

利用代间差分遗传算法优化分形图像编码速度
电子常识
描述
分形图像压缩技术是利用数字图像本身固有的自相似性,在分形理论的指导下,把图像数据转变为相关的分形参数,从而达到对数据进行压缩的目的。在一些情况下分形压缩可以达到非常高的压缩比,因此这是一种极具发展潜力的图像压缩技术。
分形图像压缩的概念首先由Barnsley提出,但是Barnsely基于IFS的分形压缩方法在实话时需要人机交互,无法实现自动化的压缩过程。1990年,Janquin利用局部仿射变换代替全局仿射变换而提出了一种全自动的分形图像压缩方法,使这种图像压缩技术向实用化迈进一了步。Janquin方式虽然解决了Barnsley的子图分割问题,但是搜索最佳匹配块的计算量是十分可观的。为了减小计算量,从90年代起又有许多改进方法被提出,例如分类搜索法、四叉树搜索法等。这些方法虽然在一定程度上节约了搜索时间,但仍需进一步减小编码所需要的时间。
遗传算法是人类在自然进化的启发下发展的一种随机搜索算法,在大计算量面前具有快速自寻优的能力。目前人们已经开始利用遗传算法对分形编码的编码速度进行优化。本文为了进一步提高分形压缩的编码速度,深入研究了每个值域块、所有定义域块与其相似程度的分布特点,推导了适用于分形编码的代间差分遗传算法;然后利用代间差分遗传算法优化分形编码。实验表明代间差分遗传算法较变通遗传算法具有更快的收敛速度。
1 分形图像压缩的基本原理
分形理论是现代非线性科学中一门非常活跃且应用十分广泛的学科,特别随着计算机技术的发展,分形思想和方法在模式识别、自然图像的模拟、信号处理等各个领域都取得了巨大的成功。
分形编码的主要过程如下:首先将图像I分割成互不相交的值域块{Ri},对每个值域块,在整个图像范围寻找其在压缩、仿射变换下的最佳匹配定义域块Di,记录下该定义域块和所采用的变换,完成了一个子块的编码;对于所有值域块{Ri}重复上述过程分别寻找各自的最优匹配定义域块,即完成整幅图像的编码。
在仿射变换下,定义域和值域的误差可由下式确定:
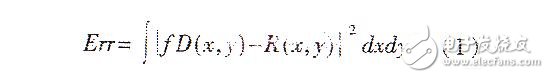
所谓某个值域块Ri的最优匹配定义域就是:在f映射下,定义域块和值域块使(1)式最小。利用Janquin方法进行编码,为了找到具有最小误差Err的定义域块,即最优匹配定义域块,每一个值域块Ri需要匹配的定义域块数为(假设图像、定义域块以及值域块都是正方形):
Num=(图像大小-定义域块大小+1)2×仿射变换种数
例如,对于一个大小为256×256的图像,如果选取值域块为16×16,定义块为32×32,则每个值域块要搜索的定义域块为50625。可见该匹配过程的计算量非常大。
2 代间差分遗传算法的基本思想
遗传算法是一种具有内在并行性的优化算法,本文试图利用遗传算法的优化能力改善编码过程。同时针对分形编码过程的特点,为了提高算法的收敛速度,对遗传算法进行了改进,提出了带有代间差分杂交算子的遗传算法。
遗传算法中的杂交算子是一类非常重要的算子,杂交算子的性以也直接影响整个算法的收敛速度。本文提出的代间差分霜交算子其思想为:遗传算法是根据自然界中生物进化、适者生存的思想而发展的一种优化算法;随着种群进化代数的增加,在选择算子等的作用下,种群的平均适应值将以大概率增加。这样有理由假定种群的适应值将随着进化代数的增加而单调增加,从相邻两代种群中随机选择一个个体,则两个个体的差以一定概率代表了种群适应值增加的方向,也就是所希望的进化方向。因此可以利用相邻两代种群中个体的差来构成新的杂交算子,以产生新的个体,该新个体将以更高的概率向量优解靠近。
本文在不产生混淆的情况下,把采用代间差分杂交算子的遗传算法称为代间差分遗传算法。
3 基于代间差分遗传算法的快速分形压缩算法
3.1 分形编码中值域块与定义域块相似度分布特点
笔者经过大量的研究发现,在分形编码的过程中某一值域块与所有定义域块的相似程度分布具有以下特点:
(1) 该分布是一个多极值的函数,因此寻找某一值域块的最佳匹配定义域块的过程实际上是求解一个多极值函数的最大值问题;
(2) 分布函数的取值在每一个极值附近连续变化,即在最大相似块附近的定义域块,(5) 其与值域块的相似度是逐渐变化的。
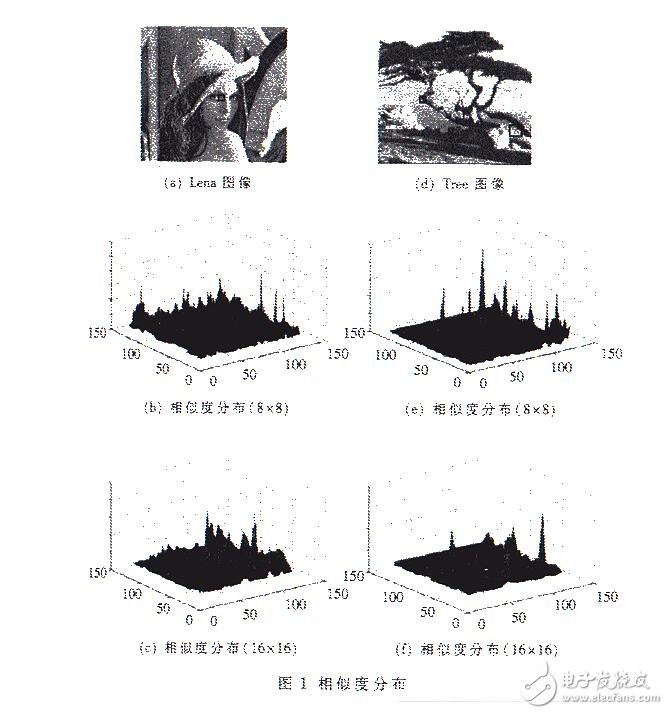
图1是Lena图像和Tree图像中某一值域块与所有定义域块相似度分布的情况,值域块分8×8和16×16两种情况随机选取,相似度由(2)式确定:
ada=1/Err (2)
其中,Err由(1)式确定。
相似度的分布由图1(b)、(c)和图1(e)、(f)给出,可以看到,相似度的分布符合上述两个特点。
3.2 构造代间差分杂算子
由于分形编码中值域块与定义域块相似度分布具有以上特点,使得代间差分遗传算法的思想在这里适用,因此可以利用代间差分遗传算法优化分形编码过程。下面构造可用于分形编码过程的代间差分杂交算子。
本文要进行搜索的空间由图像定义域块的全体构成,对于每个定义块可以用左上角像素点的坐标表示,则对应的遗传算法中的一个个体可以表示为:x=(x,y)。种群中个体的适应度由(3)式确定。
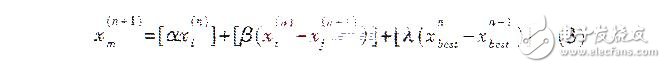
代间差分杂交算子可以表示为:
其中[·]表示取整函数,α、β、λ为小于1的正常数。xnbest、xn-1best分别是第n代和n-1代中适应度最好的个体。又按下式计算个体x:
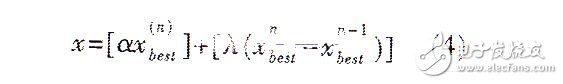
即在新种群产生后,又进行如下操作:从新种群中随机选择一个个体,如果该个体适应度比x好,则保持不变,否则用x代替该个体。(4)式中α、λ的取值可以与(3)式相同也可以不同,本文中取值相同。
3.3 式间差分遗传算法的实现
设种群的规模为N,则代间差分遗传算法的基本结构为:
{
分配三代进化种群的内存匹配,其内存指针分别用pt-1,p+1表示;
t=1;随机初始化种群pt-1,pt,pt+1;
计算pt-1,pt中个体的适应值;]
while(不满足终止条件)do
{
根据个体的适应值及选择策略,计算丙代种群pt-1,pt内个体的选择概率pi;
复制pt中适应值最好的个体到pt+1中;
while(pt+1中的个体全部被更新)do
{
从pt-1,pt中随机选择一个个体,按杂交概率用代间差分杂交算子产生新个体;
按变异概率用变异算子作用新个体;
}
计算pt+1中个体的适应值;
按(3)式计算xi并计算xi的适应值,从Pi+1中随机选择x(t+1)l;
如果xi的适应值比x(t+1)l好,则把xi复制到x(t+1)l在Pt+1中的位置;否则保持不变;
pTmp=pt-1;
pt-1=pt;
pt=pTmp;
t=t+1;
}
}

4 实验结果
为了验证代间差分遗传算法在分形编码中的有效性,利用常规遗传算法和代间差分遗传算法同时对Janquin编码方法进行优化,并比较优化结果。
需要特别指出的是,本文仅仅对anquin编码方法的优化进行了说明。实际上,代间差分遗传算法同样适用于其他改进的分形编码算法,例如四叉树搜索法等。
本文中两种算法采用的参数如下:种群数目为50,杂交概率为0.8,遗传概率为0.1,变异概率为0.1。
代间差分杂交算子的参数为:
用于其他改进的分形编码算法,例如四叉树搜索法等。
本文中两种算法采用的参数如下:种群数目为50,杂交概率为0.8,遗传概率为0.1,变异概率为0.1。
代间差分杂交算子的参数为:
α=1, β=0.2, λ=0.8。
以256×256的灰度Lena图像为例进行实验,值域块为8×8,定义域块为16×16。分别利用遗传算法和代间差分遗传算法对编码过程进行优化,然后利用相同的解码算法迭法10次进行解码,图2中给出了部分解码的结果。
其中(a)是Lena原图,(b)是直接利用Janquin编码方法得到结果。
在进行实验时,观察在相同的进化代数的条件下,解码图像的PSNR的变化情况。由于 遗传算法是一种随机优化算法,所以在同一个进化代数利用两种优化算法分别进行10计算,并计算解码图像的平均PSNR,如表1所示。其中最后一栏表示利用anquin方法解码图像的PSNR。

表1 实验结果
46121620J
GA2223.525.426.126.428.2
IDGA22.42426.52727.8
对表1进行分析可以知道,由于代间差分遗传算法充分利用了值域块相似度的分布特点,在相同的进化代数下,代间差分遗传算法得到的PSNR比常规遗传算法的PSNR大,说明对分形编码进行优化计算时,前者比后者具有更高的收敛速度。
-
基于改进遗传算法的图像分割方法2009-09-19 3363
-
基于遗传算法的片上网络虚通道分配算法2010-04-22 2616
-
基于遗传算法的异步电机2019-12-10 2823
-
遗传算法的优化 精选资料分享2021-07-12 1884
-
什么是遗传算法?2021-11-22 1907
-
遗传算法的特点和应用概述2021-12-31 1661
-
遗传算法在管网优化设计中的应用2009-01-09 622
-
遗传算法群体规模的研究2009-04-03 559
-
基于单亲遗传算法和导向算子的图像分形编码2009-04-14 552
-
基于浮点编码遗传算法的H二控制器设计2010-01-12 576
-
基于混沌遗传算法的组播路由优化研究2011-04-02 608
-
基于遗传算法的最大类间方差法的改进2013-01-31 707
-
基于遗传算法的风力机可靠性优化分配方法研究2017-01-02 880
-
遗传算法的解析与基于遗传算法的机器学习的介绍2017-11-13 863
-
遗传算法的基本原理 基于遗传算法的图像分割2023-07-18 773
全部0条评论

快来发表一下你的评论吧 !
