

bcd码和ascii码互相转换
电子常识
描述
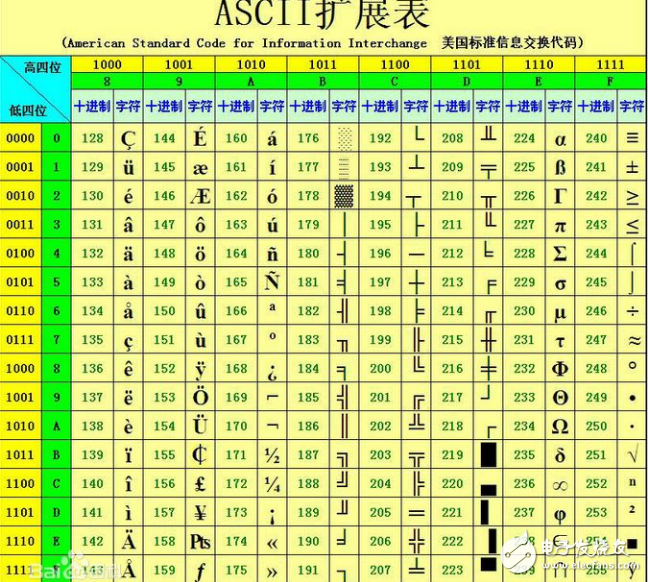
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
请注意,ASCII是American Standard Code for Information Interchange缩写,而不是ASCⅡ(罗马数字2),有很多人在这个地方产生误解。
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
美国标准信息交换代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。起始于50年代后期,在1967年定案。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,它已被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母。
BCD码(Binary-Coded Decimal)亦称二进码十进数或二-十进制代码。用4位二进制数来表示1位十进制数中的0~9这10个数码。是一种二进制的数字编码形式,用二进制编码的十进制代码。BCD码这种编码形式利用了四个位元来储存一个十进制的数码,使二进制和十进制之间的转换得以快捷的进行。这种编码技巧最常用于会计系统的设计里,因为会计制度经常需要对很长的数字串作准确的计算。相对于一般的浮点式记数法,采用BCD码,既可保存数值的精确度,又可免去使电脑作浮点运算时所耗费的时间。此外,对于其他需要高精确度的计算,BCD编码亦很常用。
由于十进制数共有0、1、2、……、9十个数码,因此,至少需要4位二进制码来表示1位十进制数。4位二进制码共有2^4=16种码组,在这16种代码中,可以任选10种来表示10个十进制数码,共有N=16!/[10!*(16-10)!]等于8008种方案。常用的BCD代码列于末。
BCD与ASCII码互转
最近由于项目需要,需要将BCD编码转换为对应的字符串,下面为C语言实现,经测试好用!
[cpp] view plain copy/*BCD 与 ASCII码转换*/
/*******************************************************************
函数名: asc2bcd
功能描述:将ascii码转换为bcd码
参数:
bcd:转换后的BCD码
asc:需转换的ASCII码串
len:需转换的ascii码串长度
返回值: uint32
0:成功
其他:失败
********************************************************************/
uint32 asc2bcd(uint8* bcd, const uint8* asc, uint32 len);
/*******************************************************************
函数名: bcd2asc
功能描述:将bcd码转换为ascii码串
参数:
asc:转换的ASCII码串
bcd:需转换的BCD码
len:需转换的BCD码长度
返回值: uint32
0:成功
其他:失败
********************************************************************/
uint32 bcd2asc(uint8* asc, const uint8* bcd, uint32 len);
[cpp] view plain copy#include 《assert.h》
#include “utils.h”
//基于查表实现BCD与Ascii之间的转换
static uint8 bcd2ascii[16] = {‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’};
static uint8 ascii2bcd1[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
static uint8 ascii2bcd2[6] = {0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F};
[cpp] view plain copyuint32
ASC2BCD(uint8 *bcd, const uint8 *asc, uint32 len)
{
uint8 c = 0;
uint8 index = 0;
uint8 i = 0;
len 》》= 1;
for(; i 《 len; i++) {
//first BCD
if(*asc 》= ‘A’ && *asc 《= ‘F’) {
index = *asc - ‘A’;
c = ascii2bcd2[index] 《《 4;
} else if(*asc 》= ‘0’ && *asc 《= ‘9’) {
index = *asc - ‘0’;
c = ascii2bcd1[index] 《《 4;
}
asc++;
//second BCD
if(*asc 》= ‘A’ && *asc 《= ‘F’) {
index = *asc - ‘A’;
c |= ascii2bcd2[index];
} else if(*asc 》= ‘0’ && *asc 《= ‘9’) {
index = *asc - ‘0’;
c |= ascii2bcd1[index];
}
asc++;
*bcd++ = c;
}
return 0;
}
[cpp] view plain copyuint32
BCD2ASC (uint8 *asc, const uint8 *bcd, uint32 len)
{
uint8 c = 0;
uint8 i;
for(i = 0; i 《 len; i++) {
//first BCD
c = *bcd 》》 4;
*asc++ = bcd2ascii[c];
//second
c = *bcd & 0x0f;
*asc++ = bcd2ascii[c];
bcd++;
}
return 0;
}
[cpp] view plain copyint main(void)//测试程序
{
const unsigned char ascii[12] = {‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘A’, ‘B’, ‘C’};
unsigned char bcd[6];
ASC2BCD(bcd, ascii, 12, 0);
int i = 0;
printf(“ascii = %s\n”, ascii);
for(; i 《 6; i++) {
printf(“bcd = 0x%.2x\n”, bcd[i]);
}
/*
unsigned char ascii[13] = {0};
const unsigned char bcd[6] = {0x01, 0x23, 0x45, 0xCD, 0xEF, 0xAB};
BCD2ASC(ascii, bcd, 6, 0);
printf(“ascii = %s\n”, ascii);
*/
return 0;
}
-
如何使用ASCII码进行编码2024-11-10 3151
-
什么是BCD码2022-09-07 18868
-
余3码至8421BCD码的转换_8421BCD码转换成余3码2018-03-02 202363
-
关于BCD码转换的问题2014-03-08 8252
-
ASCII码转换2012-05-31 2811
-
ASCII码速查工具2010-07-02 1322
-
一种BIN 码与BCD 码转换电路的设计与实现2010-02-22 1049
-
ASCII码和EBCDIC码2009-10-13 5057
-
ascii码表,ascii码对照表2009-06-30 15463
-
ascii码是什么,ascii码字符是什么2009-06-28 22182
-
汉字ASCII码-Unicode码转化器(转换工具)2009-03-15 3344
全部0条评论

快来发表一下你的评论吧 !
