

贝叶斯分类器的优缺点解析
电子常识
描述
应用贝叶斯网络分类器进行分类主要分成两阶段。第一阶段是贝叶斯网络分类器的学习,即从样本数据中构造分类器,包括结构学习和CPT 学习;第二阶段是贝叶斯网络分类器的推理,即计算类结点的条件概率,对分类数据进行分类。这两个阶段的时间复杂性均取决于特征值间的依赖程度,甚至可以是NP 完全问题,因而在实际应用中,往往需要对贝叶斯网络分类器进行简化。根据对特征值间不同关联程度的假设,可以得出各种贝叶斯分类器,Naive Bayes、TAN、BAN、GBN 就是其中较典型、研究较深入的贝叶斯分类器。
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。目前研究较多的贝叶斯分类器主要有四种,分别是:Naive Bayes、TAN、BAN和GBN。
贝叶斯分类器
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。目前研究较多的贝叶斯分类器主要有四种,分别是:Naive Bayes、TAN、BAN和GBN。
训练
和所有监督算法一样,贝叶斯分类器是利用样本进行训练的,每个样本包含了一个特征列表和对应的分类。假定我们要对一个分类器进行训练,使其能够正确的判断出:一个包含“python”的文档究竟是编程语言的,还是关于蛇的。
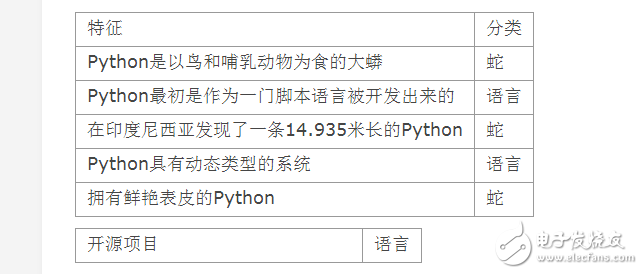
分类器记录了它迄今为止见过的所有特征,以及这些特征与某个特定分类相关的数字概率。分类器逐一接受样本的训练。 当经过某个样本的训练之后,分类器会更新该样本中特征与分类的概率,同时还会生成一个新的概率,即:在一篇属于某个分类的文档中,含有指定单词的概率。例如
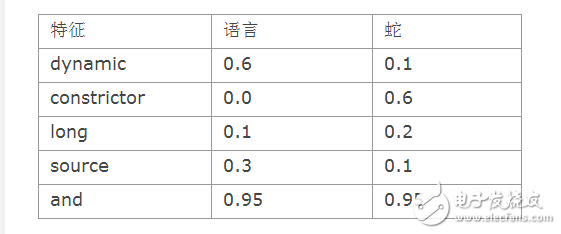
从上表中我们可以看到,经过训练之后,特征与各种分类的关联性更加明确了。单词“constrictor”属于蛇的分类概率更大,而单词“dynamic”属于编程语言的概率更大。
另一方便,有些特征的所属分类则没有那么明确。比如:单词“and”出现在两个分类中的概率是差不多的(单词and几乎会出现在每一篇文档中,不管它属于哪一个分类。)分类器在经过训练之后。只会保留一个附有相应概率的特征列表,与某些其他的分类方法不同,此处的原始数据在训练之后,就没有必要再加以保存了。
分类
当一个贝叶斯分类器经过训练之后,我们就可以利用它来对新的项目进行自动分类了。假定我们有一篇新的文档,包含了“long” “dynamic” 和 “source”。
朴素贝叶斯分类器是通过下面的公式将概率组合起来的: P( Category | Document) = P ( Document | Category ) * P( Category) / P(Document)
此处:
P( Document | Category) = P (Word1 | Category ) * P( Word2) / P(Category )
p( Document | Category) 的取值来自于上表,比如 P( dynamic | language) = 0.6
p(Category) 的取值则等于某个分类出现的总体概率,因为“ language ” 有一般的机会都会出现,所以 P(language ) 的值为0.5 。无论是哪个分类,只要其P( Category | Document) 的值相对较高,它就是我们预期的分类。
我们需要一个定义一个特征提取函数,该函数的作用是将我们用以训练或分类的数据转化成一个特征列表。
docclass.getwords(‘python is a dynamic language’) {‘python’:1,‘dymaic’:1,‘language’:1}
上述函数可用于创建一个新的分类器,针对字符串进行训练: cl = docclass.nativebayes(docclass.getwords)cl.setdb(‘test.db’) cl.train(‘pythons are constrictors’,‘snake’) cl.train(‘python has dynamic types’,‘language’)cl.train(‘python was developed as a scripting language’,‘language’)
然后进行分类 cl.classify(‘dynamic programming’) u‘language’ cl.classify(‘boa constrictors’) u‘snake’
对于允许使用的分类数量,此处并没有任何的限制,但是为了使分类器有一个良好的表现,我们需要为每个分类提供大量的样本。
贝叶斯分类器优点和缺点
朴素贝叶斯分类器与其他方法相比最大的优势或许就在于,它在接受大数据量训练和查询时所具备的的高速度。即使选用超大规模的训练集,针对每个项目通常也只会有相对较少的特征数,并且对项目的训练和分类页仅仅是针对特征概率的数学运算而已。
尤其当训练量逐渐递增时则更加如此--在不借助任何旧有训练数据的前提下,每一组新的训练数据都有可能会引起概率值变化。对于一个如垃圾邮件过滤这样的应用程序而言,支持增量式训练的能力是非常重要的,因为过滤程序时常要对新到的邮件进行训练,然后必须即可进行相应的调整;更何况,过滤程序也未必有权限访问已经收到的所有邮件信息。
朴素贝叶斯分类器的另一大优势是,对分类器实际学习状况的解释还是相对简单的。由于每个特征的概率值都被保存了起来,因此我们可以在任何时候查看数据库,找到最合适的特征来区分垃圾邮件和非垃圾邮件,或是编程语言和蛇。保存在数据库中的这些信息都很有价值,它们有可能被用于其他的应用程序,或者作为构筑这些应用程序的一个良好基础。
朴素贝叶斯分类器的最大缺陷就是,它无法处理基于特征组合所产生的变化结果。假设有如下这样一个场景,我们正在尝试从非垃圾邮件中鉴别出垃圾邮件来:假设我们构建的是一个Web应用程序,因为单词“online”市场会出现在你的工作邮件中。而你的好友则在一家药店工作,并且喜欢给你发一些他碰巧在工作中遇到的奇闻趣事。同时,和大多数不善于严密保护自己邮件地址的人一样,偶尔你也会收到一封包含单词”online pharmacy“的垃圾邮件。
也许你已经看出此处的难点--我们往往会告诉分类器”onlie“和”pharmacy“是出现在非垃圾邮件中的,因此这些单词相对于非垃圾邮件的概率会高一些。当我们告诉分类器有一封包含单词”onlie pharmacy“ 的邮件属于垃圾邮件时,则这些单词的概率又会进行相应的调整,这就导致了一个经常性的矛盾。由于特征的概率是单独给出的,因此分类器对于各种组合的情况一无所知。在文档分类中,这通常不是什么大问题,因为一封包含单词”online pharmacy“的邮件中可能还会有其他的特征可以说明它是垃圾邮件,但是在面对其他问题时,理解特征的组合可能是至关重要的。
- 相关推荐
- 热点推荐
- 贝叶斯分类器
-
太阳能发电的组成、优缺点解析2023-04-16 6774
-
IO口的输入有哪些分类及其优缺点呢2022-02-28 868
-
ADC技术有哪些分类?优缺点是什么?2021-10-18 3015
-
软性PCB有哪些分类?优缺点是什么?2021-04-26 2000
-
一文解析主动分频器和被动分频器的优缺点2018-05-28 53310
-
soa架构的优缺点解析2018-02-07 29358
-
ofdm技术的优缺点解析,ofdm技术原理介绍2017-12-12 93420
-
模式识别贝叶斯分类器概念2017-11-30 3443
-
液晶屏的分类和液晶屏的优缺点2017-03-24 2528
-
智能指纹解锁六大功能及其优缺点解析2014-11-10 6680
-
正投、背投、吊装以及桌面安装的优缺点解析2010-02-04 14050
-
朴素贝叶斯分类器一阶扩展的注记2009-04-18 684
-
液位计的分类、测量原理及优缺点2008-01-07 3518
全部0条评论

快来发表一下你的评论吧 !
