算机视觉算法的途径,而且能预测实时性能。该库为设计人员提供了用于算法试验和快速原型设计的环境。
OpenCV设计框架得到多平台支持。不过在许多情况下,要提高库对嵌入式产品的效率,就需要在嵌入式平台上实现,而且该平台要能够加速高强度例程,满足实时性能要求。
虽然OpenCV在设计时就考虑到计算效率问题,不过它源自传统计算环境,可支持多核处理。这种计算平台或许对高度强调效率、成本和功耗的嵌入式应用来说并不是最佳选择。
OPENCV的特性
OpenCV是一款基于BSD许可证授权发行的开源计算机视觉库,这就意味着它可免费用于学术和商业应用中。它最初设计旨在提高通用多处理系统的计算效率,侧重于实时应用。此外,OpenCV还提供C/C++和Python等多种编程接口。
开源项目的优势在于,用户能持续改进算法,并将算法扩展用于多种不同应用领域。目前用OpenCV可现实2,500多种功能,其中包括:
• 矩阵数学
• 公用设施和数据结构
• 通用图像处理功能
• 图像转换
• 图像金字塔
• 几何描述符函数
• 特性识别、提取和跟踪
• 图像分割与拟合
• 摄像头校准、立体化和3D处理
• 机器学习:检测、识别
有关OpenCV的更多详情,敬请访问以下网址: opencv.org 和 opencv.willowgarage.com 。
用HLS加速OPENCV函数
一旦完成了嵌入式视觉系统架构的分区,找到了计算强度最大的部分,HLS工具就能帮助您加速这些函数,同时仍能继续使用C++编写。Vivado HLS用C、C++或SystemC代码生成高效的RTL实现方案。
此外,以IP为中心的Vivado设计环境提供丰富的处理IP SmartCORE,能简化到图像传感器、网络及其它必要I/O接口的连接,简化OpenCV库中这些函数的实现。这相对于其它实现方案而言是一种明显的优势,因为其它方案哪怕是最基本的OpenCV I/O功能都需要加速。
为什么需要高层次综合?
赛灵思推出的Vivado HLS是一款软件编译器,旨在将C、C++或SystemC编写的算法转变为针对用户定义时钟频率和赛灵思产品系列器件优化的RTL。在C/C++程序解释、分析和优化方面,它与x86处理器的编译器具有相同的核心技术基础。这种相似性有助于从台式机开发环境快速移植到FPGA实现。您选择目标时钟频率和器件后,无需用户输入,Vivado HLS会默认生成RTL实现。此外,Vivado HLS与其它任何编译器一样,也分不同的优化级别。由于算法最终执行目标是定制的微型架构,因此Vivado HLS可实现的优化级别比传统的编译器具有更精细的粒度。传统的针对处理器的软件设计O1 – O3优化理念被架构探索要求所取代,这些要求与用户技术相结合,指导Vivado HLS创建尽可能出色的实现方案,满足特定算法的功耗、面积占用和性能要求。
图2给出了HLS编译器的用户设计流程。从理念上讲,用户提供C/C++/SystemC算法描述,编译器就能生成RTL实现。程序代码转化为RTL的过程分为四大阶段:算法规范、微型架构探索、RTL实现和IP封装。
加速算法C到IP集成
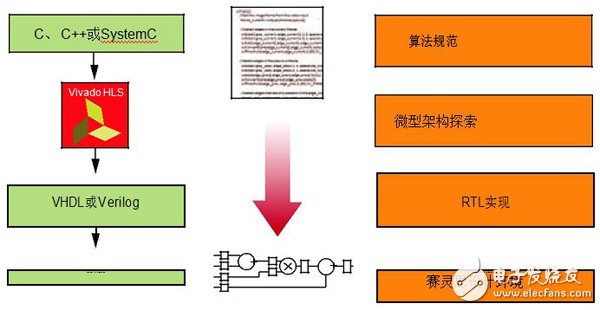
图2 高层次综合设计流程
算法规范阶段是指将针对FPGA架构的软件应用开发。该规范可在标准桌面软件开发环境中,全面利用赛灵思提供的OpenCV等软件库进行开发。除了支持以软件为中心的开发流程外,Vivado HLS还提升了从RTL到C/C++的提取验证速度。用户能用原软件进行全面的算法功能验证。通过Vivado HLS生成RTL后,生成的设计代码类似于传统软件编译器生成的处理器汇编代码。用户可在汇编代码级进行调试,但这一步并不是必需的。
虽然Vivado HLS能处理几乎所有针对其它软件编译器的C/C++代码,但代码有一个限制。在用Vivado HLS编译代码到FPGA过程中,用户代码不能包含任何运行时动态存储器分配。与算法绑定于单个存储器架构的处理器不同,FPGA实现采用特定算法的存储器架构。通过分析阵列和变量的使用模式,Vivado HLS能确定哪些物理存储器布局和存储器类型最适合算法的存储和带宽要求。这种分析工作的唯一要求就是在C/C++代码中明确描述算法使用的所有存储器阵列。
从C/C++转为优化的FPGA实现的第二步就是微型架构探索。在这一阶段,您可运用Vivado HLS编译器优化来测试不同的设计,以找到适当的面积和性能组合。您可在不同性能点实现相同的C/C++代码,无需修改源代码。Vivado HLS编译器优化或要求规定了算法不同部分的性能如何描述。
Vivado HLS编译器流程的最后两步就是RTL实现和IP封装。这是Vivado HLS编译器中自动进行的两步,不需要用户具备RTL方面的知识。针对赛灵思产品组合中不同器件的RTL创建优化细节内置在编译器中。在此阶段,为满足需求,我们提供了经过全面测试和验证的按钮式工具,能生成基于时序和基于FPGA架构的RTL。Vivado HLS编译器的输出自动封装为IP-XACT等其它赛灵思工具能接受的格式,因此无需进行其它操作,就可在Vivado中使用HLS生成的IP核。
赛灵思的OpenCV库为用Vivado HLS进行设计优化提供了捷径。这些库预先特性描述后能提供1080p分辨率的像素处理功能。引导Vivado HLS编译器进行优化的细节已嵌入在这些库中。这样,您就能快速自如地将桌面环境中的OpenCV理念应用迭代为Zynq SoC上运行的OpenCV应用,均可在ARM处理器和FPGA架构上操作。
图3概述了用OpenCV进行运动检测应用开发流程。该设计的目的就是通过比较当前帧和前一帧来检测视频流中的移动物体。算法的第一阶段要检测前后两帧的边缘。数据缩减运算(data-reduction operation)便于分析连续帧之间的相对变化。边缘信息提取出来后,通过边缘对比可以检测出当前图像中出现而前一图像中不存在的边缘。检测出来的新边缘则构成运动检测掩膜图像。最新边缘检测结果在当前图像上凸显前,应考虑到图像传感器噪声的影响。各帧的噪声可能不同,会导致运动检测掩膜图像中出现随机错误边缘。因此我们必须过滤图像,减少噪声对算法质量的影响。
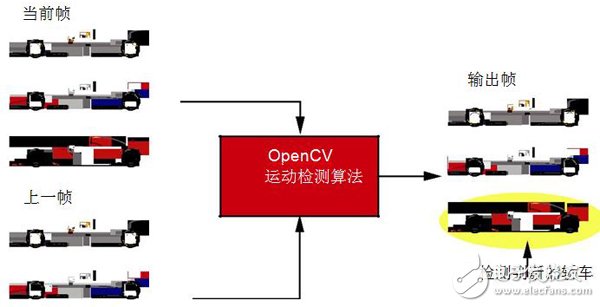
图3 OpenCV算法库开发的运动检测应用实例
在该应用中,可通过在运动检测掩膜图像上采用7x7中值滤波器来降噪。中值滤波器的主要就是取7x7相邻像素窗口的中值,然后将中值作为窗口中心像素的最终值进行报告。降噪后,运动检测掩膜图像结合于实时输入图像并用红色凸显出运动边缘。
您可全面实现应用,运行在ARM处理子系统上,采用Zynq SoC源代码映射,如图4所示。实现过程中仅有的硬件元素就是cvget-frame和showimage函数。这两个视频I/O函数用FPGA架构中的赛灵思视频I/O子系统实现的。在cvgetframe函数调用时,视频I/O子系统的输入端负责处理所有细节,从HDMI接口抓取并解码视频流,再把像素数据存入DDR存储器。Showimage函数调用时,该子系统负责将像素数据从DDR存储器传输到视频显示控制器,以驱动电视机或其它符合HDMI标准的视频显示设备。
Vivado HLS优化的、支持硬件加速的OpenCV库能将图4中的代码移植到FPGA架构中的60fps实时像素处理流水线上。OpenCV库为需要硬件加速的OpenCV元素提供基础功能。如果没有硬件加速,也就是说如果仅在ARM处理器中运行所有代码的话,那么该算法吞吐量仅为每13秒1帧(也就是0.076fps)。图5显示了Vivado HLS编译后的应用的新映射。请注意,原系统的视频I/O映射可重复使用。此前正在ARM处理器上执行的算法的计算内核,现在可编译到多个Vivado HLS生成的IP模块中。这些模块连接至Vivado IP Integrator中的视频I/O子系统,针对60fps、1080p的视频处理进行了优化。
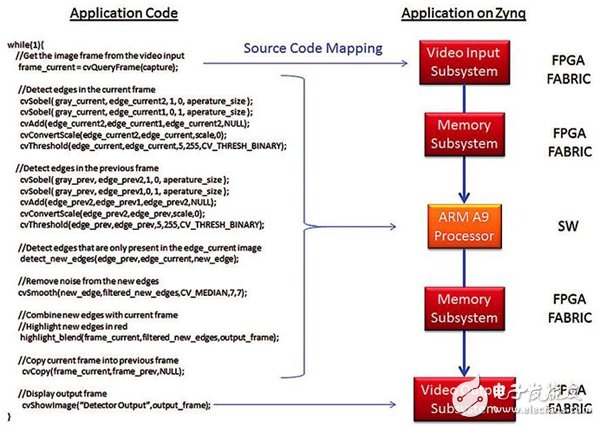
图4 Zynq SoC上采用ARM处理器的运动检测
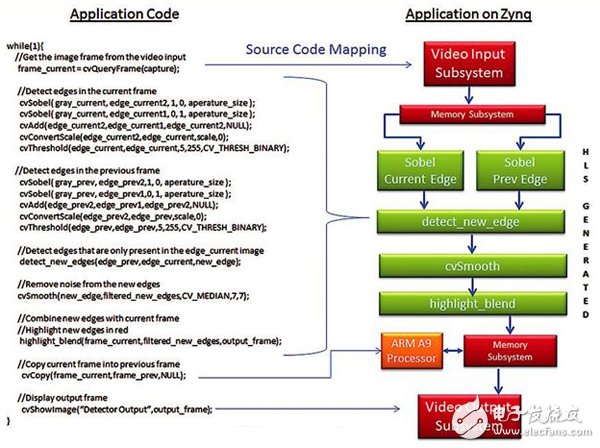
图5 采用可编程架构的Zynq SoC上的运动检测
Zynq SoC和Vivado设计套件提供的All Programmable环境非常适合以最新高分辨率视频技术所要求的高数据处理速率运行的嵌入式视觉系统的设计、原型设计和测试。采用OpenCV中的开源库集是在较短开发时间内实现高标准计算机视觉应用的最佳选择。由于OpenCV库用C++编写,因此我们用Vivado HLS创建的源代码能高效转换为Zynq SoC FPGA架构中的硬件RTL,并可用作方便易用的处理加速器,且不影响OpenCV最初设想的设计环境的灵活性。
-
用OpenCV和Vivado HLS加速基于Zynq SoC的嵌入式视觉应用开发2014-04-21 0
-
嵌入式视觉系统开发过程有什么技巧?2019-08-15 0
-
基于Zynq的嵌入式开发流程2021-08-23 0
-
ZYNQ嵌入式系统的开发流程2021-10-27 0
-
嵌入式开发板开发与SOC系统开发有哪些不同之处呢2021-12-27 0
-
嵌入式机器视觉系统优化研究2012-08-13 624
-
ARM嵌入式Linux系统开发详解2016-03-17 727
-
玩转Xilinx嵌入式视觉开发者专区 让视觉系统开发更加简单2017-11-10 1015
-
嵌入式视觉系统的构建模块2017-02-08 1679
-
基于嵌入式系统开发的模式与流程2017-10-30 938
-
嵌入式机器视觉系统设计2021-07-30 955
-
(网盘)ARM嵌入式Linux系统开发详解2021-08-04 1302
全部0条评论

快来发表一下你的评论吧 !
