

基于FPGA的BIade Server与主板之间PCI数据交换
FPGA/ASIC技术
描述
新一代机架式服务器Blade Server(刀片服务器),应用iSCSI协议,通过TCP/IP实现网络存储,利用Intemet,可将SCSI数据包传到地球上的任何地方。
笔者着眼于刀片服务器的内部构架和整体方案的介绍,主要论述了基于FPGA的刀片与主板之间PCI数据交换的具体实现方法。
1 刀片服务器系统构架
刀片服务器是一种HAHD(High Availability High Density,高可用高密度)的低成本服务器平台,是专门为特殊应用行业和高密度计算机环境设计的。每一块刀片均由"系统服务器主板+控制板"组成,可以远程启动Windows NT/2000、Linux、Solaris等操作系统。类似于独立的服务器,每块刀片可以没有独立硬盘来存储数据,而是多个刀片共享一个Raid磁盘阵列。在该模式下,每个刀片运行自己的系统,服务于用户指定的不同用户群,相互之间没有关联,不过也可以通过系统软件将这些刀片集合成一个服务器集群,在集群模式下,所有的刀片连接起来提供高速网络环境,实现资源共享,为相同的用户群服务。用户若需提高整体性能,只需在集群中插入新的刀片即可。刀片可热插拔,替换便捷,且维护时间减到最小。
机架中的服务器(刀片)可以通过智能KVM转换板共享一套键盘、显示器和鼠标,以访问多台服务器(刀片),从而便于进行升级、维护和访问服务器上的文件。单个刀片通过PCI总线连接至主板,刀片中据的传输和交换,均通过该通道进行,刀片的实际组成如图1所示。
图1 刀片组成示意图
刀片在单机架系统中的位置如图2所示。
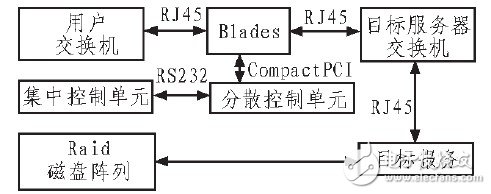
图2 刀片系统结构
在单机架系统中,用户交换机与Blade通过RJ45的千兆网接口进行连接,用户经用户交换机接入Blade服务器进行数据交换,可以在全球任何地方,由Intemet接入到用户交换机。集中控制单元具有网络端口等PC常用输出端口;分散控制单元(DMU)通过CompactPCI与Blade进行通信;通过232串口与集中控制中心(SMU)进行通信。DMU和SMU共同完成KVM的切换和采集Blade状态功能。
由于每个Blade没有单独的硬盘,所有Blade的启动都是通过目标服务器远程启动,并完成配置以及启动Raid中预装的操作系统,同时通过DHCPD(动态分配IP地址)、ADSS、iSCSI为每个Blade分配使用Raid磁盘阵列空间。也即每个Blade都是通过网络接口启动系统,所以网络配置要先于操作系统引导前完成初始化和驱动装载。
2 PCI局部总线概述
PCI总线是一种不依附于某个具体处理器的局部总线。从结构上看,PCI是在CPU和原来的系统总线之间插入的一级总线,具体由一个桥接电路实现对这一层的管理,并实现上下之间的接口以协调数据的传送。管理器提供了信号缓冲,使之能支持10种外设,并能在高时钟频率下保持高性能。PCI总线也支持总线主控技术,允许智能设备在需要时取得总线控制权,以加速数据传送。
通用PCI2.2接口信号如图3所示。在图3左半部分为必要信号,任选信号列于右边。其中信号名称右边加一个"#"符号表示是低电平有效,未加"#"符号的是高电平有效。根据信号的功能划分,可分为系统信号组、地址数据组、接口控制组、仲裁管理组、错误测试组、中断功能组、Cache支持组以及其他功能组。
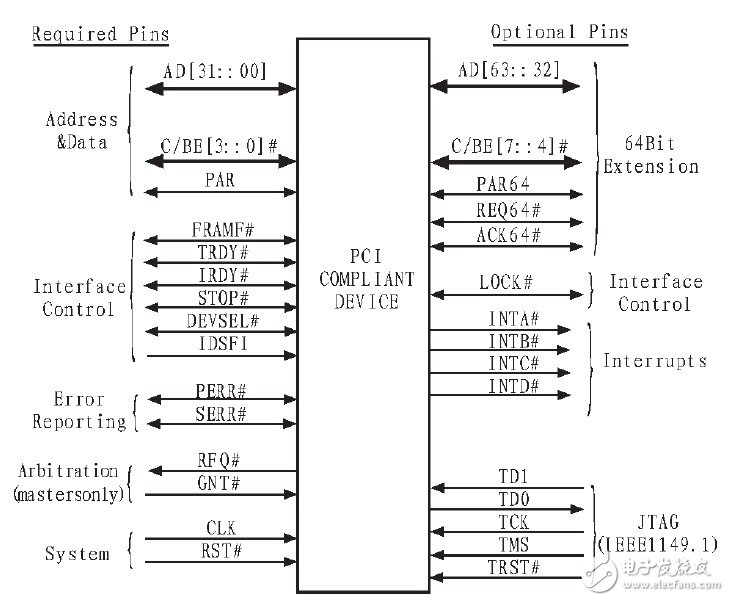
图3 PCI局部总线引脚图
3 基于FPGA的PCI数据交换实现
通常PC都是采用本地硬盘来引导操作系统,完成设备的驱动,Blade则通过网络启动系统,所以网络配置要先于操作系统引导,并完成初始化和驱动装载。为了解决这个难点,我们采用"PCI+FPGA+Flash"结构,在Flash中烧录双端口千兆网卡PCI设备的初始化和驱动装载程序,由CPU在系统上电时加载Flash中的程序到系统内存。由于数据传输是PCI总线,而Flash是标准的数据总线,这就存在数据总线转换的问题,问题解决的方案是通过FPGA完成PCI设备与Flash之间的通信,下面将详细介绍如何利用FPGA来完成PCI接口和Flash之间的通信。
3.1 FPGA系统逻辑与实现
整个FPGA系统设计基于PCI2.2从设备设计思想,PCI主设备为PCI桥芯片,用FPGA来完成PCI从设备功能,终端为Flash芯片。在FPGA系统中,PCI总线接口部分的设计参数为:PCI时钟为33 MHz(CLK),32位I/O接口(AD[310]),终端接口可以提供20位或32位数据线。PCI主设备与终端Flash间的通信采用PCI从设备(FPGA)来实现的。在FPGA的逻辑设计中,终端是兼有Memory空间和I/O空间的抽象设备,在实际的设计中终端Flash,只有对应的memory空间。
根据FPGA的模块设计思想,采用Verilog语言将整个系统按功能进行分块设计,每个模块的输出可以为其他功能模块提供输入,各模块功能和设计思想如下:
"PCI顶层模块"是系统顶层模块,完成系统端口各使能开关的定义和调用其他5个功能模块。
"配置模块"完成PCI从设备配置寄存器的设置。
"基址模块"实现两个功能:1)配置I/O空间和存储空间(memory空间)的基地址;2)告知PCI从设备状态机(The State Machine)。
"状态机模块"是整个设计的核心,控制PCI主设备到终端的所有数据传输。在PCI地址传送阶段,通过采样C/BE[30]和IDSEL来决定是配置读写、存储空间读写还是I/O空间读写。
"校验模块"对AD[310]和C/BE[30]#信号作奇偶校验,以保证数据的有效性。
"重入模块"若PCI从设备进行一个读写操作,则必须在6个时钟周期内(定义PCI从设备为slow=10 b,慢速设备)使能DEVSEL.若PCI从设备进行数据传送(已经使能DEVSEL),终端在9个时钟周期内没有使能READY#,则将告知:"The State Machine模块",终端暂时中止当前的数据传送,直到传送条件满足后,才重新启动数据传送。
3.2 FPGA系统逻辑功能仿真与结论
完成了各功能模块程序的编辑和编译过程,即可采用xilinx ISE11.2自带的HDL Bencher来生成测试激励文件,而后就可以调用Model Sim进行仿真了,该仿真也叫前仿真(逻辑功能仿真),布线后的仿真称为后仿真,也叫延时仿真,布线后的仿真包含门延时和线延时。
下面给出memory写操作功能仿真的详细步骤,并对结果进行分析。
I/O、memory空间读写过程非常相似,现对memory空间猝发方式写操作进行详细的说明。在图4中,通过测试文件生成pci_rst#=1,不产生复位动作,地址节拍pci_ad=0x2000_0000,表示PCI主设备从系统地址0x2000_0000地址开始写到终端0x00000地址开始的数据空间,可在"PCI顶层模块"定义(bkend_ad[190]=pci_ad[190]),终端只取系统地址的低20位地址。pci_cbe#[30]=0111,表示是memory空间写操作,在idle状态pci_frame#使能,irdy#、devsel#、stop#先不使能,PCI主设备将地址送到终端地址线上,data_stop#=1,表示终端支持猝发方式数据写操作。在下个时钟周期,进入到rw_wait状态,base_regionl#(memory片选)使能,告诉终端准备执行memory写操作,同时打开I/O、memory空间写操作使能。在下个时钟周期,进入到rw_wait2状态,如果终端使能ready#,表示终端准备好接收数据,使能devsel#、tr dy#、date_write#,其中date_write#使能,是让终端产生写使能信号。irdy#、trdy#使能。表示PCI主设备和终端数据可以有效传输,通过测试文件在PCI主设备的对应地址(0x2000_0000)下产生数据cdef0000,在该状态,写入终端第一个数据cdef0000.在下个时钟周期,进入到rw状态,如果在该状态下pci_frame#=0还使能,表示PCI主设备想支持猝发写,继续使能devsel#、trdy#信号,stop#不能使能,因为PCI主设备准备猝发写操作,在该状态下,只要pci_frame#=0(使能),循环写入数据cdef0001、cdef0002、cdef0003、cdef0004,上文已经介绍,下一个数据对应的地址自动加一,地址都是线性增加的。图4中,PCI主设备准备发送cdef0005数据时,irdy#=1(不使能),表示PCI主设备正在取数据,data_write#(终端写使能)不使能,告诉终端等待PCI主设备取数据,插入等待周期。在下个时钟周期,irdy#重新使能,date_wri te#也重新使能,继续写数据cdef0005,这样可以一直写数据。pci_frame#=1,表示进入最后一个周期的写数据操作,关闭irdy#、devsel#、base_regionl#使能。在下个时钟周期,进入到backoff状态,在下个时钟周期进入到idel状态,一个完整的memory猝发写就完成了。

图4 memory写操作功能仿真
完成功能仿真(前仿真)后和后仿真(布线后仿真)后,可使用ISE11.2自带的下载配置工具进行下载,至此FPGA系统设计全部完成,接着可对整个FPGA芯片进行硬件部分的测试工作。
可采用Xilinx的ISE自带的ChipScope Pro(在线逻辑分析仪),添加测试激励,可以看到数据的读写都是满足要求,具体跟上面的仿真波形相似,只是包含延时信息,门延时和线延时控制在0.5个时钟单元(15ns),符合设计要求。
4 结束语
刀片式服务器在军用控制和计算中心等计算密集型应用中已经得到广泛应用。随着InfiniBand技术开始扮演重要角色,刀片服务器将逐渐成为主流服务器。
-
如何让labview实现不同电脑之间的数据交换2015-11-21 3454
-
是否可以通过FPGA内核配置的双口RAM,实现FPGA与DSP之间的数据交换?2017-12-07 6198
-
求助如何设计实现应用AM3358实现与FPGA的高速数据交换2018-05-15 4385
-
设备与IoT中心之间进行数据交换的功能2021-03-30 2522
-
一个系统中多单片机之间的数据交换2009-02-09 887
-
策略驱动的数据交换模型2009-04-13 566
-
基于PCI-Express的高速数据交换设计及应用2009-05-26 948
-
基于FPGA的多通道串行数据交换中心的设计2010-07-06 630
-
CPU_之间通过_PROFIBUS_DP_进行数据交换的方法2010-08-11 926
-
什么是数据交换技术2009-06-17 5242
-
动态数据交换(DDE),动态数据交换(DDE)原理是什么?2010-03-18 11025
-
电子数据交换(EDI)是什么意思2010-04-03 5735
-
利用PCI局部总线实现Blade Server的数据交换2012-02-01 809
-
使用FPGA实现高速串行交换模块的方法详细说明2021-01-22 1339
-
IPFS节点之间如何进行数据交换?2021-08-30 14171
全部0条评论

快来发表一下你的评论吧 !
