

简述HBM技术的重要性
描述
众所周知,数据处理需求呈指数级增长,芯片技术正奋力攀登至性能极限的巅峰。高带宽内存(HBM)以其开创性的内存堆叠技术独占鳌头,导致其容量需求激增;而传统内存架构在应对此类高性能应用场景时显得捉襟见肘。
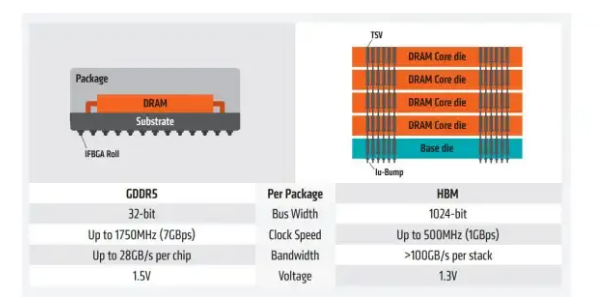
首先,高带宽内存(HBM)技术采用芯片堆叠技术,将多层DRAM芯片通过硅通孔(TSV)和微型凸点(uBump)连接在一起,形成一个存储堆栈(stack)。
图源:Google
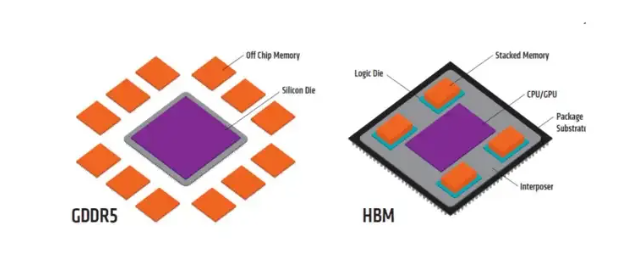
其中,HBM通过将多个堆栈与逻辑芯片(如GPU或CPU)通过硅中介层(Interposer)封装在一起。这种3D堆叠技术实现了高密度存储,从而大幅提升了每个存储堆栈的容量和位宽。
其次,TSV技术是实现3D堆叠的关键。通过在硅芯片中垂直贯穿的导电通路,TSV技术极大地减少了芯片间的连接长度和电阻,提高了数据传输的效率和速度。
或许,在大模型的应用落地过程中,HBM的高带宽、高密度和低功耗特性使其成为了不可或缺的组件。
图源:Google
高带宽:HBM通过堆叠结构和垂直TSV(Through Silicon Via,硅通孔)互连技术,实现了极高的数据传输带宽。这对于需要处理海量数据的大模型和HPC应用至关重要,能够显著提升计算效率,减少数据传输延迟,即所谓的“内存墙”问题。
高密度:相比传统DRAM,HBM在相同的物理空间内能够容纳更多的存储单元,从而提供更高的存储容量。这对于存储千亿参数乃至更大规模的大模型至关重要。
低功耗:HBM的堆叠结构和高效的数据传输方式有助于降低整体功耗,这对于能源敏感的应用场景尤为重要。
小型化:随着电子设备的不断小型化,对内存器件的小型化要求也越来越高。HBM的堆叠封装方式使得其在保持高性能的同时,能够实现更小的体积,满足器件小型化的需求。
除此之外,在人工智能领域,HBM技术能够加速神经网络的训练和推理过程,提高数据处理效率,助力AI算法在复杂任务中展现出更出色的性能。
因此,对于高性能计算而言,HBM则成为了超级计算机、数据中心等核心设施中不可或缺的关键组件,为大规模并行计算提供了坚实的内存基础。
尤其,在图形处理领域,HBM的高带宽特性使得GPU能够更快速地访问和处理图像数据,从而为用户带来更加流畅、逼真的视觉体验。
当然,目前HBM作为一种新兴的内存技术,其重要性则体现在多个维度:
图源:美光科技
极致的数据传输速度:
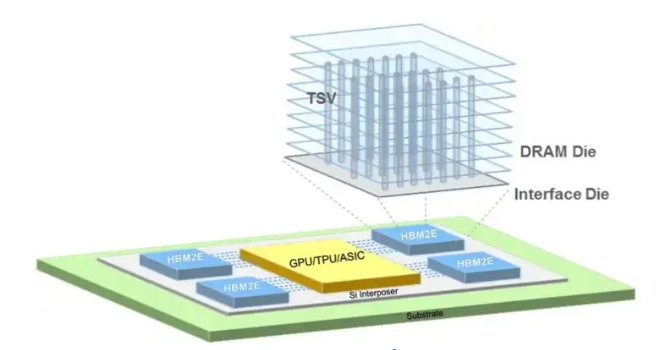
HBM通过垂直堆叠多个DRAM(动态随机存取存储器)芯片于处理器之上,并使用硅通孔(TSV,Through-Silicon Via)技术实现芯片间的直接连接,从而极大地缩短了数据传输的路径。
其设计显著降低了数据传输的延迟,使得HBM的带宽远超传统的DDR(Double Data Rate)内存。
高效的能源利用:
由于HBM减少了数据传输的距离和延迟,意味着在相同时间内可以完成更多任务,从而提高了系统的整体能效。
另外,HBM的功耗管理也更加精细,能够在保证高性能的同时有效控制能耗,这对于能源敏感的应用场景(如移动设备、嵌入式系统等)尤为重要。
强大的扩展性:
HBM架构支持多层堆叠,理论上可以不断增加DRAM芯片的数量来扩展内存容量和带宽,这为未来更高性能的计算需求提供了可能。
适应性广泛:
HBM不仅适用于高性能计算领域,还在图形处理(GPU)、数据中心服务器、边缘计算等多个领域展现出巨大潜力。
在GPU中,HBM可以显著提升图形渲染和计算性能;在数据中心,HBM的高带宽和低延迟特性有助于加速大数据分析、机器学习等任务;在边缘计算场景中,HBM的能效优势则有助于延长设备的续航时间。
推动技术创新和产业升级:
HBM技术的发展不仅促进了内存技术的革新,更成为了驱动整个计算产业链全面升级的关键力量。这一技术的广泛采用,从源头激发了芯片设计的创新活力,促使封装测试技术向更高精度、更高效率迈进,同时引领了系统集成方案的革命性变革。
结语而言:HBM的崛起,不仅是大模型技术进步的必然产物,更是AI时代对高效、紧凑计算系统追求的集中体现。
与此同时,HBM将持续推动AI计算架构的革新,引领技术向更高算力、更低延迟、小型化的方向迈进,为行业创新与应用深化奠定坚实基础。
-
求助,ADC接地的重要性?2024-06-04 7248
-
BGA焊接温度控制重要性2020-03-26 3151
-
Syncer模块的重要性是什么?2020-05-18 2160
-
代码规范的重要性是什么2020-05-19 2087
-
使用ODDR原语的重要性是什么?2020-06-17 3374
-
欠压保护的重要性2021-03-03 4482
-
什么是网络拓扑,它的重要性是什么?2021-03-17 4782
-
机器人控制技术有哪些重要性?2021-06-18 21712
-
论调节阀的重要性2021-09-15 1789
-
ATPG是什么?ATPG有何重要性2021-11-02 3750
-
时钟服务器的重要性是什么?2021-11-08 2139
-
UPS的重要性2021-11-16 1710
-
arm汇编的重要性是什么?2021-11-30 3437
-
POE浪涌保护的重要性是什么?2022-01-14 2587
-
简述钢制储罐防腐的重要性以及如何防腐2022-02-15 922
全部0条评论

快来发表一下你的评论吧 !
