

基于FPGA的神经网络算法的设计
FPGA/ASIC技术
描述
随着4C 技术的迅猛发展,以及近十多年来智能控制技术的成就,智能控制在工业用仪器仪表和信息电器( IA)产业中得到了广泛应用,其实现手段也趋于多样化。采用FPGA 实现控制器与使用冯·诺伊曼(VonNeumann)结构的微控制器(MCU)相比,具有信息流并行性、快速性、灵活性和易于扩展等特点。特别在实现复杂智能控制策略时,由于微控制器只能顺序执行程序,随着算法复杂程度的提高,执行速度必将受到限制。FPGA 可固件串行与并行实现算法,从本质上提高了处理速度,对实时性要求较高的智能控制过程来说是一种有效的实现途径。
随着FPGA技术的不断发展,各种智能控制策略的FPGA 固核实现的研究随之活跃。Henriette Ossoing等人完成了神经网络的FPGA 实现并应用于监控和诊断系统中[1] ,Cirstea Marcian 等人将基于FPGA 的神经网络控制器用于驱动电机。在第二次数字浪潮涌现之际,FPGA 的灵活可编程性等特点非常适合具有生命周期短、批量大的数字消费类电子产品的研制开发。
单神经元PID 控制器是一种具有自学习能力和自适应能力的良好控制器, 它不但结构简单、学习算法物理意义明确、计算量小,参数调整容易,且能适应环境变化,具有较强的鲁棒性,比较适合实际使用。仍是实际工业过程中广泛采用的一种比较有效的控制方法。但当被控对象存在非线性和时变特性时,传统的PID 控制器往往难以获得满意的控制效果。神经网络以其强大的信息综合能力为解决复杂控制系统问题提供了理论基础,许多学者也通过软件仿真的形式验证了神经网络控制的可行性并提出了一些新的算法,但由于目前没有相应的硬件支持,只通过软件编程,利用串行方法来实现神经网络控制必然导致运算速度低,难以保证实时控制。而正如前文锁说的FPGA结构灵活、通用性强、速度快、功耗低,用它来构造神经网络,可以灵活地实现各种运算功能和学习规则,并且设计周期短、系统速度快、可靠性高。足以弥补PID控制器出现的各种问题。
本文主要介绍了用FPGA实现单神经元自适应PID控制器的方法,并对基于BP神经网络整定的PID控制器的FPGA设计做了概述。
神经元自适应PID控制器的基本原理和算法
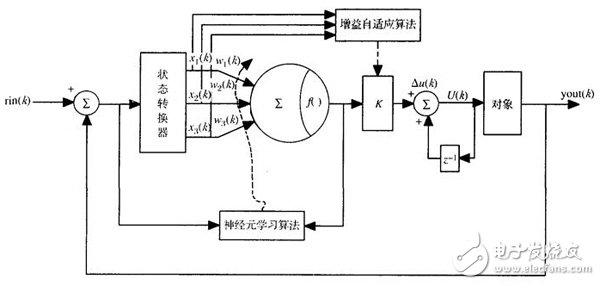
单神经元PID控制器的结构
三输入单神经元模型。其中x1,x2,x3是输入量,w1、w2、w3是对应的权值,K为比例系数。
与传统PID控制器经离散处理后的增量表达式
y(k)=kie(k)+kp(e(k)-e(k-1)+kd(e(k)-2e(k-1)+e(k-2))
比较而知,权值w1、w2、w3分别对应于传统PID控制器的ki,kp和kd。
学习算法
经过大量的实际应用,实践表明PID参数的在线学习修正主要与芿(k)和e(k)有关。因此可将单神经元自适应PID控制算法中的加权系数学习修正部分进行修改。
本文里用FPGA实现的单神经元学习算法就采用了这种基于改进规则的方法。
神经元算法在FPGA上的实现
FPGA上浮点数的运算
浮点加、减、乘、除运算单元的设计
神经元PID算法离不开浮点运算,浮点运算在高级语言中使用很方便,但是通过硬件来实现就比较复杂,所以大多数的EDA软件目前还不支持浮点运算,浮点运算器件只能自行设计,其中主要考虑的是运算精度、运算速度、资源占用以及设计复杂度。
浮点数的加法和减法需要经过对阶、尾数运算、规格化、舍入操作和判断结果正确性5个步骤,整个运算过程由op_state状态机控制,op输入端决定运算法则(0为加法,1为减法),a、b两端分别输入24位浮点数格式的加数和被加数,经过float_add_minus模块的对阶、尾数加(减)、舍入操作和判断结果正确性四步运算,再由result_ normalization模块规格化处理后输出。
浮点乘法相对比较简单,两个浮点数相乘,其乘积的阶码是两个数的阶码之和,乘积的尾数是两个数尾数的乘积,符号是相乘数符号的异或,结果一样需要规格化。
同理,浮点除法运算中,商的阶码是两个数的阶码之差(被除数减除数),商的尾数是两个数尾数的商,符号是两个数符号的异或,注意这里结果的规格化与以往不同,是向右规格化操作。
在具体实现中,乘法器的尾数乘积运算采用了booth算法,除法器的尾数相除运算采用了移位相减的方法。
二进制与十进制浮点数相互转换电路的设计
系统输入值、从传感器反馈回来的系统输出值以及送给DAC的输出控制量都不是上述二进制的浮点数类型,因此就需要能够将两种类型的数据进行相互转换的电路。完成二进制浮点数转换成十进制浮点数的全部操作所需要的时钟数取决于二进制浮点数的大小,最少232个,最多1069个;而十进制浮点数转换成二进制浮点数时,不论浮点数的大小,都只需要194个时钟周期。
神经元算法在FPGA上的实现
有了以上加、减、乘、除浮点运算模块以及进制转换模块,要实现神经元算法只需合理地把他们组织到一起。在FPGA里,是通过一个状态机来完成这一功能的。状态转换图如图3所示,在图中每个标有计算字样的状态里,所有运算都是并行完成的,大大节省了运算时间。图中的START信号可以由微控制器给出,需要注意的是,并不只是在最后的状态里START=0才使状态机复原到IDLE状态,实际情况是,任意时刻只要START=0,状态机都会复原。
使用 Synplify Pro 7.1在Xilinx Virtex2 XC2V1500fg676-4上实现了该系统的综合,时钟频率为98.4MHz,LUT资源占用率为76%。
基于BP神经网络整定的PID控制器的FPGA设计概述
基于BP(Back Propagation)网络的PID控制系统参数整定结构,控制器由两部分构成:
(1) 经典的PID控制器:直接对被控对象进行闭环控制,三个参数kp、ki、kd为在线调整方式;
(2)神经网络:根据系统的运行状态,调节PID控制器的参数,以期达到某种性能指标的最优化。即使输出层神经元的输出状态对应于PID控制器的三个可调参数kp、ki、kd,通过神经网络的自学习、加权系数调整,使神经网络的输出对应于某种最优控制率下的PID控制器参数。
用FPGA实现BP神经网络,除了各个浮点运算模块之外,还需要实现隐层神经元的活化函数——正负对称的Sigmoid函数和输出层神经元的活化函数——非负的Sigmoid函数:
其中超越函数ex的实现,常用的有两大类:一是多项式迭代,该方法实现速度快,但需要乘法器,当计算精度较高时,硬件成本大;二是移位加迭代,此方法只需加法器,结构简单易于实现,但实现速度慢。不过还有一种采用分段线性化的方法,虽然实现容易,但是精度较低。笔者拟在现有浮点四则运算模块的基础上,采用指数函数幂级数展开式前n项和的形式实现超越函数ex。这虽然也是采用了多项式迭代的方式,但采用FPGA实现,可以在保证精度的前提下,减少硬件成本。有了这一模块后,经过合理安排BP算法的运算顺序,就可以在FPGA上实现基于BP神经网络整定的PID控制器了。
结语
当今神经网络的应用大多以软件方式完成核心算法,但受限于微处理器(或DSP)工作频率太慢或PC机体积较大的弱点,难以大规模应用。鉴于此,本文提出了一种基于FPGA、以硬件方式完成神经网络算法的方案,在保证运算精度的前提下,运算速度可比同频率的处理器以软件方式实现快上百倍。另外,文中各个浮点运算模块的实现还有一些有待优化的地方,因此可以在硬件资源上更为节省。由此可见,硬神经网络是解决其学习速度慢、满足实时控制需要的必由之路。本文提出了一种用FPGA实现神经元自适应PID控制器的方案,采用modelsim 5.6d进行仿真验证并在Synplify Pro 7.1平台上进行综合,结果表明该方案具有运算速度快、精度高和易于实现的特点。
参考文献:
[1]舒怀林。PID神经元网络及其控制系统[M].北京:国防工业出版社,2006.2.
[2]徐光辉,程东旭等。基于FPGA的嵌入式开发与应用[M].北京:电子工业出版社,2006.9.
[3]林灶生,刘绍汉等。verilog FPGA芯片设计[M].北京:北京航空航天大学出版社,2006.7.
[4]韩少锋,王***等,基于FPGA的神经元自适应PID控制器设计[J].电子设计应用,2005.2:72-74.
[5]李昂,王沁等。基于FPGA的神经网络硬件实现方法[J]北京科技大学学报,2007.(1):90-95.
[6]FAIEDH H,GAFSI Z,TORKI K,et al.Digital hardware implementation of a neural network used forclassification[C].Proceedings of the 16th International Conference on Microelectronics.Tunis,2004:551-553.
[7]4C datasheet +_2235680.html.
-
卷积神经网络的介绍 什么是卷积神经网络算法2023-08-21 3685
-
什么是神经网络?什么是卷积神经网络?2023-02-23 5282
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 1756
-
如何移植一个CNN神经网络到FPGA中?2020-11-26 5921
-
FPGA芯片用于神经网络算法优化的设计实现方案2020-09-29 6144
-
反馈神经网络算法是什么2020-04-28 2956
-
神经网络和反向传播算法2019-09-12 2160
-
如何设计BP神经网络图像压缩算法?2019-08-08 3986
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 3391
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 4247
-
遗传算法 神经网络 解析2013-05-19 8930
-
神经网络教程(李亚非)2012-03-20 58154
-
BP神经网络图像压缩算法乘累加单元的FPGA设计2009-11-13 1847
全部0条评论

快来发表一下你的评论吧 !
