

最大似然检测算法认识与理解
转换器/收发器
描述
最大似然检测
最大似然检测(Maximum Likelihood,ML)检测,也被称作最大似然序列估计(MLSE),从严格意义上讲它不是均衡方案而是接收机方式,其中接收端的检测处理显式地考虑了无线信道时间弥散的影响。从根本上讲,ML检测器考虑了时间弥散对接收信号的影响,用整个接收信号来确定最有可能被发送的序列。为了实现最大似然检测,通常使用Viterbi算法。然而,尽管基于Viterbi算法的最大似然检测被广泛应用于诸如GSM的2G通信,该算法还是因为太过复杂而无法应用在LTE上,这是因为更宽的传输带宽将导致更广泛的信道频率选择性和更高的采样速率。
总的来说,信号信息经过信道估计和均衡后,通过资源逆映射映射到不同的物理信道上进行处理
一、最大似然
假设我们需要调查我们学校的男生和女生的身高分布。你怎么做啊?你说那么多人不可能一个一个去问吧,肯定是抽样了。假设你在校园里随便地活捉了100个男生和100个女生。他们共200个人(也就是200个身高的样本数据,为了方便表示,下面,我说“人”的意思就是对应的身高)都在教室里面了。那下一步怎么办啊?你开始喊:“男的左边,女的右边,其他的站中间!”。然后你就先统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。
用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度p(x|θ)抽取100了个(身高),组成样本集X,我们想通过样本集X来估计出未知参数θ。这里概率密度p(x|θ)我们知道了是高斯分布N(u,∂)的形式,其中的未知参数是θ=[u, ∂]T。抽到的样本集是X={x1,x2,…,xN},其中xi表示抽到的第i个人的身高,这里N就是100,表示抽到的样本个数。
由于每个样本都是独立地从p(x|θ)中抽取的,换句话说这100个男生中的任何一个,都是我随便捉的,从我的角度来看这些男生之间是没有关系的。那么,我从学校那么多男生中为什么就恰好抽到了这100个人呢?抽到这100个人的概率是多少呢?因为这些男生(的身高)是服从同一个高斯分布p(x|θ)的。那么我抽到男生A(的身高)的概率是p(xA|θ),抽到男生B的概率是p(xB|θ),那因为他们是独立的,所以很明显,我同时抽到男生A和男生B的概率是p(xA|θ)* p(xB|θ),同理,我同时抽到这100个男生的概率就是他们各自概率的乘积了。用数学家的口吻说就是从分布是p(x|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
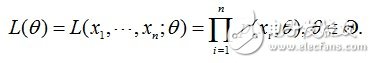
这个概率反映了,在概率密度函数的参数是θ时,得到X这组样本的概率。因为这里X是已知的,也就是说我抽取到的这100个人的身高可以测出来,也就是已知的了。而θ是未知了,则上面这个公式只有θ是未知数,所以它是θ的函数。这个函数放映的是在不同的参数θ取值下,取得当前这个样本集的可能性,因此称为参数θ相对于样本集X的似然函数(likehood function)。记为L(θ)。
这里出现了一个概念,似然函数。还记得我们的目标吗?我们需要在已经抽到这一组样本X的条件下,估计参数θ的值。怎么估计呢?似然函数有啥用呢?那咱们先来了解下似然的概念。
直接举个例子:
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,看来这一枪是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想。
再例如:下课了,一群男女同学分别去厕所了。然后,你闲着无聊,想知道课间是男生上厕所的人多还是女生上厕所的人比较多,然后你就跑去蹲在男厕和女厕的门口。蹲了五分钟,突然一个美女走出来,你狂喜,跑过来告诉我,课间女生上厕所的人比较多,你要不相信你可以进去数数。呵呵,我才没那么蠢跑进去数呢,到时还不得上头条。我问你是怎么知道的。你说:“5分钟了,出来的是女生,女生啊,那么女生出来的概率肯定是最大的了,或者说比男生要大,那么女厕所的人肯定比男厕所的人多”。看到了没,你已经运用最大似然估计了。你通过观察到女生先出来,那么什么情况下,女生会先出来呢?肯定是女生出来的概率最大的时候了,那什么时候女生出来的概率最大啊,那肯定是女厕所比男厕所多人的时候了,这个就是你估计到的参数了。
从上面这两个例子,你得到了什么结论?
回到男生身高那个例子。在学校那么男生中,我一抽就抽到这100个男生(表示身高),而不是其他人,那是不是表示在整个学校中,这100个人(的身高)出现的概率最大啊。那么这个概率怎么表示?哦,就是上面那个似然函数L(θ)。所以,我们就只需要找到一个参数θ,其对应的似然函数L(θ)最大,也就是说抽到这100个男生(的身高)概率最大。这个叫做θ的最大似然估计量,记为:
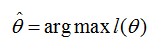
有时,可以看到L(θ)是连乘的,所以为了便于分析,还可以定义对数似然函数,将其变成连加的:
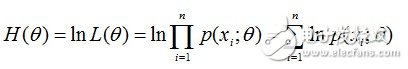
好了,现在我们知道了,要求θ,只需要使θ的似然函数L(θ)极大化,然后极大值对应的θ就是我们的估计。这里就回到了求最值的问题了。怎么求一个函数的最值?当然是求导,然后让导数为0,那么解这个方程得到的θ就是了(当然,前提是函数L(θ)连续可微)。那如果θ是包含多个参数的向量那怎么处理啊?当然是求L(θ)对所有参数的偏导数,也就是梯度了,那么n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了,当然就得到这n个参数了。
最大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后寻求使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险时不抽烟者的5倍,那么如果现在我已经知道有个人是肺癌,我想问你这个人抽烟还是不抽烟。你怎么判断?你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更有可能会说,这个人抽烟。为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计值才是“最有可能”得到“肺癌”这样的结果。这就是最大似然估计。
好了,极大似然估计就讲到这,总结一下:
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
最大似然译码算法在LTE上的应用
假定调制星座图中的所有信号都是等概的,最大似然译码器对所有可能的见,和妥2值,从信号调制星座图中选择一对信号(二。,见2)使下面的距离量度最小
d2 r1,h1x 1+h2x 2 +d2 r2,−h1x 2∗+h2x 1∗ =|h1−h1x 1−h2x 2|2+|r2,+h1x 2∗−h2x 1∗|2
(1)
化简得最大似然译码判决准则为:
x 1,x 2 =argmin(x 1,x 2)ϵC(|h1|2+|h2|2−1)(|x1|2+|x 2|2)+d2 x1,x 1 +d2 x2,x 2
(2)
上式中:C为调制符号对(x 1,x 2)所有可能的集合; x 1和x 2是通过合并接收信号和信道状态信息构造产生的两个判决统计。统计结果可以表示为
x1=h1∗r1+h1r2∗(3)
x2=h2∗r1−h1r2∗ (4)
将式(3)和式(4)中的r1和r2分别代人式(5)中,统计结果可以表示为
x1=(|h1|2+ h2|2 x1+h1∗n1+h2n2∗ (5)
x2=(|h1|2+ h2|2 x2−h1n2∗+h2∗n1 (6)
对于给定信道实现h1和h2而言,统计结果见xi(i=1,2)仅仅是xi(i=1,2)的函数,因此,可以将最大似然译码准则式(4)分为对于x1和x2的2个独立译码算法,即
x 1=argminx2∈S(|h1|2+|h2|2−1)×|x 1|2+d2 x1,x 1 (7)
和
x 2=argminx2∈S(|h1|2+|h2|2−1)×|x 2|2+d2 x2,x 2 (8)
对于M-PSK信号星座图而言,在给定信号衰落系数的前提下,(|h1|2+|h2|2−1)×|x i|2(i=1,2)对于所有信号都是恒定的,因此可以将式(7)和式 (8)的判决准则进一步简化为
x 1=argminx2∈S(x1,x 1)=argminx2∈S|h1∗r1+h2r1∗−x 1|2
x 2=argminx2∈S(x2,x 2)=argminx2∈S|h2∗r1−h1r2∗−x2|2
上述最大似然检测算法可以推广到多个接收天线的情况。
最大似然估计学习总结------MadTurtle
1. 作用
在已知试验结果(即是样本)的情况下,用来估计满足这些样本分布的参数,把可能性最大的那个参数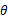 作为真实
作为真实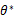 的参数估计。
的参数估计。
2. 离散型
设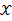 为离散型随机变量,
为离散型随机变量,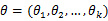 为多维参数向量,如果随机变量
为多维参数向量,如果随机变量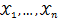 相互独立且概率计算式为P{
相互独立且概率计算式为P{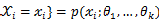 ,则可得概率函数为P{
,则可得概率函数为P{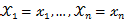 }=
}=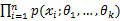 ,在
,在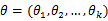 固定时,上式表示
固定时,上式表示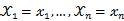 的概率;当
的概率;当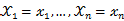 已知的时候,它又变成
已知的时候,它又变成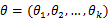 的函数,可以把它记为
的函数,可以把它记为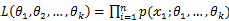 ,称此函数为似然函数。似然函数值的大小意味着该样本值出现的可能性的大小,既然已经得到了样本值
,称此函数为似然函数。似然函数值的大小意味着该样本值出现的可能性的大小,既然已经得到了样本值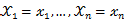 ,那么它出现的可能性应该是较大的,即似然函数的值也应该是比较大的,因而最大似然估计就是选择使
,那么它出现的可能性应该是较大的,即似然函数的值也应该是比较大的,因而最大似然估计就是选择使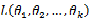 达到最大值的那个
达到最大值的那个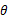 作为真实
作为真实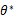 的估计。
的估计。
3. 连续型
设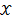 为连续型随机变量,其概率密度函数为
为连续型随机变量,其概率密度函数为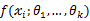 ,
,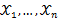 为从该总体中抽出的样本,同样的如果
为从该总体中抽出的样本,同样的如果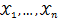 相互独立且同分布,于是样本的联合概率密度为
相互独立且同分布,于是样本的联合概率密度为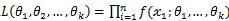 。大致过程同离散型一样。
。大致过程同离散型一样。
4. 关于概率密度(PDF)
我们来考虑个简单的情况(m=k=1),即是参数和样本都为1的情况。假设进行一个实验,实验次数定为10次,每次实验成功率为0.2,那么不成功的概率为0.8,用y来表示成功的次数。由于前后的实验是相互独立的,所以可以计算得到成功的次数的概率密度为:
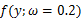 =
=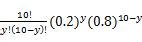 其中y
其中y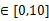
由于y的取值范围已定,而且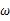 也为已知,所以图1显示了y取不同值时的概率分布情况,而图2显示了当
也为已知,所以图1显示了y取不同值时的概率分布情况,而图2显示了当 时的y值概率情况。
时的y值概率情况。
那么 在[0,1]之间变化而形成的概率密度函数的集合就形成了一个模型。
在[0,1]之间变化而形成的概率密度函数的集合就形成了一个模型。
5. 最大似然估计的求法
由上面的介绍可以知道,对于图1这种情况y=2是最有可能发生的事件。但是在现实中我们还会面临另外一种情况:我们已经知道了一系列的观察值和一个感兴趣的模型,现在需要找出是哪个PDF(具体来说参数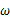 为多少时)产生出来的这些观察值。要解决这个问题,就需要用到参数估计的方法,在最大似然估计法中,我们对调PDF中数据向量和参数向量的角色,于是可以得到似然函数的定义为:
为多少时)产生出来的这些观察值。要解决这个问题,就需要用到参数估计的方法,在最大似然估计法中,我们对调PDF中数据向量和参数向量的角色,于是可以得到似然函数的定义为:
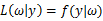
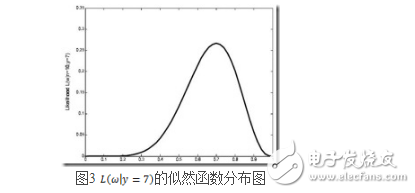
该函数可以理解为,在给定了样本值的情况下,关于参数向量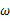 取值情况的函数。还是以上面的简单实验情况为例,若此时给定y为7,那么可以得到关于
取值情况的函数。还是以上面的简单实验情况为例,若此时给定y为7,那么可以得到关于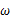 的似然函数为:
的似然函数为:
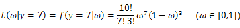
继续回顾前面所讲,图1,2是在给定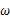 的情况下,样本向量y取值概率的分布情况;而图3是图1,2横纵坐标轴相交换而成,它所描述的似然函数图则指出在给定样本向量y的情况下,符合该取值样本分布的各种参数向量
的情况下,样本向量y取值概率的分布情况;而图3是图1,2横纵坐标轴相交换而成,它所描述的似然函数图则指出在给定样本向量y的情况下,符合该取值样本分布的各种参数向量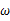 的可能性。若
的可能性。若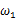 相比于
相比于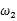 ,使得y=7出现的可能性要高,那么理所当然的
,使得y=7出现的可能性要高,那么理所当然的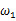 要比
要比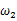 更加接近于真正的估计参数。所以求
更加接近于真正的估计参数。所以求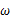 的极大似然估计就归结为求似然函数
的极大似然估计就归结为求似然函数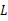 的最大值点。那么
的最大值点。那么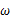 取何值时似然函数
取何值时似然函数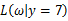 最大,这就需要用到高等数学中求导的概念,如果是多维参数向量那么就是求偏导。
最大,这就需要用到高等数学中求导的概念,如果是多维参数向量那么就是求偏导。
主要注意的是多数情况下,直接对变量进行求导反而会使得计算式子更加的复杂,此时可以借用对数函数。由于对数函数是单调增函数,所以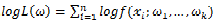 与
与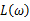 具有相同的最大值点,而在许多情况下,求
具有相同的最大值点,而在许多情况下,求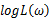 的最大值点比较简单。于是,我们将求
的最大值点比较简单。于是,我们将求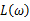 的最大值点改为求
的最大值点改为求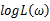 的最大值点。
的最大值点。
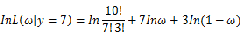
若该似然函数的导数存在,那么对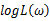 关于参数向量的各个参数求导数(当前情况向量维数为1),并命其等于零,得到方程组:
关于参数向量的各个参数求导数(当前情况向量维数为1),并命其等于零,得到方程组:
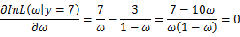
可以求得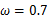 时似然函数有极值,为了进一步判断该点位最大值而不是最小值,可以继续求二阶导来判断函数的凹凸性,如果
时似然函数有极值,为了进一步判断该点位最大值而不是最小值,可以继续求二阶导来判断函数的凹凸性,如果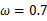 的二阶导为负数那么即是最大值,这里再不细说。
的二阶导为负数那么即是最大值,这里再不细说。
还要指出,若函数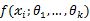 关于
关于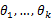 的导数不存在,我们就无法得到似然方程组,这时就必须用其它的方法来求最大似然估计值,例如用有界函数的增减性去求
的导数不存在,我们就无法得到似然方程组,这时就必须用其它的方法来求最大似然估计值,例如用有界函数的增减性去求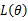 的最大值点
的最大值点
-
人脸检测算法及新的快速算法2013-09-26 3952
-
基于YOLOX目标检测算法的改进2023-03-06 1571
-
基于极大似然法的椒盐噪声滤波算法2009-08-04 690
-
认知无线电中基于信息简约的最大似然协同频谱感知算法2009-11-09 988
-
机载MIMO雷达广义最大似然检测器2009-11-17 1259
-
基于平均似然比的鲁棒性突发检测2010-02-08 718
-
V-BLAST系统中一种基于噪声分析的简化最大似然检测算法2010-03-05 629
-
基于广义似然比的频谱感知算法_张兵2017-03-19 876
-
空间调制系统下改进的QRD-M检测算法2018-12-11 1433
-
基于深度学习的目标检测算法2021-04-30 11742
-
认知无线电子中子频确实下的似然恢复算法综述2021-05-12 835
-
GMSK准相干解调和最大似然解调代码2022-10-27 1476
-
基于Transformer的目标检测算法2023-08-16 1174
全部0条评论

快来发表一下你的评论吧 !
