

基于FPGA的双通道的频谱及其在调节磁共振谱仪中的应用方案详解
可编程逻辑
描述
核磁共振(Nuclear Magnetic Resonance,NMR)自从1946年首次观测以来已经成功地应用到物理、化学、生物和医学等诸多领域。与此同时,核磁共振仪器技术也得到了不断的发展,其中核磁共振谱仪被广泛用于化合物的结构测定,定量分析和动物学研究等方面。
核磁共振谱仪通过短时间的高功率射频脉冲激发原子核体系使之偏离平衡状态,然后检测该体系在恢复平衡过程中产生的自由感应衰减信号,经过FFT处理后得到相关的谱信息。目前NMR谱仪普遍使用的检测信号的方法是正交检波技术,它需要两路相检波来区分正负频率,然而当两通道的增益与相位存在微小的不平衡时,谱图上就会产生镜像峰,解决的有效方法是采用相位循环。但对于长期使用、老化或故障造成增益或相位差与理想值偏离较大的仪器,即使采用相位循环也不足以解决问题,这时需要通过手动调节,然而调节到什么程度往往只能凭借经验。
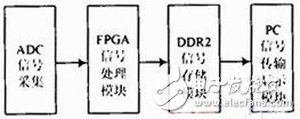
图1 系统框图
本文提出了一种依据双通道的频谱图给出调节依据的方法。系统结构框图如图1所示,通过ADC模块对双通道进行采样,要在频域对信号进行分析,需要得到信号的频域信息,因此在采样之后通过FPGA对信号做FFT变换,然后将得到的频域信息存入DDR2RAM,以便主机通过PCIE接口将数据读入主机内存并进行显示。在调节的时候,可根据频谱图显示的谱峰把I通道的增益和相位适当的调小或者对应的调节Q通道(如图2所示),直到谱峰消失。
1 正交检波原理
如图2所示,正交检波系统由两路检波通道(I通道和Q通道)组成,谱仪接收到的核磁共振信号V(t),首先经过混频器或模拟乘法器与参考信号相乘,对于I,Q通道来说参考信号是相位相差90°的等幅射频信号,分别将两者的乘积作为两通道的输出。
对于分子中只有一种质子的简单情况,根据Bloch方程接收到的核磁共振信号如下式:
V(t)=Acos(ω0+φ)exp(-t/T2) (1)
I通道的参考信号为cosωt,经过混频器与输入信号相乘后为:
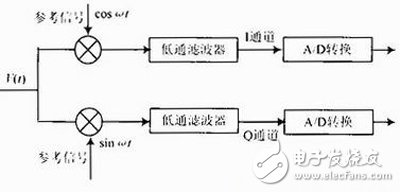
图2 正交检波系统原理图
得到的乘积为两项:第一项为和频分量,经过后面的低通滤波器被滤除掉;第二项为差频分量作为I通道的输出。综上所述I通道的输出为:
对于Q通道,输入为V(t),参考信号为sinωt,通过类似方法可以计算出Q通道的输出为:
然后经过模/数转换分别将I通道和Q通道的数据作为复数的实部和虚部存储下来。
2 FFT算法实现
FFT算法在FPGA上实现的过程中,信号的值、系统的系数和运算中的结果都存储在有限字长的存储单元中,从而导致了设计时的无限精度转变成实现时的有限精度,必将产生相对于原设计系统的误差,严重时会将由于双通道不平衡产生的镜像峰湮灭,从而使整个设计失去意义。
为了实现FFT实时运算,基于FPGA的FFT信号处理模块是关键,并且要求此模块能在频率至少为210 MHz的系统时钟下稳定工作。同时又因为并行的FFT设计需要占用大量的资源,资源使用率过大会制约布局布线后的时序收敛。为了平衡资源与速度间的矛盾,整个设计通过64点FFT并行模块的复用来实现。
2.1 有限字长效应及其优化措施
在FFT算法中,采用蝶形计算,如图3所示。
对于基2时间抽选FFT算法,蝶形公式如下:
图3 基2蝶形单元信号流图
式中:N为FFT点数;Nm和P为两个同迭代次数m有关的量;Xm-1为ADC输出信号经过m-2级蝶形运算得到的计算结果;旋转因子由式(7)给出,每个蝶形包含两个复数乘法。
由于存储单元有限,必须对计算结果截取,进行定点化,但是同时又会引入舍入误差en,这种现象即为有限字长效应。考虑到每个复数乘法相当于4个实数乘法,因此有限字长时复数乘法的实际乘积可以表示为:
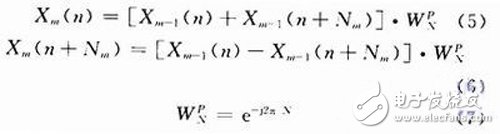
式中e1,e2,e3,e4分别为其对应的实数乘法的舍入误差。因此可进一步建立如图4所示的蝶形计算舍入误差模型。
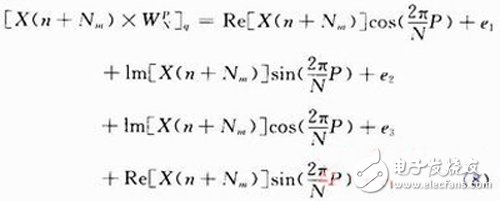
如果用一般的定点计算,信噪比下降,噪声会将产生的镜像峰湮灭,因此必须采取一定的措施减小由定点化产生的误差。考虑到在64点FFT并行模块里点数是固定的,进行蝶形运算时旋转因子是常数,因此可以根据系数的特点对定点化时的阶码做动态调整,在保证无溢出的条件下最大程度的减小噪声。
如图5所示,对比在Matlab中的仿真结果,在没有采取动态调整措施前进行定点化的噪声量级达到±1(见图5(a)),进行动态调整后下降到10-3(见图5(b)),可见采用动态调整进行定点化可以有效地降低由于有限字长效应引起的噪声。
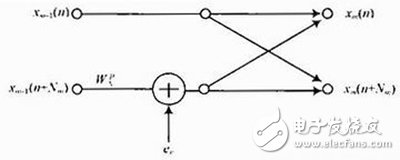
图4 基2频域抽选式碟形单元的舍入误差模型
图6为进行动态调整后在FPGA硬件运行的仿真结果,与软件自带的FFT IP相比误差很小,在输入正弦波的时候可以明显地观察到尖峰,这样的结果足以满足NMR谱仪的信号检测要求。
2.2 64点FFT并行模块资源优化
由于64点FFT模块并行实现,所占用的FPGA逻辑资源太多,在一般的FPGA中难以实现,因此有必要对其进行优化减少所占用的资源。该设计中N是确定的,旋转因子都是常数,蝶形运算中的复数乘法为常系数乘法,根据这个特点,可对使用资源进行优化。
如式(9)所示,64点FFT可分解为384个蝶形运算单元。
n=Nlog N (9)
式中:N为FFT点数;n为所需的蝶形运算单元的个数。
式(5)和(6)各包含1个复数加法运算和1个复数乘法运算,需要2个加法器和4个乘法器实现。但经过如式(10)所示的运算后的复数乘法可用三乘法器实现,因此综合后的资源先比四乘法器架构优化了25%,
(A1+B1i)(A2+B2i)=(A1A2-B1B2)(A1B2-A2B1)i=A1(A2+B2)=B2(A1+B1)+[A1(A2+B2)-A2(A1+B1)] (10)
旋转因子WN的二进制表示可看作是若干项2次幂数相加组合而成的数,那么一个数与WN相乘即可通过在移位操作的基础上执行相应的加法操作来实现。根据正弦函数与余弦函数的对称性,第5阶与第6阶与相乘所占用的乘法器完全可以省略。
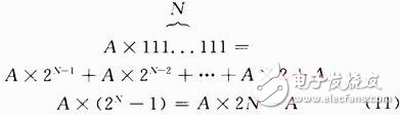
如式(11)所示,在WN的二进制序列中,在不引入噪声的基础上把N个移位寄存器和N-1个加法器的运算用2个移位寄存器和1个减法器来实现。这样不仅可以大大减少硬件资源的消耗,最大的优点是不消耗RAM和乘法器资源,因此速度很快。
2.3 FPGA逻辑资源与性能分析
该设计中的64点并行FFT模块通过在不同系列芯片综合仿真后,系统时钟最高可达285 MHz,完全满足设计要求。所占用的FPGA逻辑资源和性能与Xilinx FFT IPcore比较如表1所示。
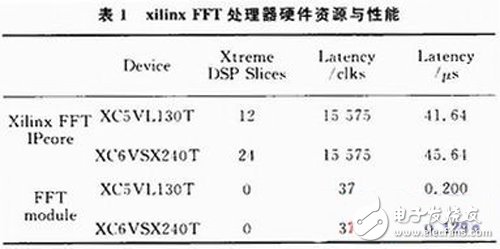
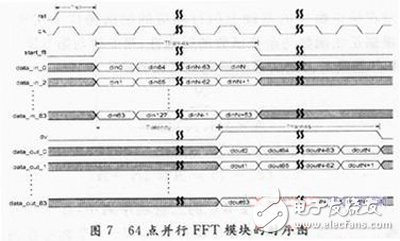
Xilinx公司的ISE集成开发环境可以提供成熟的FFT IP核,但是由于占用大量的DSP Slices,可移植性很差,但该设计中由于没有用到DSP Slices,可移植性很强。图7为64点并行FFT模块的时序图,图中运算器的数据处理时间为1个时钟周期,数据处理的延时Tlatency为37个时钟周期,使得整个运算器的数据处理吞吐率高达656 Gb/s,而数据延时时间仅为0.129 μs,与Xilinx公司和Altera公司已经成熟的FFT处理器相比时延大大减少,提高了FFT处理器实时处理性能。
3 结语
该设计通过对64点并行FFT进行改进,大大提高了信号处理的实时性,所占用的FPGA逻辑资源和有限字长效应引起的噪声也得到了优化,可移植性大大增强。该设计已经完成了硬件电路的设计与调试,结果证明通过双通道频谱图对由于增益与相位不平衡产生的镜像峰进行调节,可大大提高谱仪信号检测的准确性,也使谱仪的应用更加方便。
-
国仪量子推出全球首台AI电子顺磁共振波谱仪2024-10-22 1912
-
磁共振检查常用线圈及分类方法2024-08-21 9724
-
磁共振adc值代表什么2023-09-07 7220
-
核磁共振含油量测定仪的功能特点是怎样的2021-04-15 1577
-
磁共振成像仪梯度模块的设计2017-11-14 1272
-
核磁共振CAT扫描系统解决方案2016-01-06 1187
-
核磁共振谱仪设计求人帮忙2014-03-17 2874
-
DIY核磁共振仪器2013-04-09 5936
-
飞利浦发布全球首台全数字磁共振 Ingenia2012-12-29 3873
-
ARBOR在核磁共振成像仪中的应用2012-12-02 4461
-
核磁共振的副作用2011-03-04 179983
-
基于ARM的一体化核磁共振谱仪2010-11-09 1122
-
核磁共振(NMR)实验2010-07-17 1357
-
EIP在磁共振成像系统中的应用2009-11-30 4381
全部0条评论

快来发表一下你的评论吧 !
