

模式识别贝叶斯分类器概念
电子常识
描述
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。
种类
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。目前研究较多的贝叶斯分类器主要有四种,分别是:Naive Bayes、TAN、BAN和GBN。
解释
贝叶斯网络是一个带有概率注释的有向无环图,图中的每一个结点均表示一个随机变量,图中两结点间若存在着一条弧,则表示这两结点相对应的随机变量是概率相依的,反之则说明这两个随机变量是条件独立的。网络中任意一个结点X 均有一个相应的条件概率表(Conditional Probability Table,CPT),用以表示结点X 在其父结点取各可能值时的条件概率。若结点X 无父结点,则X 的CPT 为其先验概率分布。贝叶斯网络的结构及各结点的CPT 定义了网络中各变量的概率分布。
一、分类器的基本概念
经过了一个阶段的模式识别学习,对于模式和模式类的概念有一个基本的了解,并尝试使用MATLAB实现一些模式类的生成。而接下来如何对这些模式进行分类成为了学习的第二个重点。这就需要用到分类器。
表述模式分类器的方式有很多种,其中用的最多的是一种判别函数gi(x),i=1,2.。。,c的形式,如果对于所有的j≠i,有:gi(x)》g(x)
则此分类器将这个特征向量x判为ωi类。因此,此分类器可视为计算c个判别函数并选取与最大判别值对应的类别的网络或机器。一种分类器的网络结构如下图所示:
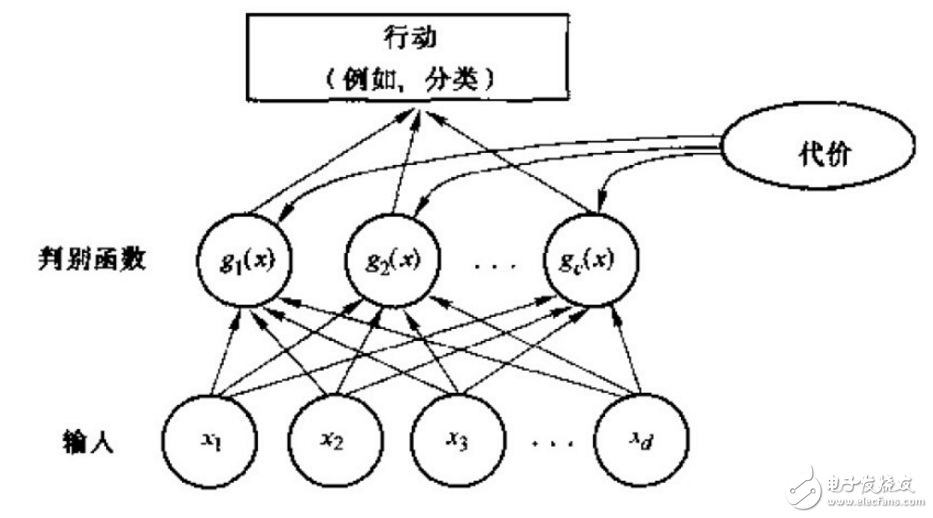
二、贝叶斯分类器
一个贝叶斯分类器可以简单自然地表示成以上网络结构。贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。在具有模式的完整统计知识条件下,按照贝叶斯决策理论进行设计的一种最优分类器。分类器是对每一个输入模式赋予一个类别名称的软件或硬件装置,而贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。它的设计方法是一种最基本的统计分类方法。
对于贝叶斯分类器,其判别函数的选择并不是唯一的,我们可以将所有的判别函数乘上相同的正常数或者加上一个相同的常量而不影响其判决结果;在更一般的情况下,如果将每一个gi (x)替换成f(gi (x)),其中f(∙)是一个单调递增函数,其分类的效果不变。特别在对于最小误差率分类,选择下列任何一种函数都可以得到相同的分类结果,但是其中一些比另一些计算更为简便:
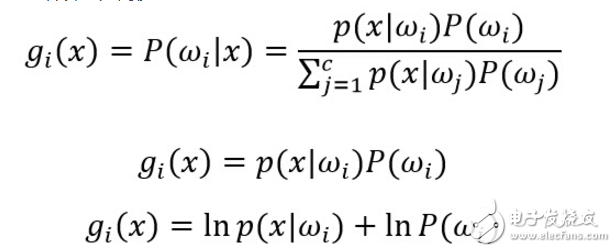
一个典型的模式识别系统是由特征提取和模式分类两个阶段组成的,而其中模式分类器(Classifier)的性能直接影响整个识别系统的性能。 因此有必要探讨一下如何评价分类器的性能,这是一个长期探索的过程。分类器性能评价方法见:http://blog.csdn.net/liyuefeilong/article/details/44604001
三、基本的Bayes分类器实现
这里将在MATLAB中实现一个可以对两类模式样本进行分类的贝叶斯分类器,假设两个模式类的分布均为高斯分布。模式类1的均值矢量m1 = (1, 3),协方差矩阵为S1 =(1.5, 0; 0, 1);模式类2的均值矢量m2 = (3, 1),协方差矩阵为S2 =(1, 0.5; 0.5, 2),两类的先验概率p1 = p2 = 1/2。详细的操作包含以下四个部分:
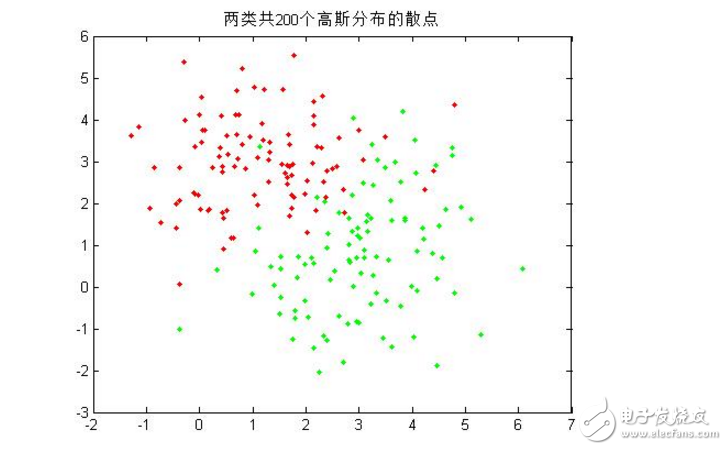
1.首先,编写一个函数,其功能是为若干个模式类生成指定数目的随机样本,这里为两个模式类各生成100个随机样本,并在一幅图中画出这些样本的二维散点图;
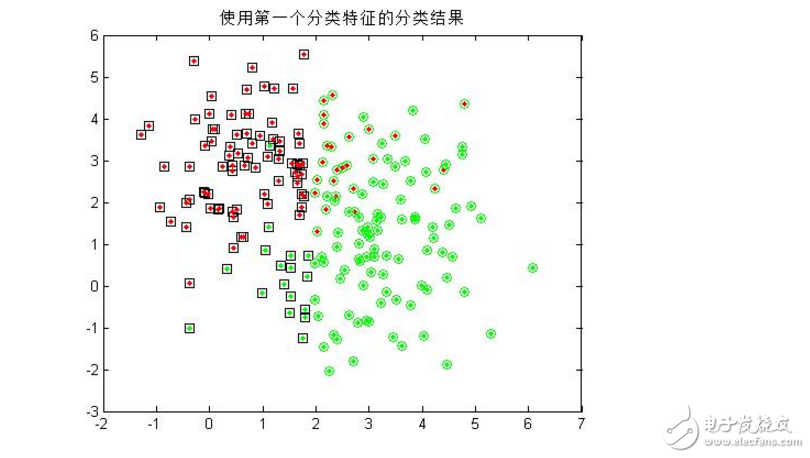
2.由于每个随机样本均含有两个特征分量,这里先仅仅使用模式集合的其中一个特征分量作为分类特征,对第一步中的200个样本进行分类,统计正确分类的百分比,并在二维图上用不同的颜色画出正确分类和错分的样本;(注:绿色点代表生成第一类的散点,红色代表第二类;绿色圆圈代表被分到第一类的散点,红色代表被分到第二类的散点! 因此,里外颜色不一样的点即被错分的样本。)
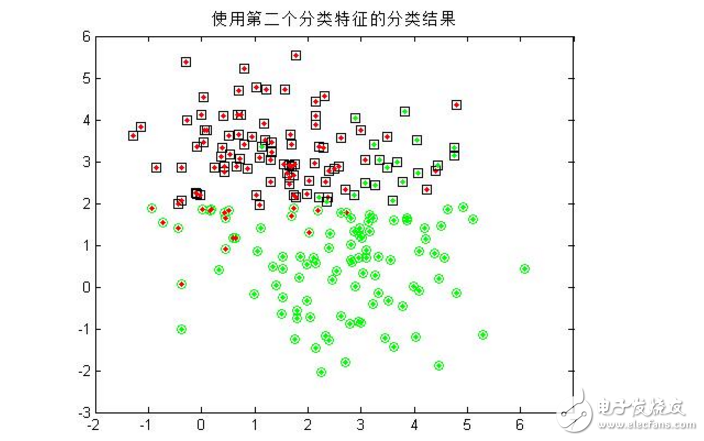
3.仅用模式的第二个特征分量作为分类特征,重复第二步的操作;
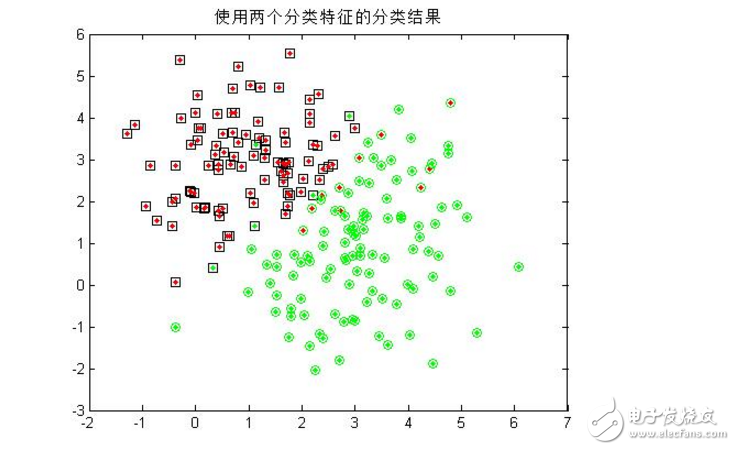
4.同时用模式的两个分量作为分类特征,对200个样本进行分类,统计正确分类百分比,并在二维图上用不同的颜色画出正确分类和错分的样本;
正确率:
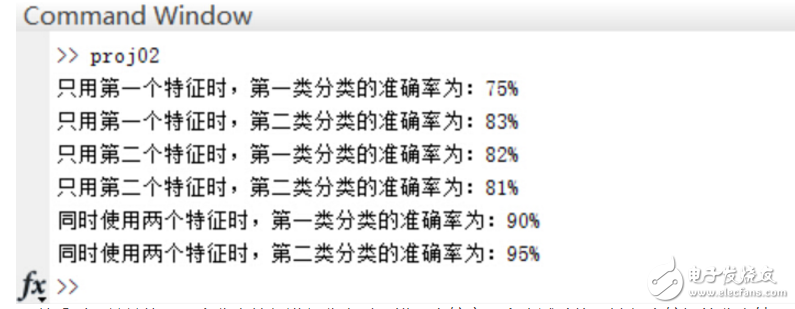
可以看到,单单使用一个分类特征进行分类时,错误率较高(多次试验均无法得出较好的分类结果),而增加分类特征的个数是提高正确率的有效手段,当然,这会给算法带来额外的时间代价。
四、进一步的Bayes分类器
假设分类数据均满足高斯分布的情况下,设计一个判别分类器,实验目的是为了初步了解和设计一个分类器。
1.编写一个高斯型的Bayes判别函数GuassianBayesModel( mu,sigma,p,X ),该函数输入为:一给定正态分布的均值mu、协方差矩阵sigma,先验概率p以及模式样本矢量X,输出判别函数的值,其代码如下:
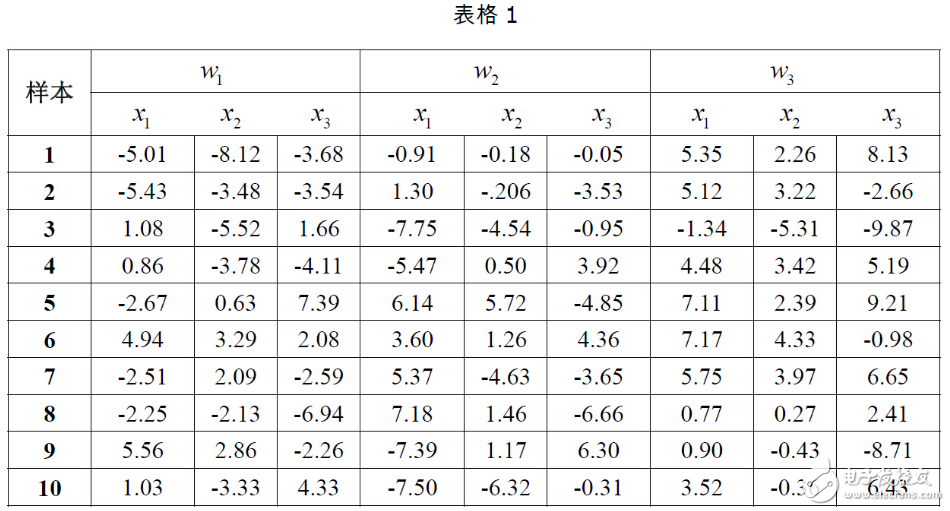
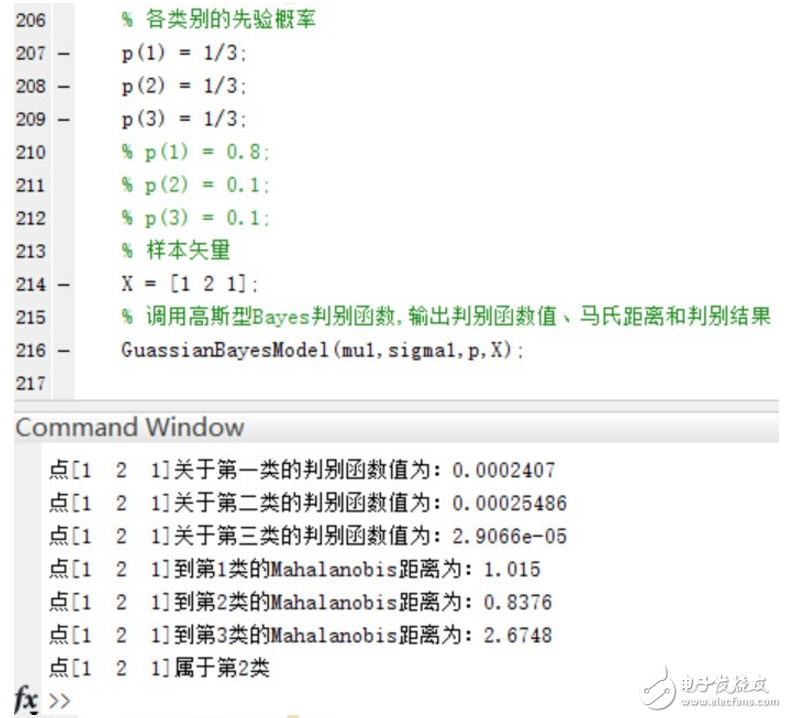
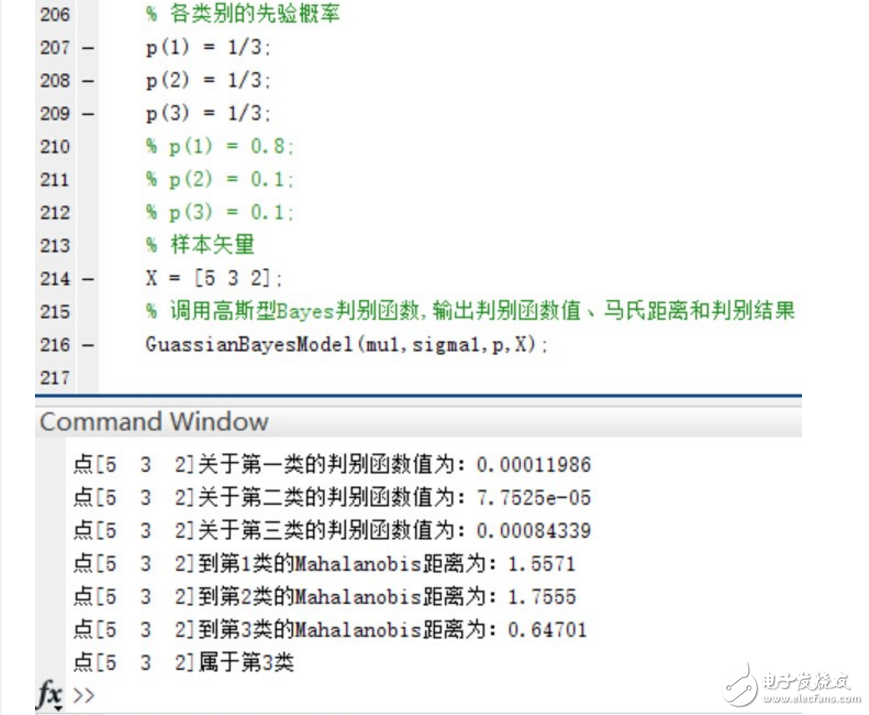
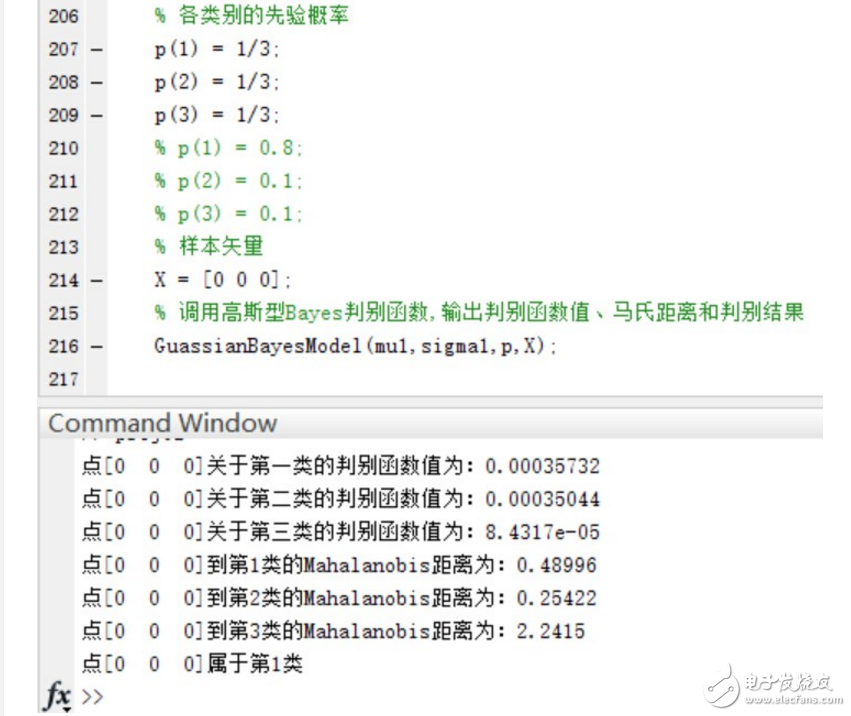
2.以下表格给出了三类样本各10个样本点,假设每一类均为正态分布,三个类别的先验概率相等均为P(w1)=P(w2 )=P(w3 )=1/3。计算每一类样本的均值矢量和协方差矩阵,为这三个类别设计一个分类器。
3.用第二步中设计的分类器对以下测试点进行分类:(1,2,1),(5,3,2),(0,0,0),并且利用以下公式求出各个测试点与各个类别均值之间的Mahalanobis距离。以下是来自百度百科的关于马氏距离的解释:

马氏距离计算公式:
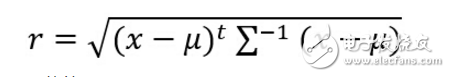
更具体的见: http://baike.baidu.com/link?url=Pcos75ou28q7IukueePCNqf8N7xZifuXOTrwzeWpJULgVrRnytB9Gji6IEhEzlK6q4eTLvx45TAJdXVd7Lnn2q
4.如果P(w1)=0.8, P(w2 )=P(w3 )=0.1,再进行第二步和第三步实验。实验的结果如下:
首先是得出三类样本点各自的均值和协方差矩阵:


在三个类别的先验概率均为P(w1)=P(w2 )=P(w3 )=1/3时,使用函数进行分类并给出分类结果和各个测试点与各个类别均值之间的Mahalanobis距离。
验证当三个类别的先验概率不相等时,同样使用函数进行分类并给出分类结果和各个测试点与各个类别均值之间的Mahalanobis距离。
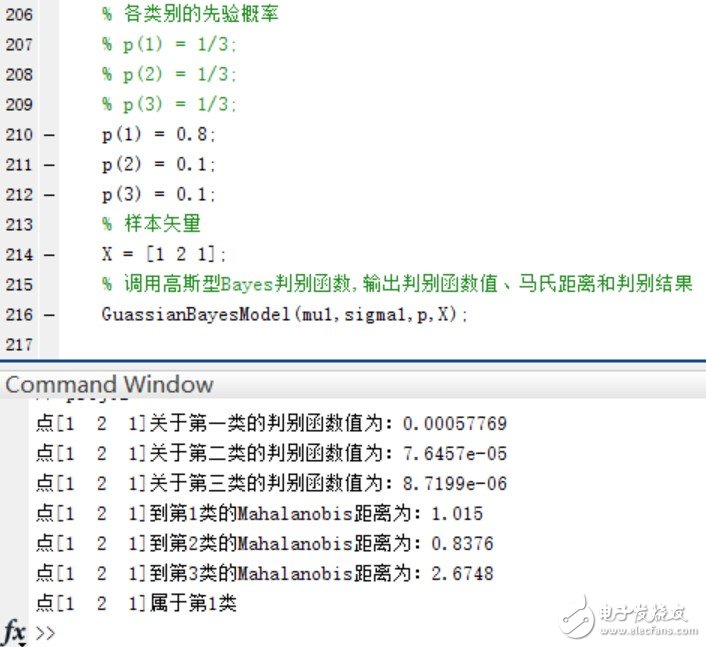
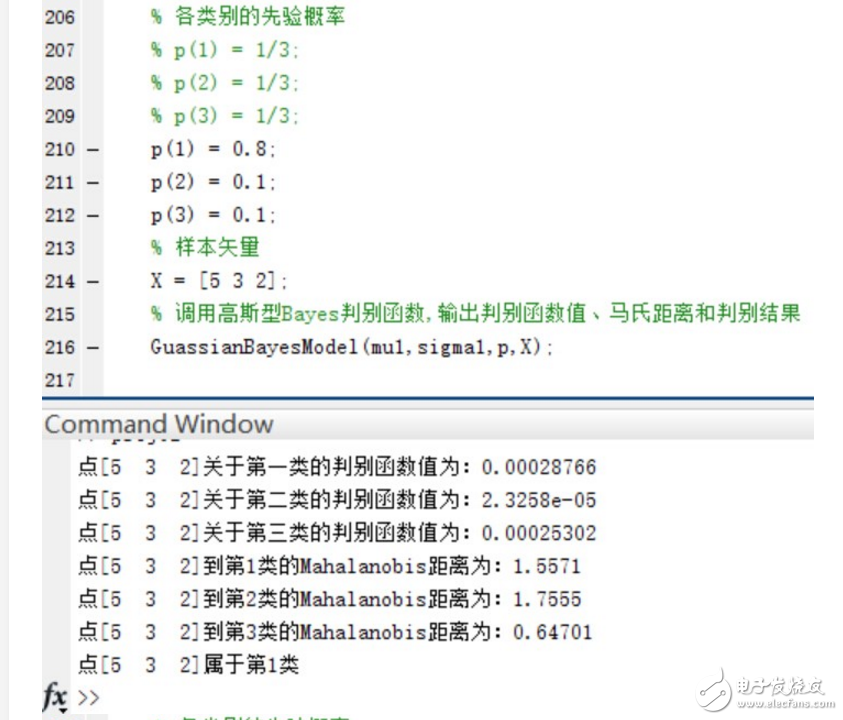
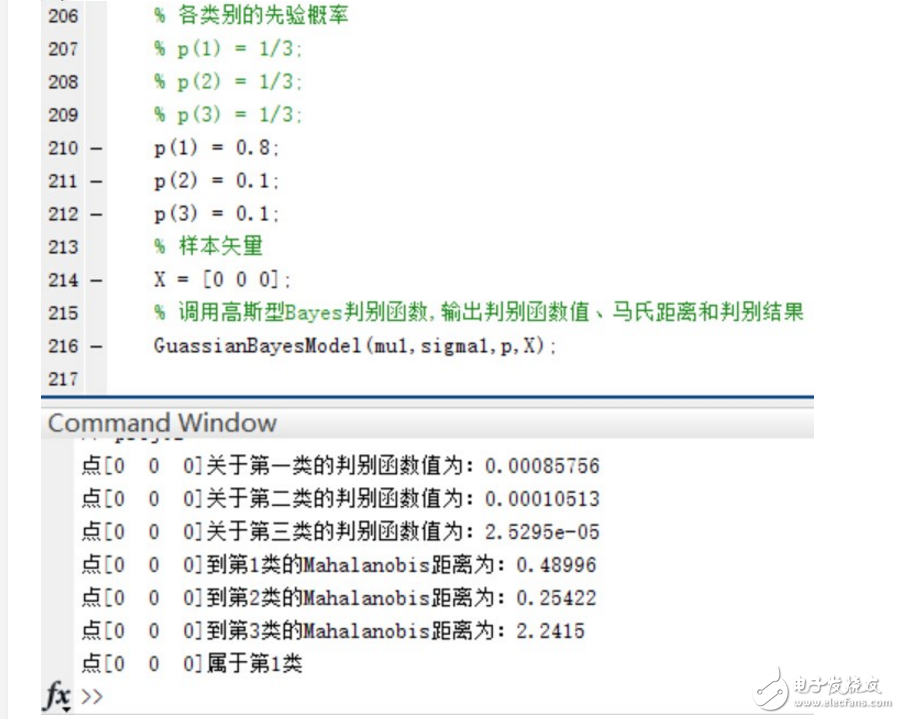
可以看到,在Mahalanobis距离不变的情况下,不同的先验概率对高斯型Bayes分类器的分类结果影响很大~ 事实上,最优判决将偏向于先验概率较大的类别。
完整的代码如下由两个函数和主要的执行流程组成:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 产生模式类函数
% N:生成散点个数 C:类别个数 d:散点的维数
% mu:各类散点的均值矩阵
% sigma:各类散点的协方差矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result = MixGaussian(N, C, d, mu, sigma)
color = {‘r.’, ‘g.’, ‘m.’, ‘b.’, ‘k.’, ‘y.’}; % 用于存放不同类数据的颜色
% if nargin 《= 3 & N 《 0 & C 《 1 & d 《 1
% error(‘参数太少或参数错误’);
if d == 1
for i = 1 : C
for j = 1 : N/C
r(j,i) = sqrt(sigma(1,i)) * randn() + mu(1,i);
end
X = round(mu(1,i)-5);
Y = round(mu(1,i) + sqrt(sigma(1,i))+5);
b = hist(r(:,i), X:Y);
subplot(1,C,i),bar(X:Y, b,‘b’);
title(‘三类一维随机点的分布直方图’);
grid on
end
elseif d == 2
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot(r(:,1,i),r(:,2,i),char(color(i)));
hold on;
end
elseif d == 3
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot3(r(:,1,i),r(:,2,i),r(:,3,i),char(color(i)));
hold on;
end
else disp(‘维数只能设置为1,2或3’);
end
result = r;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 高斯型Bayes判别函数
% mu:输入正态分布的均值
% sigma:输入正态分布的协方差矩阵
% p:输入各类的先验概率
% X:输入样本矢量
% 输出判别函数值、马氏距离和判别结果
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function GuassianBayesModel( mu,sigma,p,X )
% 构建判别函数
% 计算点到每个类的Mahalanobis距离
for i = 1:3;
P(i) = mvnpdf(X, mu(:,:,i), sigma(:,:,i)) * p(i);
r(i) = sqrt((X - mu(:,:,i)) * inv(sigma(:,:,i)) * (X - mu(:,:,i))‘);
end
% 判断样本属于哪个类的概率最高
% 并显示点到每个类的Mahalanobis距离
maxP = max(P);
style = find(P == maxP);
disp([’点[‘,num2str(X),’]关于第一类的判别函数值为:‘,num2str(P(1))]);
disp([’点[‘,num2str(X),’]关于第二类的判别函数值为:‘,num2str(P(2))]);
disp([’点[‘,num2str(X),’]关于第三类的判别函数值为:‘,num2str(P(3))]);
disp([’点[‘,num2str(X),’]到第1类的Mahalanobis距离为:‘,num2str(r(1))]);
disp([’点[‘,num2str(X),’]到第2类的Mahalanobis距离为:‘,num2str(r(2))]);
disp([’点[‘,num2str(X),’]到第3类的Mahalanobis距离为:‘,num2str(r(3))]);
disp([’点[‘,num2str(X),’]属于第‘,num2str(style),’类‘]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%贝叶斯分类器实验主函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 生成两类各100个散点样本
mu(:,:,1) = [1 3];
sigma(:,:,1) = [1.5 0; 0 1];
p1 = 1/2;
mu(:,:,2) = [3 1];
sigma(:,:,2) = [1 0.5; 0.5 2];
p2 = 1/2;
% 生成200个二维散点,平分为两类,每类100个
aa = MixGaussian(200, 2, 2, mu, sigma);
title(’两类共200个高斯分布的散点‘);
% 只x分量作为分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 计算后验概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1;% 统计正确个数
elseif P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
rightRate1 = right1 / 100; % 正确率
for i = 1:100
x = aa(i,1,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 计算后验概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
elseif P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1; % 统计正确个数
end
end
rightRate2 = right2 / 100;
title(’使用第一个分类特征的分类结果‘);
disp([’只用第一个特征时,第一类分类的准确率为:‘,num2str(rightRate1*100),’%‘]);
disp([’只用第一个特征时,第二类分类的准确率为:‘,num2str(rightRate2*100),’%‘]);
% 只使用y分量的分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 计算后验概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1; % 统计正确个数
elseif P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
rightRate1 = right1 / 100; % 正确率
for i = 1:100
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 计算后验概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
elseif P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1; % 统计正确个数
end
end
rightRate2 = right2 / 100; % 正确率
title(’使用第二个分类特征的分类结果‘);
disp([’只用第二个特征时,第一类分类的准确率为:‘,num2str(rightRate1*100),’%‘]);
disp([’只用第二个特征时,第二类分类的准确率为:‘,num2str(rightRate2*100),’%‘]);
% 同时使用两个分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 计算后验概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1;
else if P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
end
rightRate1 = right1 / 100;
for i = 1:100
x = aa(i,1,2);
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 计算后验概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
else if P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1;
end
end
end
rightRate2 = right2 / 100;
title(’使用两个分类特征的分类结果‘);
disp([’同时使用两个特征时,第一类分类的准确率为:‘,num2str(rightRate1*100),’%‘]);
disp([’同时使用两个特征时,第二类分类的准确率为:‘,num2str(rightRate2*100),’%‘]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 进一步的Bayes分类器
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% w1,w2,w3三类散点
w = zeros(10,3,3);
w(:,:,1) = [-5.01 -8.12 -3.68;。。。
-5.43 -3.48 -3.54;。。。
1.08 -5.52 1.66;。。。
0.86 -3.78 -4.11;。。。
-2.67 0.63 7.39;。。。
4.94 3.29 2.08;。。。
-2.51 2.09 -2.59;。。。
-2.25 -2.13 -6.94;。。。
5.56 2.86 -2.26;。。。
1.03 -3.33 4.33];
w(:,:,2) = [-0.91 -0.18 -0.05;。。。
1.30 -.206 -3.53;。。。
-7.75 -4.54 -0.95;。。。
-5.47 0.50 3.92;。。。
6.14 5.72 -4.85;。。。
3.60 1.26 4.36;。。。
5.37 -4.63 -3.65;。。。
7.18 1.46 -6.66;。。。
-7.39 1.17 6.30;。。。
-7.50 -6.32 -0.31];
w(:,:,3) = [ 5.35 2.26 8.13;。。。
5.12 3.22 -2.66;。。。
-1.34 -5.31 -9.87;。。。
4.48 3.42 5.19;。。。
7.11 2.39 9.21;。。。
7.17 4.33 -0.98;。。。
5.75 3.97 6.65;。。。
0.77 0.27 2.41;。。。
0.90 -0.43 -8.71;。。。
3.52 -0.36 6.43];
% 均值
mu1(:,:,1) = sum(w(:,:,1)) 。/ 10;
mu1(:,:,2) = sum(w(:,:,2)) 。/ 10;
mu1(:,:,3) = sum(w(:,:,3)) 。/ 10;
% 协方差矩阵
sigma1(:,:,1) = cov(w(:,:,1));
sigma1(:,:,2) = cov(w(:,:,2));
sigma1(:,:,3) = cov(w(:,:,3));
% 各类别的先验概率
% p(1) = 1/3;
% p(2) = 1/3;
% p(3) = 1/3;
p(1) = 0.8;
p(2) = 0.1;
p(3) = 0.1;
% 样本矢量
X = [1 0 0];
% 调用高斯型Bayes判别函数,输出判别函数值、马氏距离和判别结果
GuassianBayesModel(mu1,sigma1,p,X);
-
模式识别与人工智能2023-08-15 4883
-
模式识别技术有哪些_模式识别技术的应用2020-11-10 9720
-
使用Opencv进行模式识别与分类的入门教程免费下载2019-10-29 892
-
浅谈模式识别2018-03-28 4043
-
PRSD Studio模式识别工具箱功能及使用方法2018-01-04 1858
-
贝叶斯分类器原理及应用分析2017-11-30 12973
-
基于LDA分类器的模式识别方法2017-11-24 1194
-
模式识别PPT2014-01-11 2226
-
模式识别,模式识别是什么意思2010-03-06 2176
-
基于贝叶斯分类研究肌肉动作模式识别方法2010-02-22 1178
-
基于模糊模式识别的车型分类研究2009-07-07 720
-
什么是模式识别2009-04-10 3224
全部0条评论

快来发表一下你的评论吧 !
