

巧用模型编译器和机器人操作系统在物联网上面做开发
电子说
描述
通过深度学习技术,物联网(IoT)设备能够得以解析非结构化的多媒体数据,智能地响应用户和环境事件,但是却伴随着苛刻的性能和功耗要求。本文作者探讨了两种方式以便将深度学习和低功耗的物联网设备成功整合。
近年来,越来越多的物联网产品出现在市场上,它们采集周围的环境数据,并使用传统的机器学习技术理解这些数据。一个例子是Google的Nest恒温器,采用结构化的方式记录温度数据,并通过算法来掌握用户的温度偏好和时间表。然而,其对于非结构化的多媒体数据,例如音频信号和视觉图像则显得无能为力。
新兴的物联网设备采用了更加复杂的深度学习技术,通过神经网络来探索其所处环境。例如,Amazon Echo可以理解人的语音指令,通过语音识别,将音频信号转换成单词串,然后使用这些单词来搜索相关信息。最近,微软的Windows物联网团队发布了一个基于面部识别的安全系统,利用到了深度学习技术,当识别到用户面部时能够自动解开门锁。
物联网设备上的深度学习应用通常具有苛刻的实时性要求。例如,基于物体识别的安全摄像机为了能及时响应房屋内出现的陌生人,通常需要小于500毫秒的检测延迟来捕获和处理目标事件。消费级的物联网设备通常采用云服务来提供某种智能,然而其所依赖的优质互联网连接,仅仅在部分范围内可用,并且往往需要较高的成本,这对设备能否满足实时性要求提出了挑战。与之相比,直接在物联网设备上实现深度学习或许是一个更好的选择,这样就可以免受连接质量的影响。
然而,直接在嵌入式设备上实现深度学习是困难的。事实上,低功耗是移动物联网设备的主要特征,而这通常意味着计算能力受限,内存容量较小。在软件方面,为了减少内存占用,应用程序通常直接运行在裸机上,或者在包含极少量第三方库的轻量级操作系统上。而与之相反,深度学习意味着高性能计算,并伴随着高功耗。此外,现有的深度学习库通常需要调用许多第三方库,而这些库很难迁移到物联网设备。
在深度学习任务中,最广泛使用的神经网络是卷积神经网络(CNNs),它能够将非结构化的图像数据转换成结构化的对象标签数据。一般来说,CNNs的工作流程如下:首先,卷积层扫描输入图像以生成特征向量;第二步,激活层确定在图像推理过程中哪些特征向量应该被激活使用;第三步,使用池化层降低特征向量的大小;最后,使用全连接层将池化层的所有输出和输出层相连。
在本文中,我们将讨论如何使用CNN推理机在物联网设备上实现深度学习。
将服务迁移到云端
对于低功耗的物联网设备,问题在于是否存在一个可靠的解决方案,能够将深度学习部署在云端,同时满足功耗和性能的要求。为了回答这个问题,我们在一块Nvidia Jetson TX1设备上实现了基于CNN的物体推理,并将其性能、功耗与将这些服务迁移到云端后的情况进行对比。
为了确定将服务迁移到云端后,是否可以降低功耗并满足对物体识别任务的实时性要求,我们将图像发送到云端,然后等待云端将结果返回。研究表明,对于物体识别任务,本地执行的功耗为7 W,而迁移到云端后功耗降低为2W。这说明将服务迁移到云端确实是降低功耗的有效途径。
然而,迁移到云端会导致至少2秒的延迟,甚至可能高达5秒,这不能满足我们500ms的实时性要求。此外,延迟的剧烈抖动使得服务非常不可靠(作为对比,我们在美国和中国分别运行这些实验进行观察)。通过这些实验我们得出结论,在当前的网络环境下,将实时性深度学习任务迁移到云端是一个尚未可行的解决方案。
移植深度学习平台到嵌入式设备
相比迁移到云端的不切实际,一个选择是将现有的深度学习平台移植到物联网设备。为此,我们选择移植由Google开发并开源的深度学习平台TesnsorFlow来建立具有物体推理能力的物联网设备Zuluko——PerceptIn的裸机ARM片上系统。Zuluko由四个运行在1 GHz的ARM v7内核和512 MB RAM组成,峰值功耗约为3W。根据我们的研究,在基于ARM-Linux的片上系统上,TensorFlow能够提供最佳性能,这也是我们选择它的原因。
我们预计能够在几天内完成移植工作,然而,移植TensorFlow并不容易,它依赖于许多第三方库(见图1)。为了减少资源消耗,大多数物联网设备都运行在裸机上,因此移植所有依赖项可以说是一项艰巨的任务。我们花了一个星期的精力才使得TensorFlow得以在Zuluko上运行。此次经验也使我们重新思考,相比移植一个现有的平台,是否从头开始构建一个新平台更值得。然而缺乏诸如卷积算子等基本的构建块,从头开始构建并不容易。此外,从头开始构建的推理机也很难比一个久经测试的深度学习框架表现更优。
图1 TensorFlow对第三方库的依赖。因为依赖于许多第三方库,将现有的深度学习平台(如TensorFlow)移植到物联网设备并不是一个简单的过程。
从头开始构建推理机
ARM最近宣布推出其计算库(ACL,developer.arm.com/technologies/compute-library),为ARM Cortex-A系列CPU处理器和ARM Mali系列GPU实现了软件功能的综合集成。具体而言,ACL为CNNs提供了基本的构建模块,包括激活、卷积、全连接和局部连接、规范化、池化和softmax功能。这些功能正是我们建立推理机所需要的。
我们使用ACL构建块构建了一个具有SqueezeNet架构的CNN推理机,其内存占用空间小,适合于嵌入式设备。SqueezeNet在保持相似的推理精度的同时,使用1×1卷积核来减少3×3卷积层的输入大小。然后,我们将SqueezeNet推理机的性能与Zuluko上的TensorFlow进行比较。为了确保比较的公平性,我们启用了TensorFlow中的ARM NEON向量计算优化,并在创建SqueezeNet引擎时使用了支持NEON的构建块。确保两个引擎都使用了NEON向量计算,这样任何性能差异将仅由平台本身引起。如图2所示,平均来言,TensorFlow处理227×227像素的RGB图像需要420 ms,而SqueezeNet将处理相同图像的时间缩短到320ms,加速了25%。
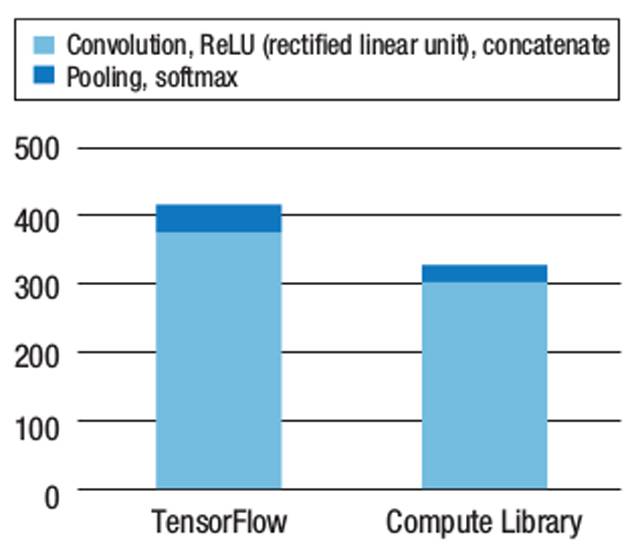
图2 在TensorFlow上运行的SqueezeNet推理机与使用ARM Compute Library(ACL)构建的SqueezeNet推理机的性能。从头开始构建简单的推理引擎不仅需要较少的开发时间,而且相比现有的深度学习引擎,如TensorFlow,表现更加优秀。
为了更好地了解性能增益的来源,我们将执行过程分为两部分:第一部分包括卷积、ReLU(线性整流函数)激活和级联;第二部分包括池化和softmax功能。图2所示的分析表明,SqueezeNet在第一部分中的性能相比TensorFlow提高23%,在第二部分中提高110%。考虑资源利用率,当在TensorFlow上运行时,平均CPU使用率为75%,平均内存使用量为9MB;当在SqueezeNet上运行时,平均CPU使用率为90%,平均内存使用量约为10MB。两个原因带来了性能的提升:首先,SqueezeNet提供了更好的NEON优化,所有ACL运算符都是使用NEON提供的运算符直接开发的,而TensorFlow则依靠ARM编译器来提供NEON优化。其次,TensorFlow平台本身可能会引起一些额外的性能开销。
接下来,我们希望能够从TensorFlow中榨出更多的性能,看看它是否能胜过我们构建的SqueezeNet推理机。一种常用的技术是使用矢量量化,使用8位权重以精度来换取性能。8位权重的使用,使得我们可以通过向量操作,只需一个指令便可计算多个数据单元。然而,这种优化是有代价的:它引入了重新量化和去量化操作。我们在TensorFlow中实现了这个优化,图3比较了有无优化的性能。使用矢量量化将卷积性能提高了25%,但由于去量化和重新量化操作,也显著地增加了开销。总体而言,它将整个推理过程减慢了超过100毫秒。
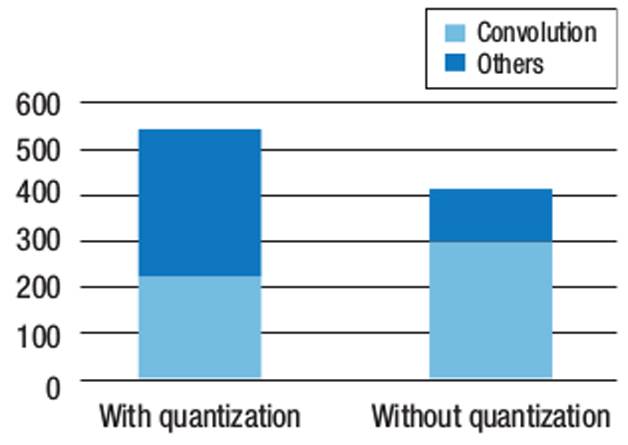
图3 有无矢量量化的TensorFlow性能。手动优化现有的深度学习平台(如TensorFlow)很困难,可能不会带来显著的性能提升。
网络连接是易失的,因此我们想要确保能够在本地设备上实现某种形式的智能,使其能够在ISP或网络故障的情况下继续运行。然而要想实现它,需要较高的计算性能和功耗。
尽管将服务迁移到云端能够减少物联网设备的功耗,但很难满足实时性要求。而且现有的深度学习平台是为了通用性任务而设计开发的,同时适用于训练和推理任务,这意味着这些引擎未针对嵌入式推理任务进行优化。并且它们还依赖于裸机嵌入式系统上不易获得的其他第三方库,这些都使其非常难以移植。
通过使用ACL构建块来建立嵌入式CNN推理引擎,我们可以充分利用SoC的异构计算资源获得高性能。因此,问题变为是选择移植现有引擎,还是从零开始构建它们更容易。我们的经验表明,如果模型很简单,相比之下从头开始构建它们容易得多。而随着模型越来越复杂,在某些情况下,可能我们迁移现有引擎相对更加高效。然而,考虑到嵌入式设备实际运行的任务,不大可能会需要用到复杂的模型。因此我们得出结论,从头开始构建一个嵌入式推理引擎或许是向物联网设备提供深度学习能力的可行方法。
更进一步
相比从头开始手动构建模型,我们需要一种更方便的方式来在物联网设备上提供深度学习能力。一个解决方案是实现一个深度学习的模型编译器,可以将给定的模型经过优化,编译为目标平台上的可执行代码。如图4中间的图所示,这种编译器的前端可以从主要的深度学习平台(包括MXNet、Caffe、TensorFlow等)解析模型。然后,优化器可以执行额外的优化,包括模型修剪,量化和异构执行。优化后,由代码生成器生成目标平台上可执行代码,可以是ACL(用于ARM设备),TensorRT(用于Nvidia GPU)或其他ASIC设备。
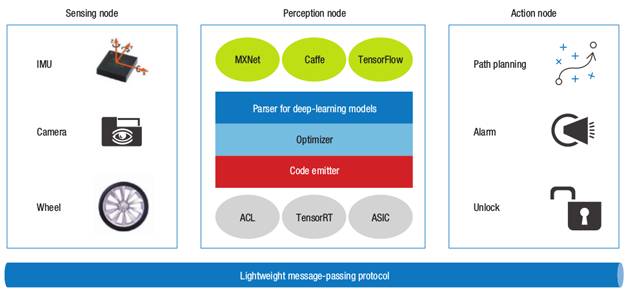
图4 物联网设备服务架构。我们需要一个新的系统架构来实现物联网设备上的深度学习:首先,我们需要直接编译和优化深度学习模型生成目标设备上的可执行代码; 其次,我们需要一个非常轻量级的操作系统,以实现多任务及其间的高效通信。IMU:惯性测量单元。
NNVM项目(github.com/dmlc/nnvm)是迈向这一目标的第一步。我们已经成功地扩展了NNVM来生成代码,以便我们可以使用ACL来加速ARM设备上的深度学习操作。这种方法的另一个好处是,即使模型变得更加复杂,我们仍然可以轻松地在物联网设备上实现它们。
当前的物联网设备通常由于计算资源的限制而执行单个任务。然而,我们预计很快将有能够执行多个任务的低功耗物联网设备(例如,我们的Zuluko设备就包含了四个内核)。为了使用这些设备,我们需要一个非常轻量级的消息传递协议来连接不同的服务。
如图4所示,物联网设备的基本服务包括传感,感知和决策。传感节点涉及处理来自例如摄像机,惯性测量单元和车轮测距的原始传感器数据。感知节点使用已处理的传感器数据,并对所捕获的信息进行解释,例如对象标签和设备位置。动作节点包含一组规则,用于确定在检测到特定事件时如何响应,例如在检测到所有者的脸部时解锁门,或者当检测到障碍物时调整机器人的运动路径。Nanomsg(nanomsg.org)是一个非常轻量级的消息传递框架,非常适合类似的任务。另一个选择是机器人操作系统,尽管我们发现对于物联网设备来说,其在内存占用和计算资源需求方面显得太重了。
为了有效地将深度学习与物联网设备集成,我们开发了自己的操作系统,包括用于消费级传感器输入的传感器接口,基于NNVM的编译器,将现有的深度学习模型编译并优化为可执行代码,以及基于Nanomsg的消息传输框架来连接所有的节点。
-
【Aworks申请】物联网操作系统2015-07-09 3703
-
【OK210申请】基于物联网的六足爬行机器人2015-08-07 2313
-
【MiCOKit申请】基于物联网的六足爬行机器人2015-08-09 2653
-
【TL6748 DSP申请】基于物联网的六足爬行机器人2015-09-09 2060
-
【Tisan物联网申请】WiFi 机器人2015-10-15 3107
-
【Tisan物联网申请】全地形消防侦查机器人2015-10-21 3414
-
机器人操作系统浅析2016-09-28 2886
-
关于机器人主控操作系统2017-12-25 5219
-
入门必备的机器人操作系统2019-06-11 2089
-
主流物联网操作系统的比较2019-09-17 3093
-
【小熊派IOT开发板试用连载】多功能控制的小型运动机器人2020-03-31 1407
-
MiCO物联网操作系统2021-08-20 1896
-
工业物联网·工业机器人远程监控系统方案2022-02-23 8510
-
高通推出开创性物联网和机器人产品,扩展智能网联边缘生态系统2023-03-14 1884
-
Triton编译器在机器学习中的应用2024-12-24 1768
全部0条评论

快来发表一下你的评论吧 !
