

MOBA手游《小米超神》的UWA测评报告分析
人工智能
描述
今天我们为大家带来由福州朱雀网络研发的MOBA手游《小米超神》的UWA测评报告分析。该游戏在不同配置的移动终端设备上,无论是画面表现力,还是性能开销都非常优异。在此,我们将对该款游戏的性能数据进行深度剖析,希望通过这篇文章可以让大家对移动游戏各个模块的运行效率有更为深刻的认知,并对大家的项目研发有所帮助。
一、CPU性能
该游戏在CPU占用方面的性能非常不错,下图为该游戏在红米Note2设备上进行一场5V5战斗时的性能数据。
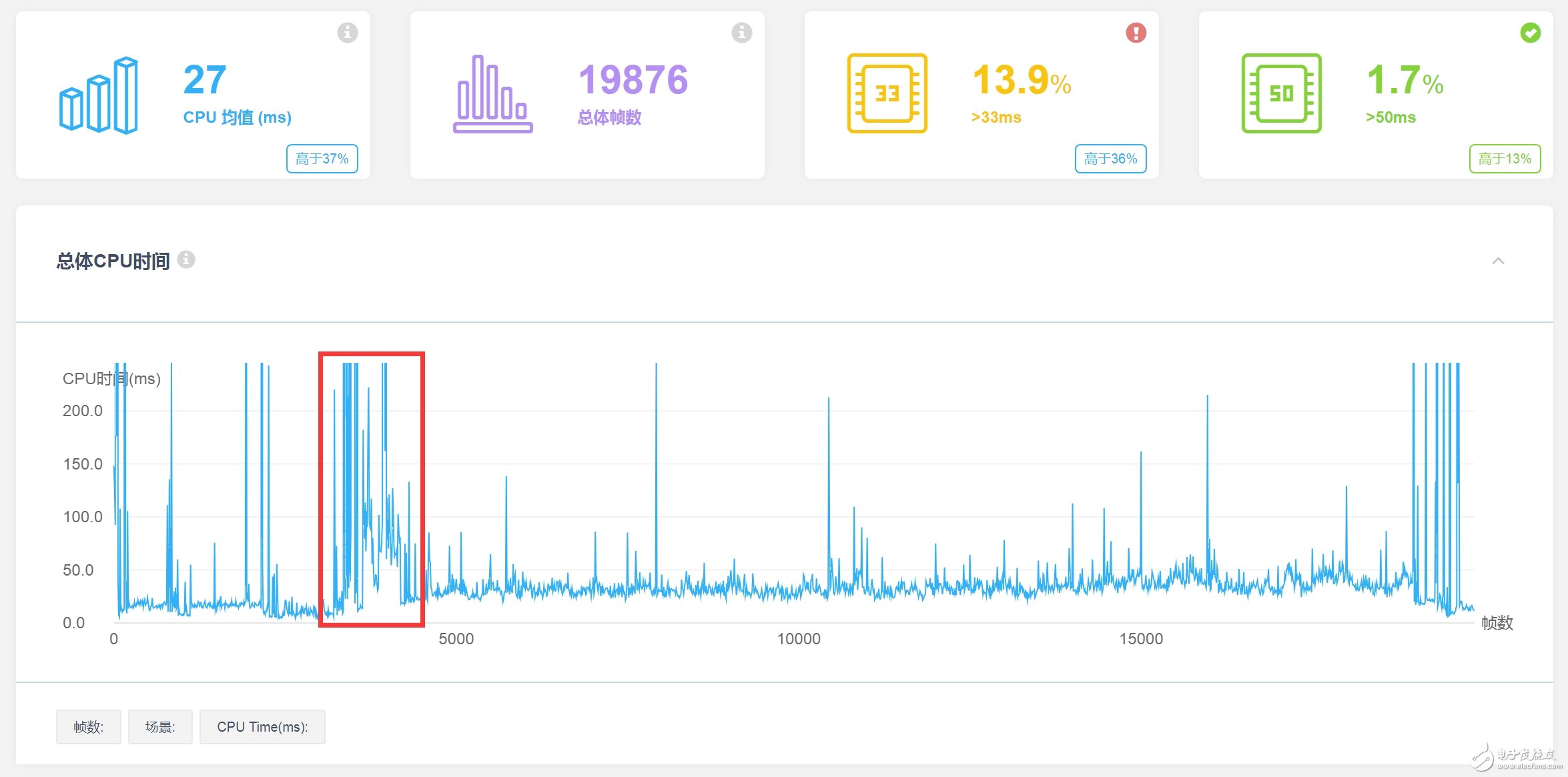
可以看出,在红米Note2上运行的19876帧中,超过33ms的帧数占比为13.9%,超过50ms的帧数占比为1.7%,并且从图中可以看出,其CPU耗时较高处主要集中在5V5场景的资源加载阶段。因此,该游戏在战斗时的性能可以说是非常优秀,绝大多数时刻游戏运行非常流畅。
同时,通过进一步统计,该游戏的CPU性能超过了64%的同设备(红米Note2)上测试的其他游戏,其能耗更是低于86%的同设备测试游戏。由于目前国内的MOBA游戏较少,所以上述排名并不是在MOBA类型中的排名,而是在所有类型游戏中的排名。对于一款超重度的MOBA移动游戏来说,该CPU性能和能耗排名可以说是相当出色。
其整体CPU性能的优秀表现与其各个模块的合理使用是分不开的。下面,我们就详细讲解其CPU性能方面的亮点之处。
1、渲染模块
通过UWA性能测评报告,我们可以看到该游戏详尽的渲染模块性能开销。该游戏在红米Note2设备上运行时的渲染模块CPU开销如下图所示。通过统计,半透明物体渲染的CPU消耗均值为1.7 ms,主要集中在0.8~3.0 ms范围内(5%~95%)。不透明物体渲染的CPU消耗均值为1.0 ms,主要集中在0.2~1.7 ms范围内(5%~95%)。可以看出,在整个5V5战斗过程中,无论是移动、Farm、Gank还是团战,甚至上高地时,其渲染耗时都稳定在一个较低的耗时区间。这得益于研发团队对于场景模型、蒙皮网格和UI的控制十分得当。
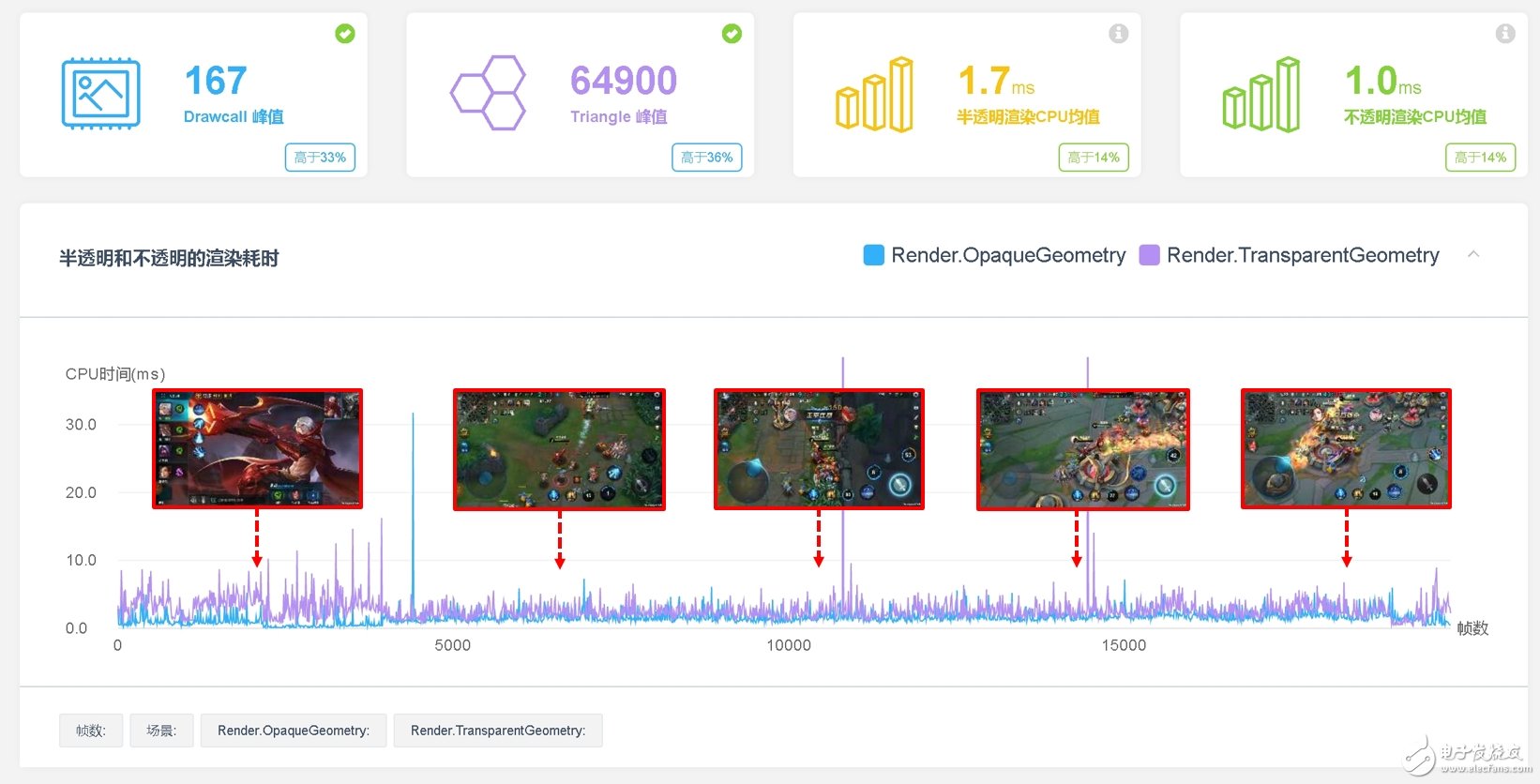
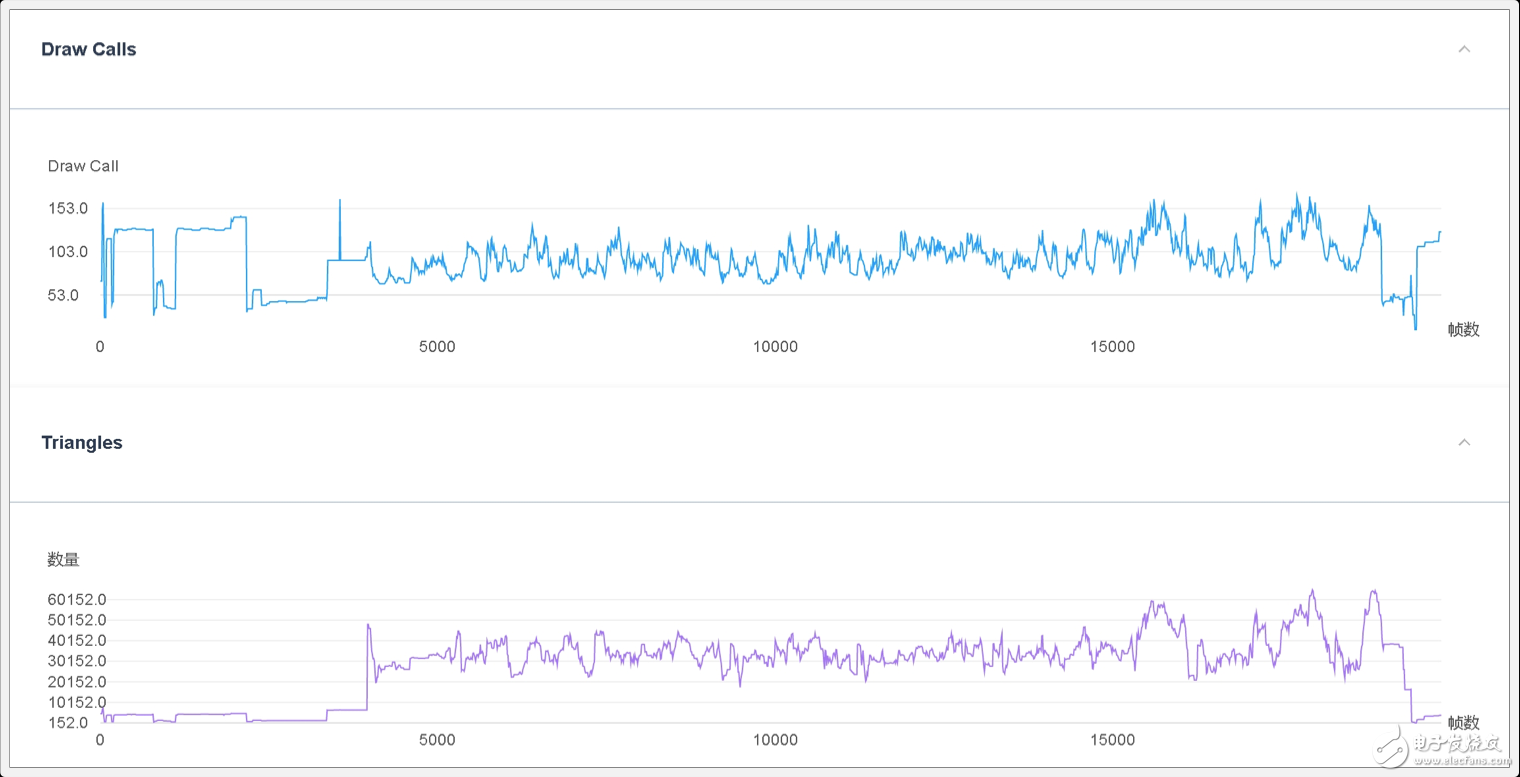
Draw Call峰值为167,且主要集中在 45~130范围内(5%~95%),渲染三角形面片单帧峰值为64900,以上数值均处于合理范围之内。
2、UI模块
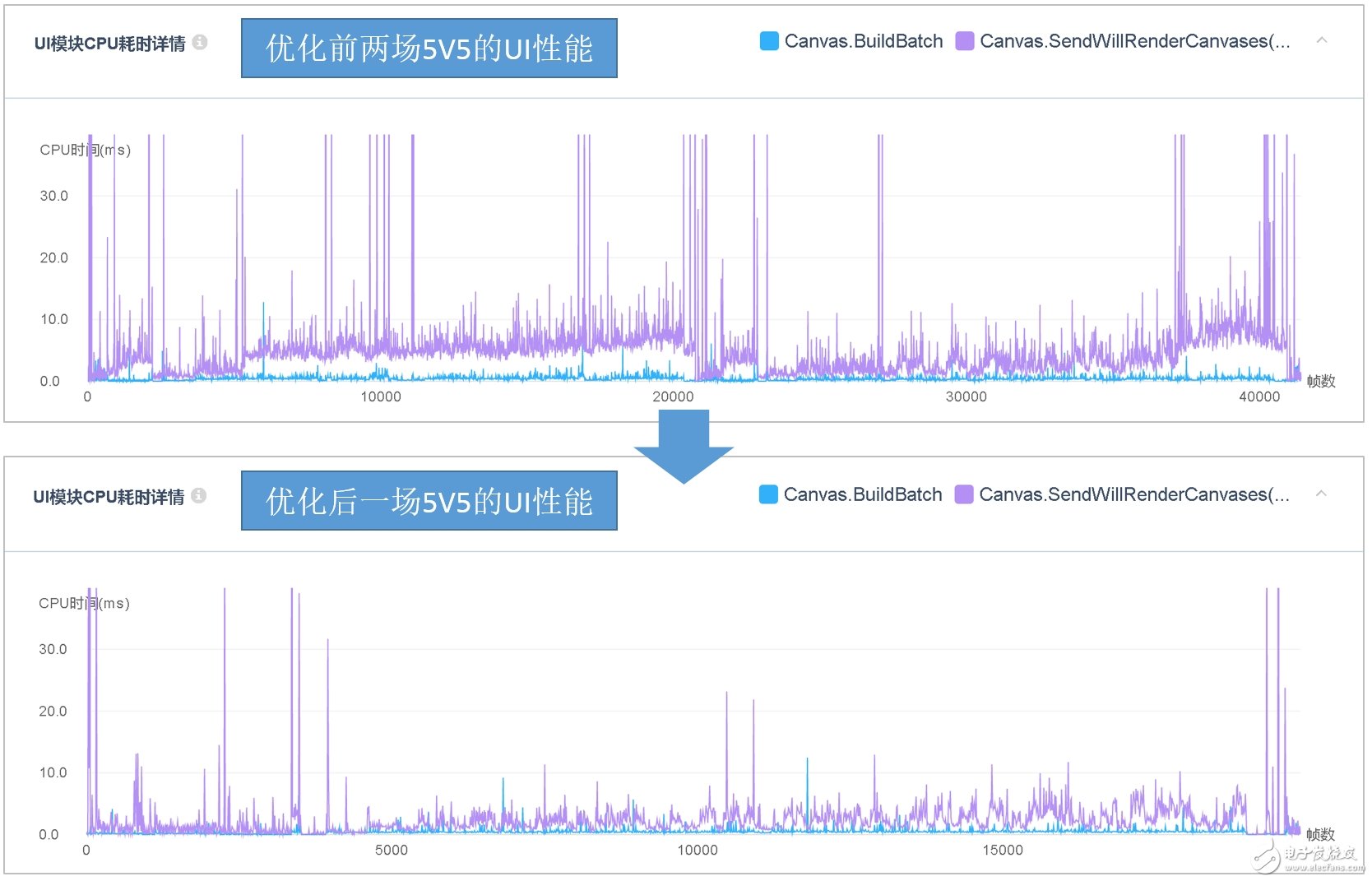
该游戏在红米Note2设备上运行时的UI模块CPU开销如下图所示。该游戏使用UGUI作为UI界面的解决方案。经过统计,UI模块总体的CPU占用均值为1.5 ms,主要集中在0.1~3.5 ms(5%~95%),属于合理范围之内。堆内存累积分配为16000帧 2.4MB,平均每帧分配堆内存155.4B,这说明该游戏UI界面的制作及UI重建的影响范围非常合理。目前,UWA推荐UGUI模块中,平均每帧堆内存分配尽可能控制在200B以下。
战斗场景中,UI系统的性能耗时主要是由UI元素的状态变化而导致的,比如血条、飘字等HUD的移动、消隐等。这种操作稍不注意,就会带来较高的UI网格重建开销。所以,UI界面的研发看似直观、简单,但是其对于制作时的层层考究和运行时的耐心调优,则是一款产品是否“匠心”的试金石。以下则为《小米超神》这款产品在经过几轮优化后的UI性能对比图。
3、动画模块
在UWA测评报告中,该游戏运行时的动画模块CPU开销如下图所示。可以看出,除进入场景时出现CPU高值外,其在战斗副本中的CPU开销均控制在较低水平。Animator.Update的CPU均值为2.0 ms,主要集中在0.1~4.3ms区间内,对于MOBA项目5V5场景来说,基本上每帧均有90-130个物体在进行运动(除英雄、小兵之外,还有信使宠物、野怪、塔、插眼等等),由于玩家可以随意查看地图上任何一个角落的特点,其每帧的动画系统压力要比常规的MMO游戏大上数倍。因此,《小米超神》可以将其控制在均值2.0ms的水平线上,已经是非常优秀的数据了。
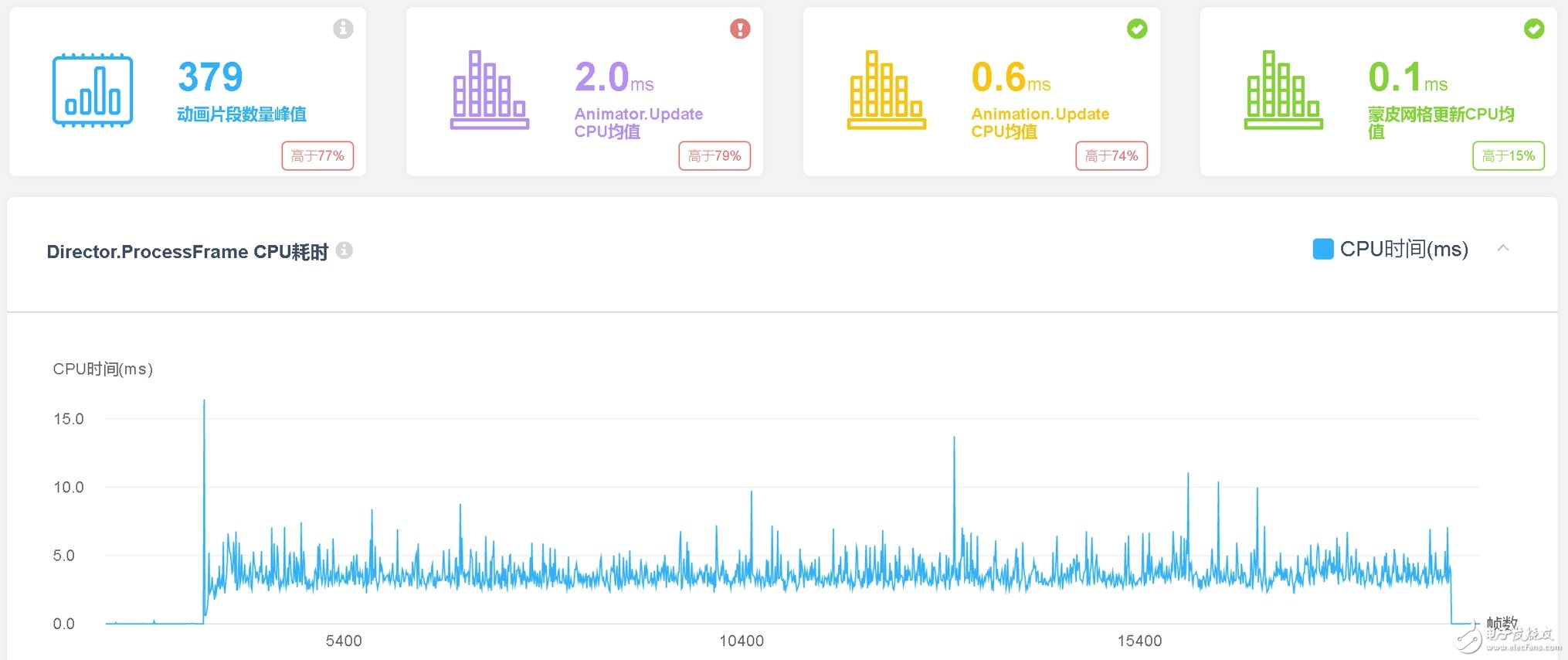
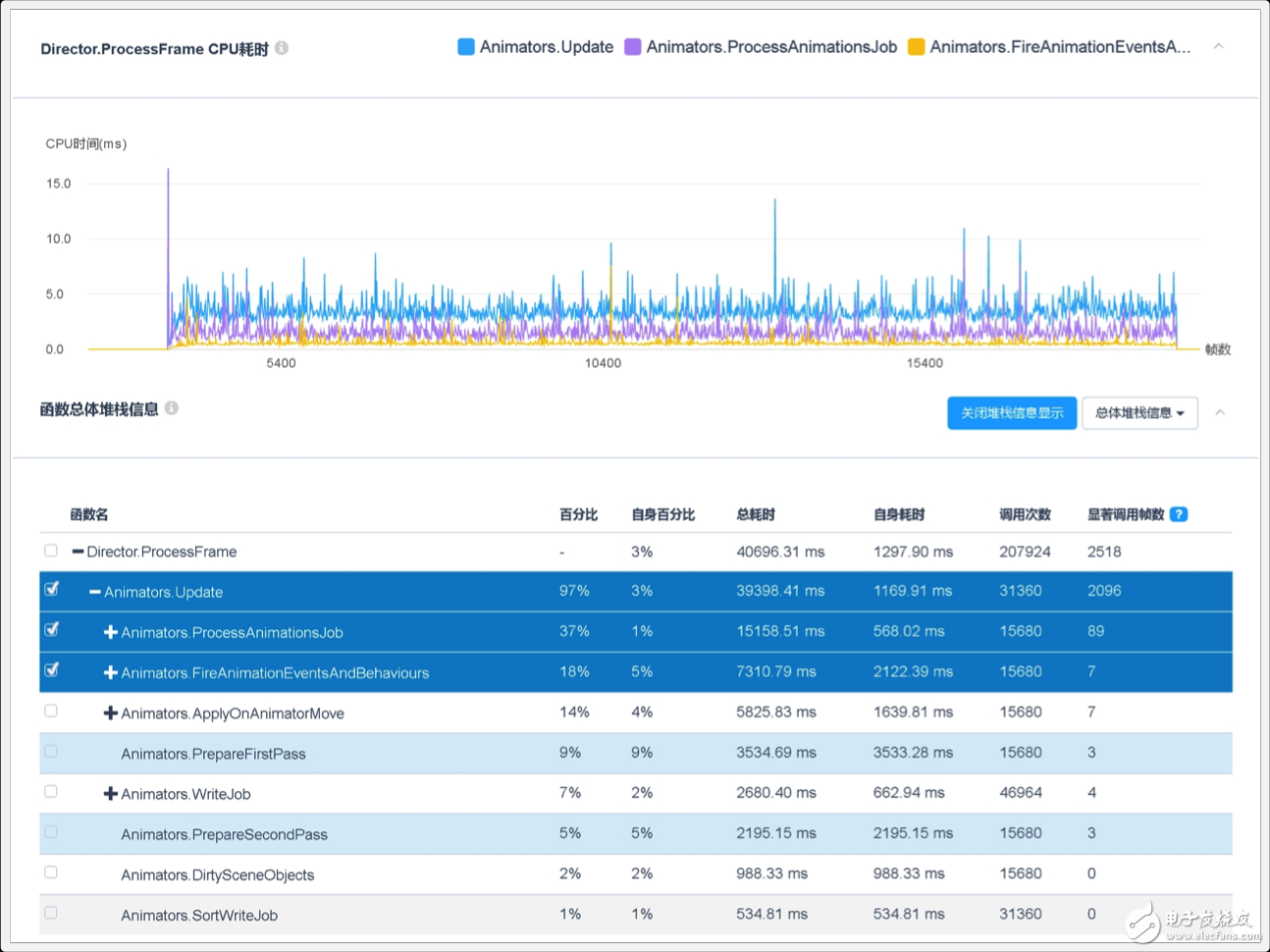
同时,经过进一步检测发现,动画模块的耗时主要由Animators.ProcessAnimationsJob和Animators.FireAnimationEventsAndBehaviours导致,前者主要是持续的累积耗时,而后者则是非连续的“尖刺”开销。前者是动画系统对于AnimationClip的读取和计算耗时所致,其耗时大小与当前帧参与计算的骨骼节点数、动画曲线数、动画执行状态和Animator Controller的具体设置相关,其具体说明可参见《Unity中动画系统性能优化方案回顾》;后者则是动画事件的具体耗时,主要是项目逻辑代码的性能开销,此处研发团队可以通过性能堆栈来进一步查看其逻辑代码的开销是否有进一步的优化空间。
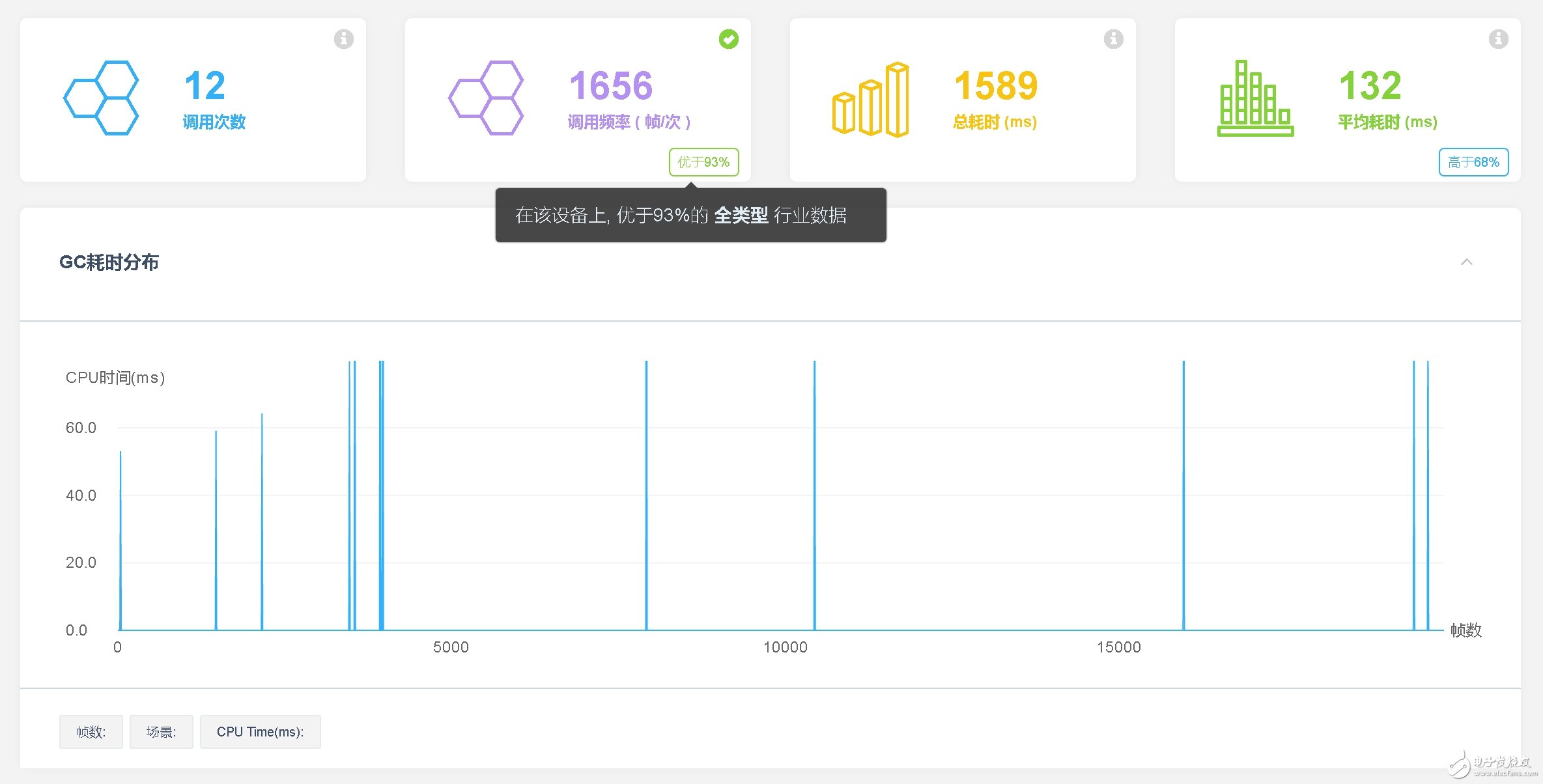
4、GC 调用
该研发团队对于GC调用频率控制得非常出众,游戏在运行过程中,GC调用频率为1656帧/次,优于目前93%的行业内游戏。一般来说,我们建议一款项目的GC调用频率可以控制在1000帧/次以上。
该游戏的GC调用频率如此优秀,主要得益于研发团队对于项目代码堆内存的控制。下图为游戏运行20000帧的代码堆内存具体分配情况,其Top10函数的堆内存分配总和不超过80MB,足见该团队对于堆内存分配的理解非常深刻。
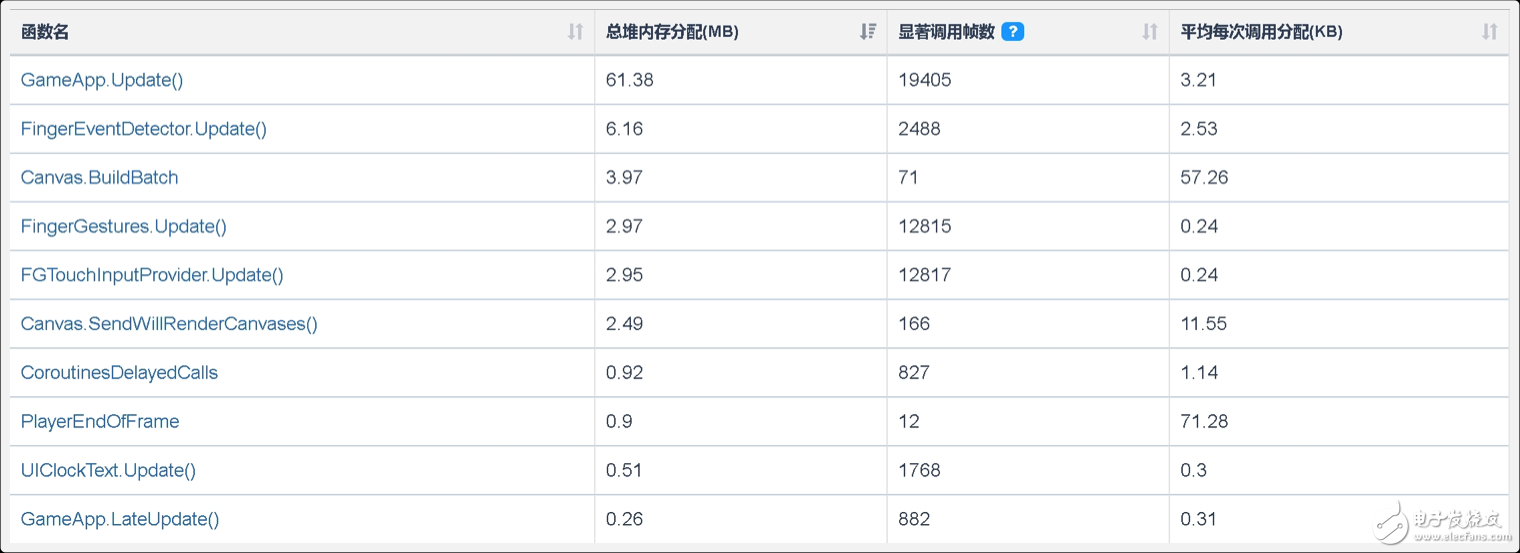
当前版本的堆内存分配仍然有进一步下降的空间,从堆栈信息中可以看到,其Log输出仍然存在一定堆内存分配,建议研发团队在Release版本中将非关键性Log进行屏蔽。

二、内存模块
《小米超神》在内存上的表现如下图所示。总内存峰值达到297MB,Mono堆内存峰值为48.9MB。297MB的总内存分配相对来说略高,研发团队可尝试在低内存机器上对资源进行进一步控制,从而降低低内存机器上的内存占用。
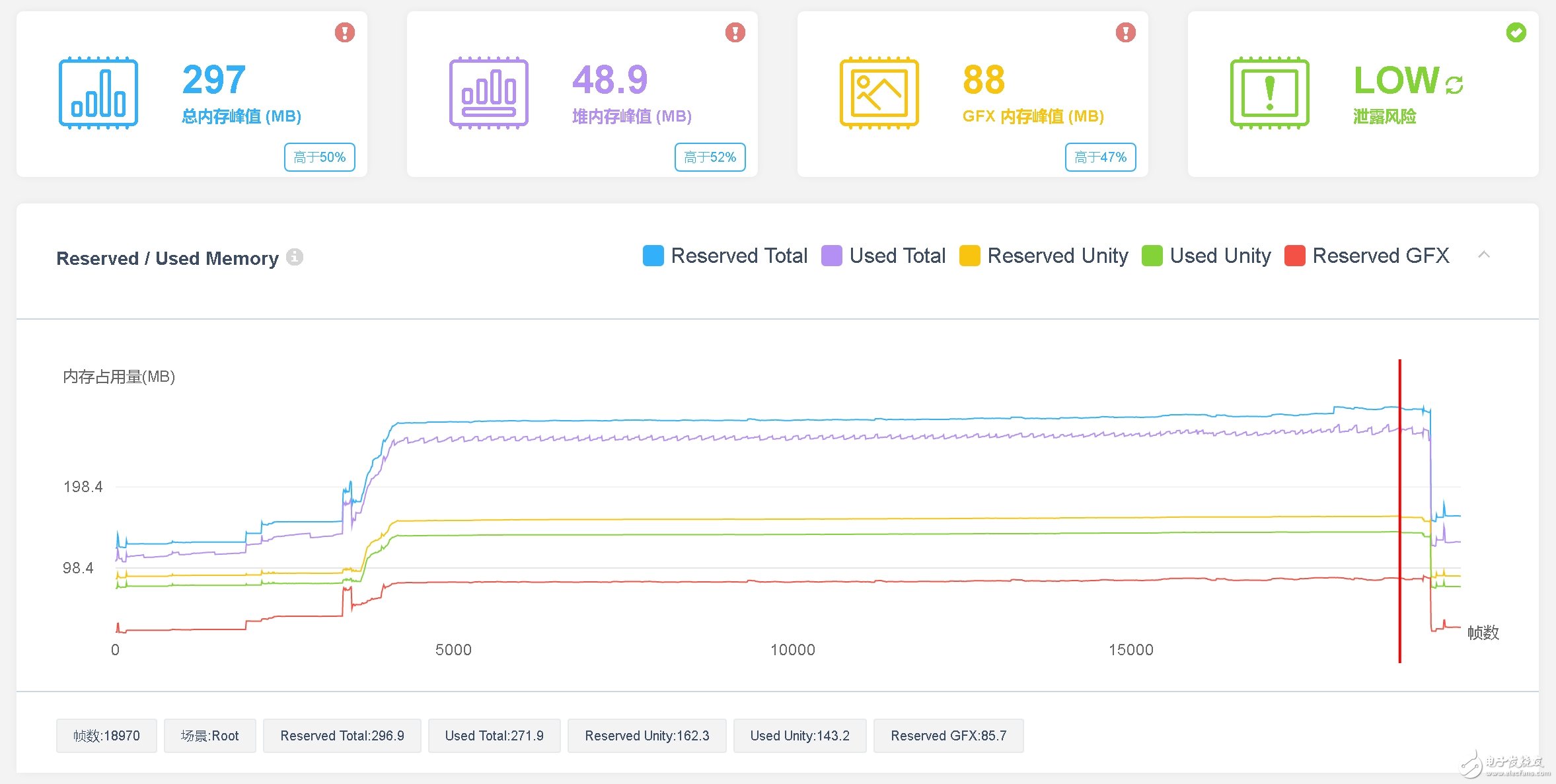
1、Mono堆内存
从下图可知,该游戏的总体Mono堆内存控制得很好,在20000帧中,Mono的堆内存峰值为48.9MB,该值略高(UWA建议《40MB)。从图中看,是战斗最后上高地时突然出现了较高的堆内存分配,迫使Mono堆内存上涨了8MB(如下图红框所示),对此,研发团队可以根据具体位置查看其堆内存分配,即可定位其具体的堆内存分配根源。
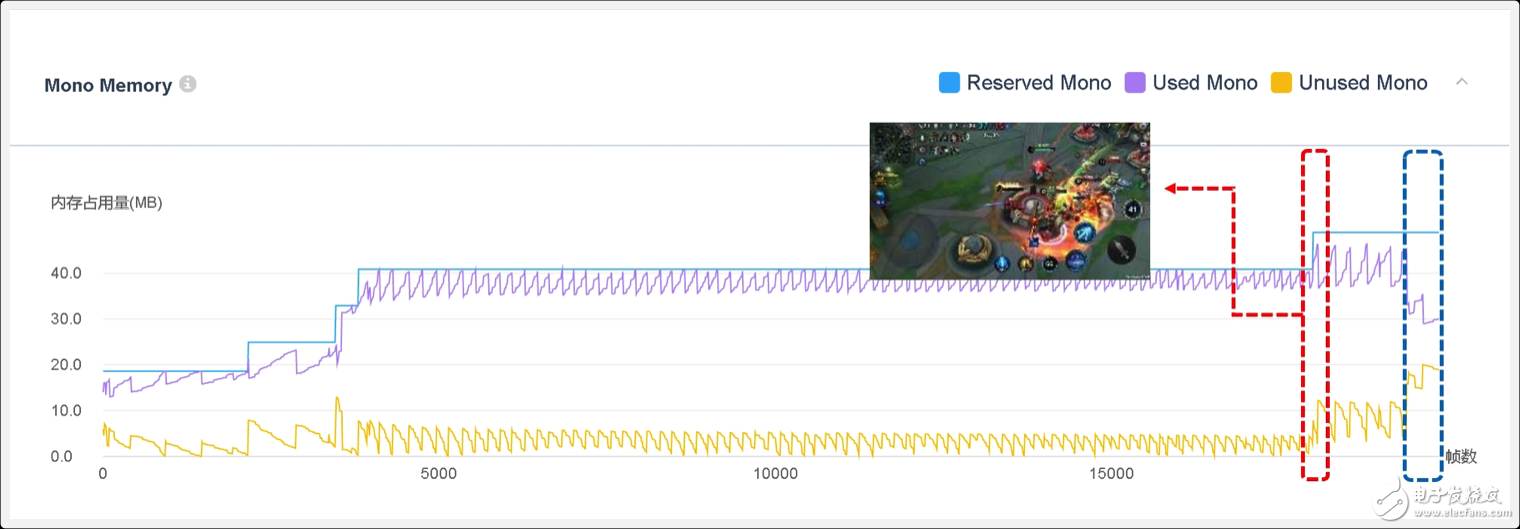
但是,从走势上来看,其Used Mono堆内存占用在5V5战斗结束后,并未完全回落到场景之前(如蓝框所示),这一点需要引起研发团队注意,确认其是否为部分指定容器缓存所致,从而排查项目是否存在堆内存泄露的隐患。
2、资源内存
经过统计,该游戏运行时的纹理资源数量峰值为1003个,内存占用峰值54.8MB。研发团队将纹理内存占用控制得很低,目前仅高于30%的行业项目。经过统计,在内存占用峰值处,ETC1和ETC2格式纹理占有835个,RGBA32格式纹理共占有89个,RGB24格式纹理占有5个,其余为RGBA16格式纹理。
纹理资源在项目运行期间的总体使用情况:

对于纹理资源的优化,一般可分为以下几种:
(1)使用更合适的纹理格式
从上图中可以看到,在整个游戏一场5V5战斗过程中,RGBA32格式纹理的使用数量较多,其使用总量已经超过了91%的的行业项目。对此,我们建议在视觉效果可以保证的情况下,尽可能使用ETC1格式纹理(Android平台)进行替换,不仅可以达到更小的内存占用,同时可以获得更快的加载效率。而对于无法进行硬件压缩的纹理,可以通过Dither方法尝试将其转换成RGBA16格式的纹理,具体做法可以参考Unity图片优化神器 - Dither算法进阶方案。
(2)使用更精准的纹理分辨率
一般来说,为了让模型看上去更加精美,除Mesh模型本身以外,其对应的纹理都会选用较高的纹理尺寸,从而让其看上去更加精致。但是,由于渲染物体在真正的游戏中相对于相机是有远近之分的,其显卡底层往往没有(或根本不需要)使用如此高的分辨率来进行渲染,从而就造成了大量的资源浪费,这在我们深度优化过的项目中比比皆是。因此,我们建议可以通过UWA线上测评报告中GPU性能的Mipmap功能页面来直接查看游戏运行时,其底层的纹理分辨率使用情况,如下图所示。
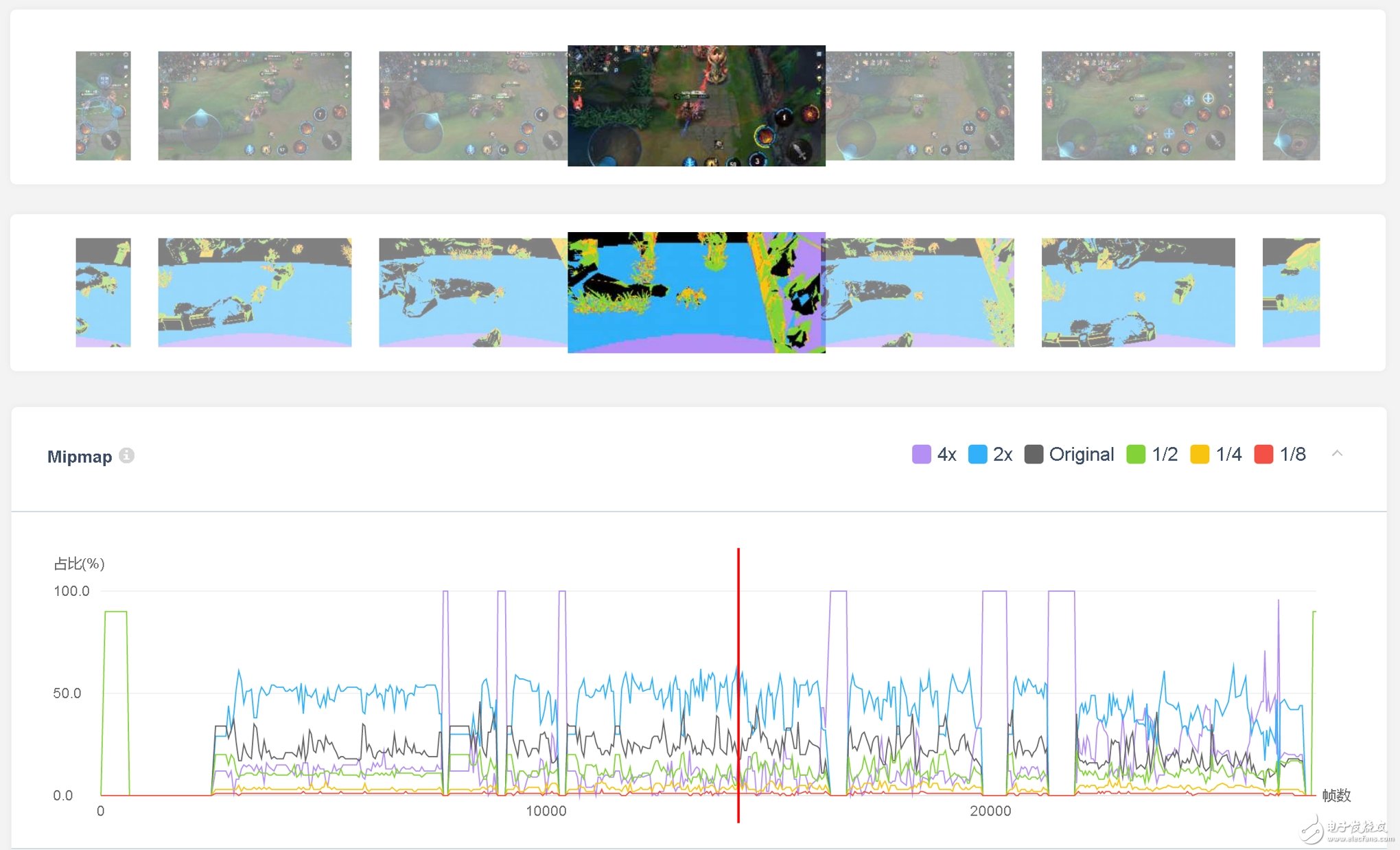
同时,在深度优化报告中,我们也会进行更大量的测试和几十亿像素累积分析,从而来精准指出到底哪些纹理资源的分辨率制作过高,可在不影响视觉效果的前提下,将其分辨率缩小4倍、16倍甚至更多。《小米超神》项目通过这种方式不断优化,其5V5场景的纹理内存已经从之前的78MB降到了现在的52MB。
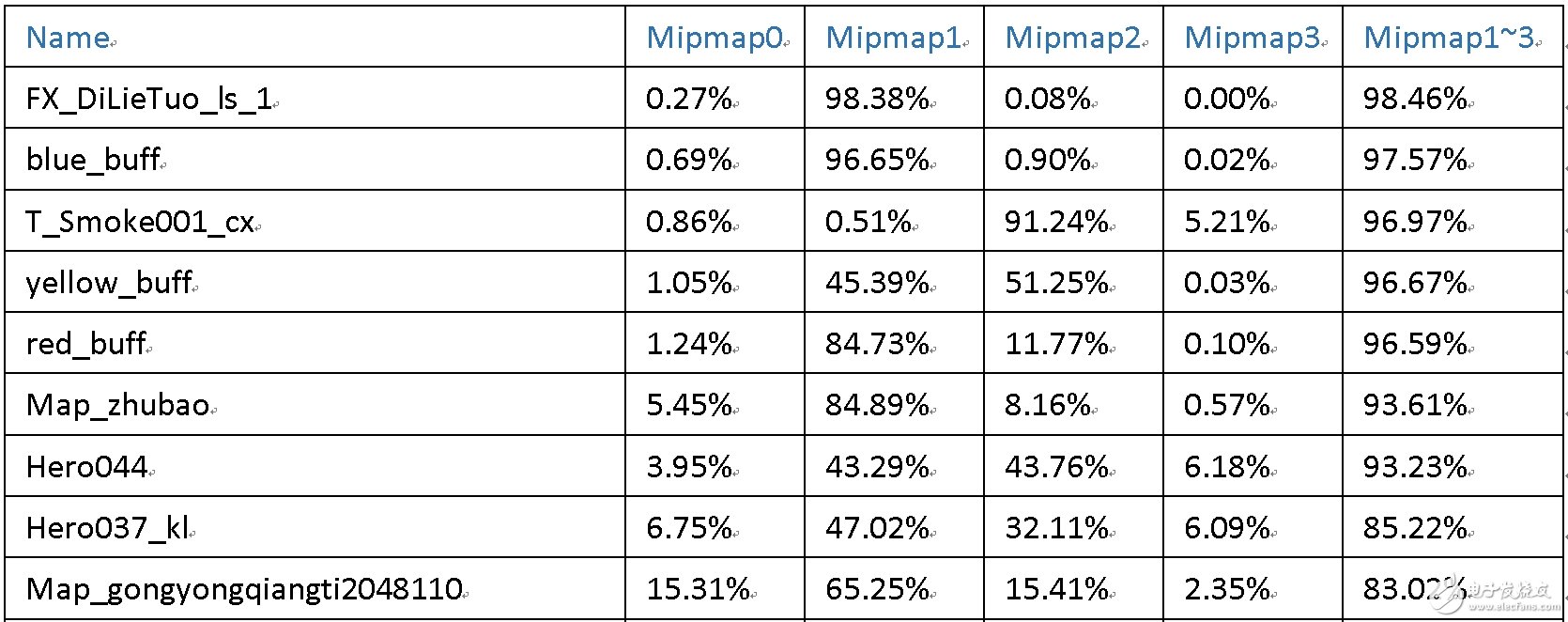
以上是纹理资源的使用情况,其他资源的内存占用情况如下:
网格资源在项目运行期间的总体使用情况:

Mesh资源的内存占用较高,高于60%的行业项目。对于Mesh资源内存的优化,主要有以下几种方法:
(1)控制网格顶点属性的使用
详细检测网格模型中的Color数据和Tangent数据,当不需要时切记要将其进行去除,否则会在场景模型拼合时产生大量的内存浪费,具体详细说明可以参考《移动游戏加载性能和内存管理全解析》。
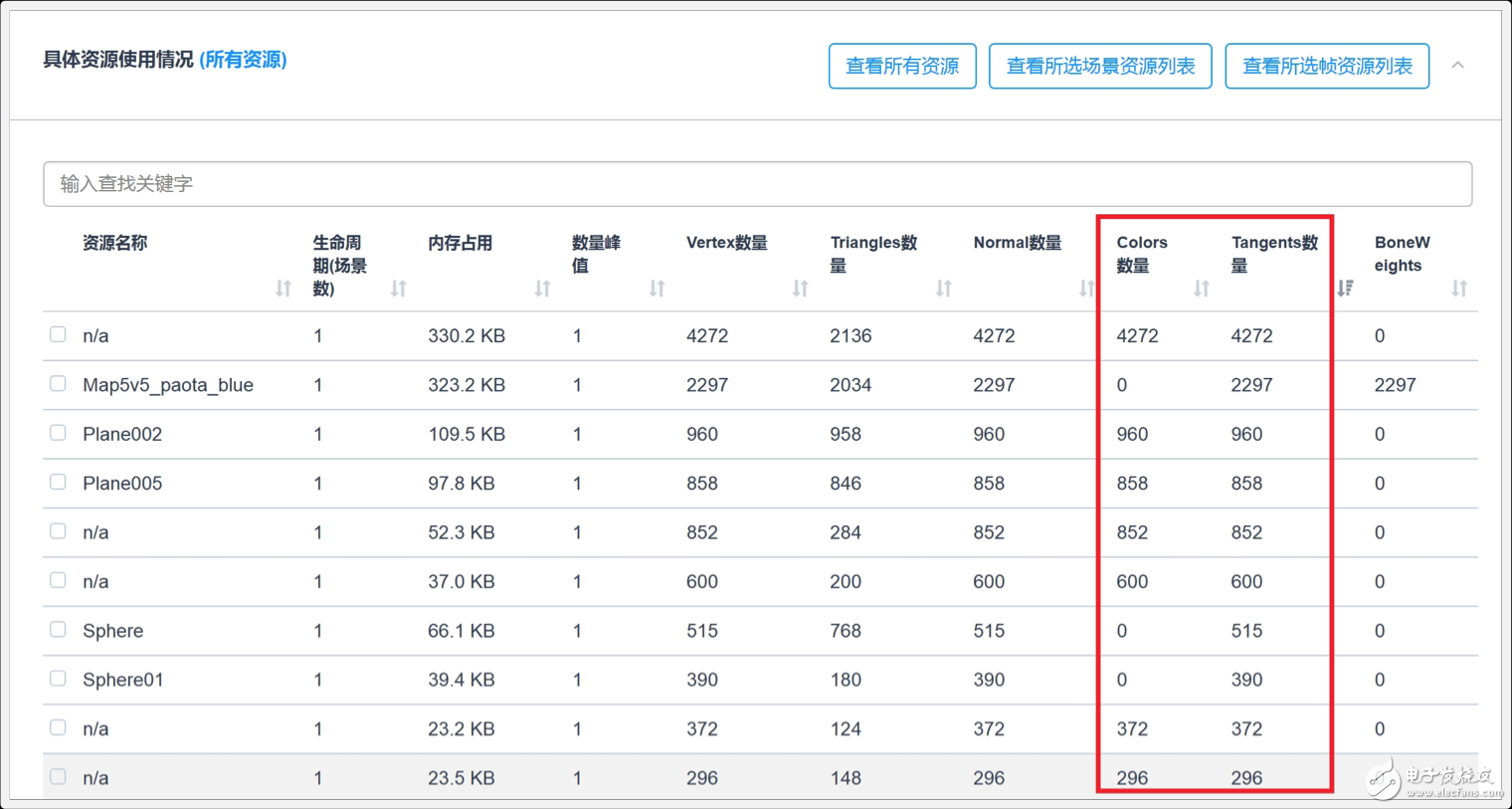
(2)控制网格顶点的数量
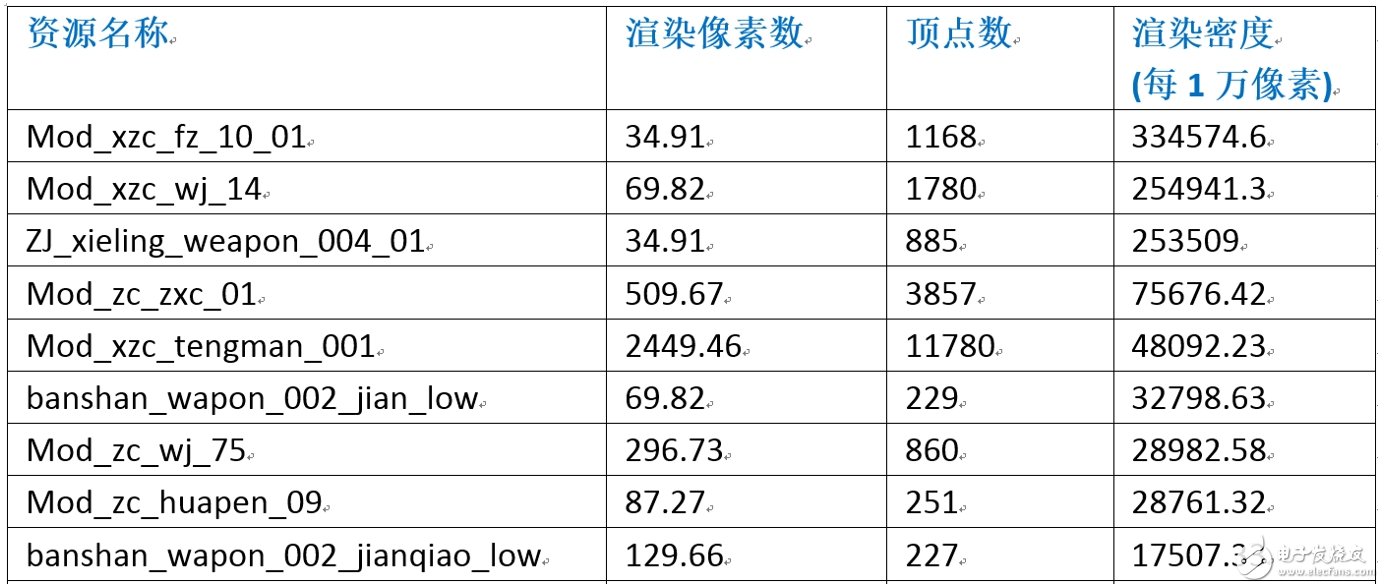
详细检测网格模型的顶点数(或面片数)使用是否过大。这是一个说起来容易但实施起来很难的问题,其难点在于如何定义一个Mesh网格的顶点数是否过大。在UWA测评报告中会有一个建议,即建议将Mesh网格顶点数控制在1500个以下。但实际上,这其实是一个“不科学”的规定,因为没有任何一个理论可以证明,其网格数量大于1500就是不合格,或则小于1500就一定合格。所以,我们这一年来花了大量的时间来寻求一种更为合理、科学的判断规则。我们认为判断一个网格模型使用是否合规并不应该是“静态”检测,而应该是一种“动态”检测,与上述纹理资源的检测一样,我们应该去看网格资源在底层渲染时到底占据了多少像素,从而以一种密度统计的方式来判断其网格使用量是否合理。因此,我们提出了一种网格模型测量标准,即“网格模型渲染密度”,其表示每单位数量(比如,1万)像素中,其网格模型的渲染顶点数量。
下图则为游戏运行过程中的网格模型渲染密度统计值。可以看出,虽然第一个模型“Mod_xyc_fz1001”的顶点数仅为1168,但其在游戏运行时平均每帧的渲染像素量仅为34.91个,也就是说平均每个像素要渲染33个网格顶点,这显然是一种浪费。因此,通过“渲染密度”这一检测方式,可以反映任何一个模型在游戏运行时的使用情况。在我们来看,这是一个比单纯设定1500更加合理的判断规则。
AnimationClip资源在项目运行期间的总体使用情况:

AnimationClip的内存占用较高,高于76%的全类型游戏项目。对于一款MOBA项目来说,其内存占用较高是可以理解的,因为其战斗副本中拥有大量的动画模型,比如英雄、小兵、野怪、塔、基地等建筑等等。对此,仅能建议研发团队尝试从数量上进行进一步地缩减,以降低其内存的使用。同时,对于动画片段内存的一般优化还有“缩减精度”、“使用Humanoid类型”等方法,其具体优化方法可以参考《Unity中动画系统性能优化方案回顾》。
三、资源管理
该游戏在资源实例化/销毁、Active/Deactive等方面做的非常出色!在游戏运行的20000帧中,Instantiate和Destroy调用次数分别为1653次和4019次,而Active和Deactive调用次数则分别为116次和1447次。同时,对于Instantiate和Destroy操作来说,其主要调用均在进出战斗场景处,副本中虽有Instantiate调用,但无论是频率还是CPU耗时,均处于合理范围之内,如下图所示。

对于GameObject相关的资源管理,我们的建议如下:
(1)对项目中存在频繁Instantiate/Destroy操作的GameObject一定要进行大力彻查,下图即为某一项目的Instantiate实例化详情,我们建议对于红框处高频率和耗时的操作重点排查,因为其无论是CPU还是堆内存都对项目性能造成非常大的杀伤力!

(2)频繁的Active/Deactive操作不仅会造成CPU的浪费,同时,它还很可能间接造成更大的CPU耗时,比如Animator.Initialize耗时。在此,我们不妨看下另一款游戏的Animator.Initialize调用情况,如下图所示,其调用的频率和耗时较高,这就是频繁的Active/Deactive操作所造成的结果。因此,对于GameObject不必要的Active和Deactive操作进行控制,是非常有必要的。更为详细的资源加载性能优化总结,可参见《Unity移动游戏加载性能和内存管理全解析》。

(3)不断检测、不断完善,优化是一个需要不断迭代、持之以恒的事情。下图则为《小米超神》经过几轮优化之后的资源管理变化情况。

以上则为《小米超神》游戏在CPU性能和内存管理方面的具体使用情况。优秀的CPU性能、非常少的堆内存分配以及引擎模块间的合理使用,足以看出该研发团队非常深厚的技术功底和对于引擎相当优秀的把控能力。
最后,非常感谢《小米超神》研发团队对 UWA 的认可和支持。感谢他们乐意将项目性能数据与大家一起分享,让更多的研发团队了解到一款性能优秀的MOBA手游在各个模块上应该做到怎样的程度。同时,也希望更多的开发团队可以与我们一起来分享他们的性能数据,让更多的游戏开发者受益!
关于UWA
由侑虎科技开发的游戏/VR应用性能优化平台,目前提供 三大工具,帮助开发者在短时间内大幅度提升性能表现;同时其搭建的知识分享的博客(blog.uwa4d.com)和答疑解惑的互动平台(answer.uwa4d.com)使广大开发者收益,UWA以实力和态度诠释对性能优化的定义:问题的答案永远“在现场”,解决你的性能问题,才叫“优化”。
- 相关推荐
- 小米
-
2024年小米汽车产业链分析及新品上市全景洞察报告2024-03-29 0
-
《半导体行业2016年度报告》即将来袭|摩尔精英2016-12-14 0
-
《半导体行业2016年度薪资报告》来袭|摩尔精英2016-12-16 0
-
ADuC7060测评报告2018-11-16 0
-
逻辑分析仪探测评估2019-09-16 0
-
小米6怎么样?小米6详细测评:500块钱涨在这些地方2017-04-20 1831
-
亮相小米互娱展台,小吉迷你复古冰箱惊艳2017ChinaJoy2017-07-31 892
-
天猫精灵和小米ai对比测评2017-12-29 71652
-
小米MI4的测评,了解其性能2018-07-06 5671
-
小米5的全面测评,了解手机参数性能2018-07-05 3212
-
小米11vivox60对比哪个好 vivox60和小米11参数测评以及拍照对比2021-02-02 12362
-
UWB天线UWA-02规格书2021-11-05 558
-
UWA平台支持PowerVR芯片,新增四大GPU模块分析2022-10-19 941
-
具有多个光子和UWA的无用机器2023-07-10 258
-
UWA推出全新GPU性能测评工具,支持多款PowerVR芯片优化2023-08-14 1185
全部0条评论

快来发表一下你的评论吧 !
