

关于基于Xilinx FPGA 的高速Viterbi回溯译码器的性能分析和应用介绍
FPGA/ASIC技术
描述
新一代移动通信系统目前主要采用多载波传输技术, 基带传输速率较3G 有很大提高, 一般要求业务速率能达到30 Mb/ s 以上。约束长度卷积码以及Viterbi译码器由于其性能和实现的优点, 在新一代通信系统中仍然占有一席之地。这就要求进一步提高Viterbi 译码器的译码速率, 同时优化Viterbi 设计以减少由速率提高和约束长度的增加带来的硬件实现复杂度。
1 Viterbi 译码器基本结构
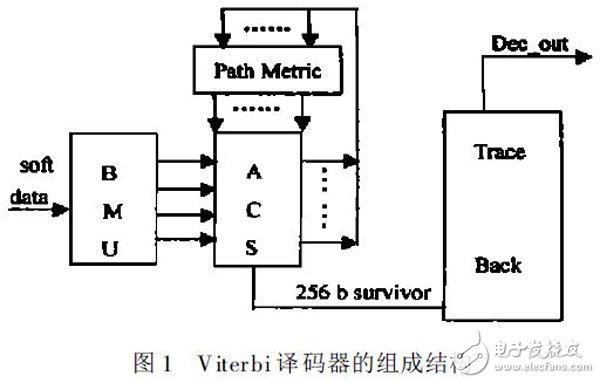
Viterbi 译码器主要由分支度量计算( BMU ) , 度量累积存贮( PathMet ric) , 度量比较判断( ACS) 以及回溯译码( T raceBack) 4 个模块组成[ 1] , 如图1 所示。本文优化主要针对约束长度为9 的1/ 2 卷积码, 生成多项式为561( oct) , 753( oct) 。
BMU ( Branch Met ric Unit ) 模块计算接收的2 个软信息与4 种可能的编码输出的欧式距离, 作为分支度量送入ACS 模块。ACS( Add_ Compar e_ Select ) 模块根据编码方式和状态转移将分支度量和256 状态的度量分别进行累积相加, 得到进入下一时刻的新度量, 然后比较到达下一时刻同一状态的2 种度量大小, 选择小的度量, 同时生成各状态的幸存比特输出。Tr ace Back 回溯模块由ACS 生成的当前时刻的判决比特回溯L个时刻( L 为回溯深度) , 得到L 时刻前的状态和译码输出。
2 Xilinx Virtex II 的结构和功能
Virtex II 是Xilinx 公司的高性能系列FPGA。最高规模能达到8 000 000 门, 内部时钟高达400 MHz。存贮单元具有高达到3 M 容量的真正双端口Block Ram。运算单元中包括最多168 b 的专用乘法器。Virtex II 中的可配置单元为CLB ( Config urable Log ic Bloccks) 。CLB 中的资源可以灵活配置成多种结构。包括实现查找表, 移位寄存器等功能。在存贮资源不够的时候, CLB 也可以配置为分布式的Ram[ 2] 。
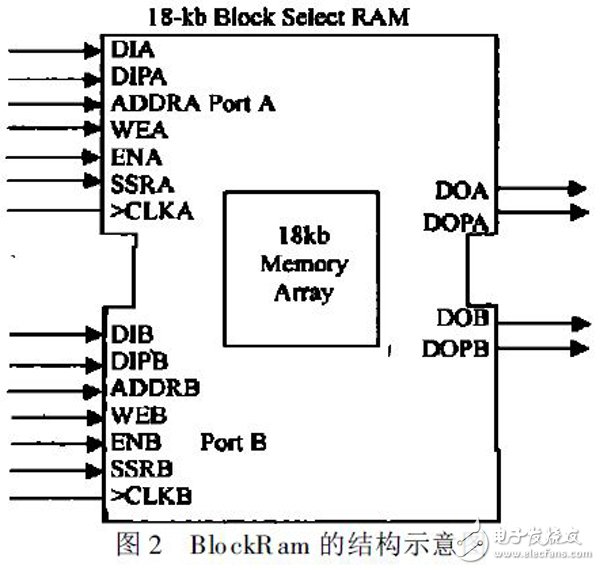
双口BlockRam 是Viterbi 译码器中实现回溯译码的主要模块, 其端口如图2 所示。可以看出Block-Ram 具有2 套独立的地址和数据输入、输出线, 独立的端口使能、写使能控制线, 而且2 个端口各自的时钟输入可以不同。这些结构保证了Blo ckRam 是一个完全真正双端口操作的存贮器。Virtex II 系列中BlockRam 最多有168 个, 每个容量为18 k。可以配置成不同的数据宽度和深度。同时BlockRam 的访问时间只有3. 3 ns, 能够保证高速的存取要求。
3 基于Xilinx BlockRam 的回溯优化方案
3. 1 回溯算法的原理和存在的问题
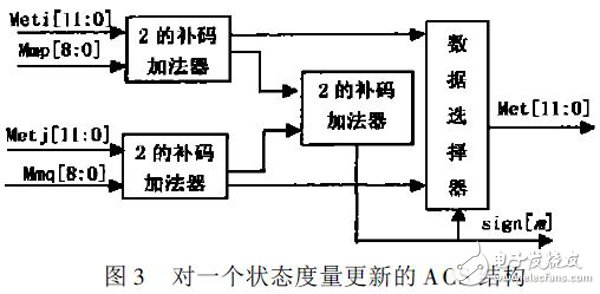
在Viterbi 译码模块中, ACS 和TraceBack 是最核心的模块。ACS 需进行大量的累积和比较运算,TraceBack 需进行多步回溯运算。当Viterbi 译码器译码状态为256 时, 这些运算都需要占用大量的时间和资源。对于256 状态的1/ 2 卷积码的译码, 需要512 个加法器, 512 个比较器和选择器来完成累加度量、比较度量大小, 并选择小的度量作为该状态新的度量。对一个状态度量更新的操作如图3 所示。
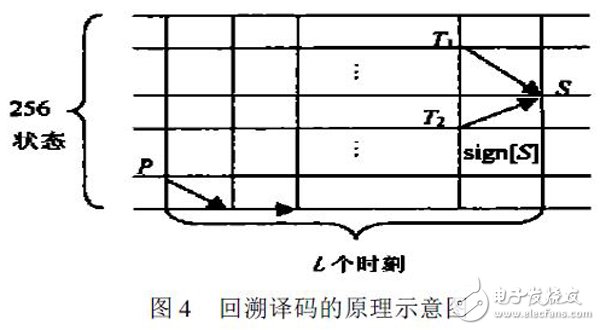
ACS 得出的256 位的判决比特送入回溯模块进行译码。回溯译码通过寻找在一定深度范围内的最小度量的路径来获得最大似然译码。实现中采用截尾译码, 每一个时钟到来的时候, ACS 模块会送入当前时刻各状态的幸存比特( 如图4 中的Sig n[ S] ) , 从这些幸存比特可以得到由当前各状态往回L 时刻的最小路径上, 前一时刻经过的状态( 如图4 中, Sig n[ S] =0, 最小路径上前一时刻状态为T 1, 否则为T 2) 。如果存贮了L 个时刻的256 位状态幸存比特, 就可以从当前时刻的某一状态开始回溯L 时刻得到对应的最小路径起始状态( 如图4 中从S 状态回溯L 时刻得到初始的P 状态) 。实际上无论从当前的何种状态开始回溯, 当回溯深度L 为5~10 倍的编码寄存器数时, 所得到的L 时刻前的初始状态都是相同的( 当采用约束长度为9 的卷积码, L 最少应为40) [ 3] 。
按照上述的回溯方案对256 状态的卷积码进行译码时, 会占用大量的资源, 在Virtex II 系列中的Xc2v 3000 上综合时如果对ACS 模块也不做任何处理的话甚至会产生资源不够的情况。除此之外这种回溯要求在一个时钟周期内进行L 步回溯操作, 结果导致速率达不到30 Mb/ s 的要求。
3. 2 基于Xilinx BlockRam 的回溯优化方案
虽然一个时钟周期回溯L 步在30 MHz 的时钟速率下不能完成, 但是如果回溯前的开始状态已经是确定的最小路径中的状态, 那么每回溯一步就对应一个译码输出, 这样的输出速率就能达到高速率。最后只需对L 步的回溯译码输出做一个L 深度的倒序( LIFO)就能得到正确顺序的译码输出。
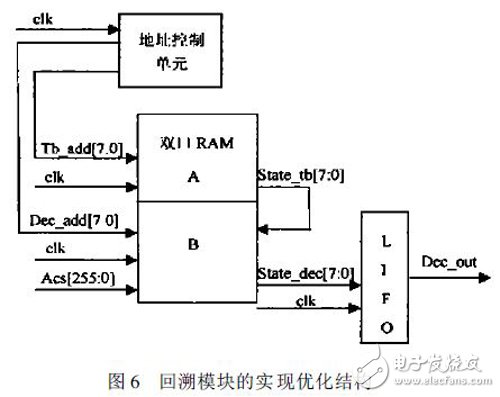
Xilinx Virtex II 的双端口BlockRam[ 2] 能够真正地对2 个端口进行不同的读写操作。这种结构能很好的吻合改进回溯算法的要求。应用这种结构可以存贮ACS 送入的幸存比特, 同时通过控制地址的读写来实现写入幸存比特和回溯译码读出同步进行。回溯模块存贮管理原理如图5 所示。回溯模块的实现结构如图6 所示。
在图5 中, 1, 2, 3 分别为3 块位宽为256, 深度为64 的双端口BlockRam, 实现中将3 块合为1 块位宽256, 深度192 的Blo ckRam。Blo ckRam 的2 个口设为A 口和B 口。A 口为只读口, 每个时钟到来时, 将地址T b_ add 指向的ACS 幸存比特读出, 并回溯计算出前一时刻的状态。B 口为读写口, 且读操作优于写操作。当时钟到来时, 先根据当前的状态和地址Dec_ add所读出的幸存比特计算出前一时刻的状态和译码输出, 然后在相同的时钟周期内在同一地址处将ACS新产生的幸存比特写入。
图5 中细箭头表示译码读出和ACS 幸存比特写入地址( Dec_ add) 的起始位置和方向, 粗箭头表示回溯读出前一时刻状态的读地址( T b_ add) 的起始位置和前进方向。每64 个时钟开始时, 回溯读出的起始状态设为0, 而译码读出的初始状态为上一个64 个时钟结束时回溯得到的初始状态( 虚线箭头所示) 。每64 个时钟开始的时候, 双端口BlockRam 的2 个读写地址的初始值按照图示的规律循环右移, 且前进的方向每64 个时钟反向一次。到64×6 个时钟后恢复初始的地址值和方向。
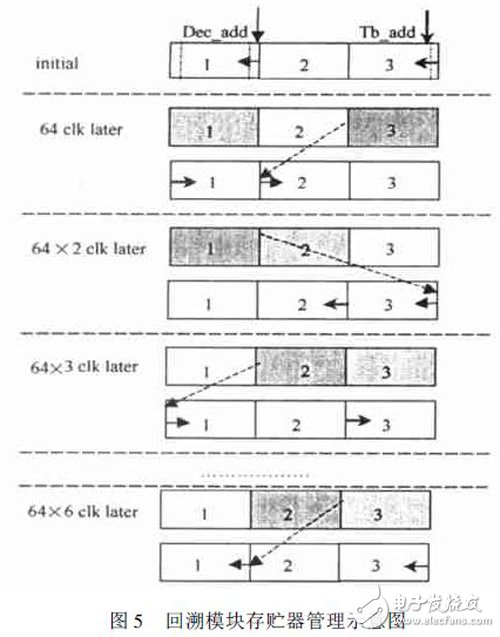
由图5 中可以看出, 64×3 个时钟后, 将对块2回溯得到的状态作为初始状态开始对块1 中的幸存比特进行回溯译码, 这时才开始真正的译码输出。所以译码延时为192 个时钟周期, 译码的回溯深度为64 个时钟周期。
4 性能分析
本文的优化方案在Xilinx ISE 5 集成环境下进行Verilog 描述以及综合和布局布线, 并使用Modelsim7 对约束长度为9、回溯深度为64 的Viterbi 软译码器在信噪比为2. 8 db 的高斯白噪声信道中进行了后仿真, 接收误码率小于10- 7。
采用不同约束长度的译码器在ISE 5. 2 环境下进行综合和布局布线后, 速率和面积的比较结果如表1所示。仿真使用的FPGA 为Xilinx Virtex II 系列中的Xc2v 3000[ 2] 。
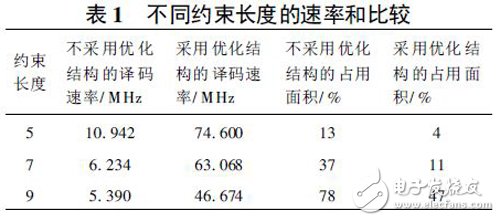
由表1 可以得出, 当采用基于Xilinx 双口Block-Ram 的优化方案时, 可以明显地减少Viterbi 软译码器的占用面积, 大大提高软译码速率。在使用约束长度为9 的卷积码时, 优化后Viterbi 软译码器的面积只占用Xc2v3000 的47%, 其速率能达到40 Mb/ s 以上。
本设计已经成功下载于Xilinx Xc2v 3000 中, 正常运行在30. 72 MHz 的系统译码时钟下。
-
什么是硬判决和软判决Viterbi 译码算法 ?2008-05-30 18034
-
应用于LTE-OFDM系统的Viterbi译码在FPGA中的实现2009-09-19 4291
-
基于IP核的Viterbi译码器实现2010-04-26 2615
-
求教ise 14.7中的viterbi译码器破解2017-05-04 5440
-
基于FPGA的Viterbi译码器算法该怎么优化?2019-11-01 3290
-
基于FPGA的Viterbi译码器该怎样去设计?2021-05-07 1297
-
基带芯片中Viterbi译码器的研究与实现2009-08-13 1078
-
卷积码的Viterbi高速译码方案2010-07-21 1091
-
从FPGA实现的角度对大约束度Viterbi译码器中路径存储2007-08-15 1298
-
Viterbi译码器回溯算法实现2011-05-28 1285
-
基于ASIC的高速Viterbi译码器设计2017-11-11 1216
-
基于FPGA的指针反馈式低功耗Viterbi译码器的性能分析和设计2019-10-06 967
-
通过采用FPGA器件设计一个Viterbi译码器2019-04-24 3855
-
浅谈FPGA的指针反馈式低功耗Viterbi译码器设计2021-04-28 2802
-
关于Actel 的FPGA的译码器的VHDL源代码2021-09-16 1173
全部0条评论

快来发表一下你的评论吧 !
