

理解Java中字符流与字节流的区别
嵌入式操作系统
描述
Java
JDK(Java Development Kit)称为Java开发包或Java开发工具,是一个编写Java的Applet小程序和应用程序的程序开发环境。JDK是整个Java的核心,包括了Java运行环境(Java Runtime Envirnment),一些Java工具和Java的核心类库(Java API)。不论什么Java应用服务器实质都是内置了某个版本的JDK。主流的JDK是Sun公司发布的JDK,除了Sun之外,还有很多公司和组织都开发了自己的JDK,例如,IBM公司开发的JDK,BEA公司的Jrocket,还有GNU组织开发的JDK。
另外,可以把Java API类库中的Java SE API子集和Java虚拟机这两部分统称为JRE(JAVA Runtime Environment),JRE是支持Java程序运行的标准环境。
JRE是个运行环境,JDK是个开发环境。因此写Java程序的时候需要JDK,而运行Java程序的时候就需要JRE。而JDK里面已经包含了JRE,因此只要安装了JDK,就可以编辑Java程序,也可以正常运行Java程序。但由于JDK包含了许多与运行无关的内容,占用的空间较大,因此运行普通的Java程序无须安装JDK,而只需要安装JRE即可[15] 。
编程工具
Eclipse:一个开放源代码的、基于Java的可扩展开发平台。
NetBeans:开放源码的Java集成开发环境,适用于各种客户机和Web应用。
IntelliJ IDEA:在代码自动提示、代码分析等方面的具有很好的功能。
MyEclipse:由Genuitec公司开发的一款商业化软件,是应用比较广泛的Java应用程序集成开发环境。
EditPlus:如果正确配置Java的编译器“Javac”以及解释器“Java”后,可直接使用EditPlus编译执行Java程序
理解Java中字符流与字节流的区别
1. 什么是流
Java中的流是对字节序列的抽象,我们可以想象有一个水管,只不过现在流动在水管中的不再是水,而是字节序列。和水流一样,Java中的流也具有一个“流动的方向”,通常可以从中读入一个字节序列的对象被称为输入流;能够向其写入一个字节序列的对象被称为输出流。
2. 字节流
Java中的字节流处理的最基本单位为单个字节,它通常用来处理二进制数据。Java中最基本的两个字节流类是InputStream和OutputStream,它们分别代表了组基本的输入字节流和输出字节流。InputStream类与OutputStream类均为抽象类,我们在实际使用中通常使用Java类库中提供的它们的一系列子类。下面我们以InputStream类为例,来介绍下Java中的字节流。
InputStream类中定义了一个基本的用于从字节流中读取字节的方法read,这个方法的定义如下:
public abstract int read() throws IOException;
这是一个抽象方法,也就是说任何派生自InputStream的输入字节流类都需要实现这一方法,这一方法的功能是从字节流中读取一个字节,若到了末尾则返回-1,否则返回读入的字节。关于这个方法我们需要注意的是,它会一直阻塞知道返回一个读取到的字节或是-1。另外,字节流在默认情况下是不支持缓存的,这意味着每调用一次read方法都会请求操作系统来读取一个字节,这往往会伴随着一次磁盘IO,因此效率会比较低。有的小伙伴可能认为InputStream类中read的以字节数组为参数的重载方法,能够一次读入多个字节而不用频繁的进行磁盘IO。那么究竟是不是这样呢?我们来看一下这个方法的源码:
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
它调用了另一个版本的read重载方法,那我们就接着往下追:
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off 《 0 || len 《 0 || len 》 b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i 《 len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
从以上的代码我们可以看到,实际上read(byte[])方法内部也是通过循环调用read()方法来实现“一次”读入一个字节数组的,因此本质来说这个方法也未使用内存缓冲区。要使用内存缓冲区以提高读取的效率,我们应该使用BufferedInputStream。
3. 字符流
Java中的字符流处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据。所谓Unicode码元,也就是一个Unicode代码单元,范围是0x0000~0xFFFF。在以上范围内的每个数字都与一个字符相对应,Java中的String类型默认就把字符以Unicode规则编码而后存储在内存中。然而与存储在内存中不同,存储在磁盘上的数据通常有着各种各样的编码方式。使用不同的编码方式,相同的字符会有不同的二进制表示。实际上字符流是这样工作的:
输出字符流:把要写入文件的字符序列(实际上是Unicode码元序列)转为指定编码方式下的字节序列,然后再写入到文件中;
输入字符流:把要读取的字节序列按指定编码方式解码为相应字符序列(实际上是Unicode码元序列从)从而可以存在内存中。
我们通过一个demo来加深对这一过程的理解,示例代码如下:
import java.io.FileWriter;
import java.io.IOException;
public class FileWriterDemo {
public static void main(String[] args) {
FileWriter fileWriter = null;
try {
try {
fileWriter = new FileWriter(“demo.txt”);
fileWriter.write(“demo”);
} finally {
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
以上代码中,我们使用FileWriter向demo.txt中写入了“demo”这四个字符,我们用十六进制编辑器WinHex查看下demo.txt的内容:

从上图可以看出,我们写入的“demo”被编码为了“64 65 6D 6F”,但是我们并没有在上面的代码中显式指定编码方式,实际上,在我们没有指定时使用的是操作系统的默认字符编码方式来对我们要写入的字符进行编码。
由于字符流在输出前实际上是要完成Unicode码元序列到相应编码方式的字节序列的转换,所以它会使用内存缓冲区来存放转换后得到的字节序列,等待都转换完毕再一同写入磁盘文件中。
4. 字符流与字节流的区别
经过以上的描述,我们可以知道字节流与字符流之间主要的区别体现在以下几个方面:
字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
字节流默认不使用缓冲区;字符流使用缓冲区。
字节流通常用于处理二进制数据,实际上它可以处理任意类型的数据,但它不支持直接写入或读取Unicode码元;字符流通常处理文本数据,它支持写入及读取Unicode码元。
以上是我对Java中字符流与字节流的一些认识,如有叙述不清晰或是不准确的地方希望大家可以指正,谢谢大家:)
5.字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢?实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件,如图12-6所示。
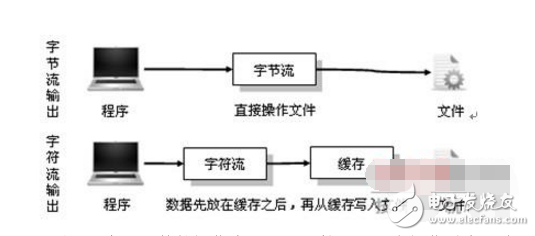
下面以两个写文件的操作为主进行比较,但是在操作时字节流和字符流的操作完成之后都不关闭输出流。
范例:使用字节流不关闭执行
Java代码 package org.lxh.demo12.byteiodemo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class OutputStreamDemo05 {
public static void main(String[] args) throws Exception { // 异常抛出, 不处理
// 第1步:使用File类找到一个文件
File f = new File(“d:” + File.separator + “test.txt”); // 声明File 对象
// 第2步:通过子类实例化父类对象
OutputStream out = null;
// 准备好一个输出的对象
out = new FileOutputStream(f);
// 通过对象多态性进行实例化
// 第3步:进行写操作
String str = “Hello World!!!”;
// 准备一个字符串
byte b[] = str.getBytes();
// 字符串转byte数组
out.write(b);
// 将内容输出
// 第4步:关闭输出流
// out.close();
// 此时没有关闭
}
}
程序运行结果:

此时没有关闭字节流操作,但是文件中也依然存在了输出的内容,证明字节流是直接操作文件本身的。而下面继续使用字符流完成,再观察效果。
范例:使用字符流不关闭执行
Java代码 package org.lxh.demo12.chariodemo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class WriterDemo03 {
public static void main(String[] args) throws Exception { // 异常抛出, 不处理
// 第1步:使用File类找到一个文件
File f = new File(“d:” + File.separator + “test.txt”);// 声明File 对象
// 第2步:通过子类实例化父类对象
Writer out = null;
// 准备好一个输出的对象
out = new FileWriter(f);
// 通过对象多态性进行实例化
// 第3步:进行写操作
String str = “Hello World!!!”;
// 准备一个字符串
out.write(str);
// 将内容输出
// 第4步:关闭输出流
// out.close();
// 此时没有关闭
}
}
程序运行结果:

程序运行后会发现文件中没有任何内容,这是因为字符流操作时使用了缓冲区,而 在关闭字符流时会强制性地将缓冲区中的内容进行输出,但是如果程序没有关闭,则缓冲区中的内容是无法输出的,所以得出结论:字符流使用了缓冲区,而字节流没有使用缓冲区。
提问:什么叫缓冲区?
在很多地方都碰到缓冲区这个名词,那么到底什么是缓冲区?又有什么作用呢?
回答:缓冲区可以简单地理解为一段内存区域。
可以简单地把缓冲区理解为一段特殊的内存。
某些情况下,如果一个程序频繁地操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入到内存的一块区域之中,以后直接从此区域中读取数据即可,因为读取内存速度会比较快,这样可以提升程序的性能。
在字符流的操作中,所有的字符都是在内存中形成的,在输出前会将所有的内容暂时保存在内存之中,所以使用了缓冲区暂存数据。
如果想在不关闭时也可以将字符流的内容全部输出,则可以使用Writer类中的flush()方法完成。
范例:强制性清空缓冲区
Java代码 package org.lxh.demo12.chariodemo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class WriterDemo04 {
public static void main(String[] args) throws Exception { // 异常抛出不处理
// 第1步:使用File类找到一个文件
File f = new File(“d:” + File.separator + “test.txt”);// 声明File
对象
// 第2步:通过子类实例化父类对象
Writer out = null;
// 准备好一个输出的对象
out = new FileWriter(f);
// 通过对象多态性进行实例化
// 第3步:进行写操作
String str = “Hello World!!!”;
// 准备一个字符串
out.write(str);
// 将内容输出
out.flush();
// 强制性清空缓冲区中的内容
// 第4步:关闭输出流
// out.close();
// 此时没有关闭
}
}
程序运行结果:
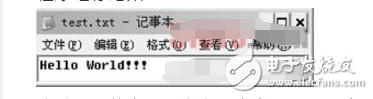
此时,文件中已经存在了内容,更进一步证明内容是保存在缓冲区的。这一点在读者日后的开发中要特别引起注意。
提问:使用字节流好还是字符流好?
学习完字节流和字符流的基本操作后,已经大概地明白了操作流程的各个区别,那么在开发中是使用字节流好还是字符流好呢?
回答:使用字节流更好。
在回答之前,先为读者讲解这样的一个概念,所有的文件在硬盘或在传输时都是以字节的方式进行的,包括图片等都是按字节的方式存储的,而字符是只有在内存中才会形成,所以在开发中,字节流使用较为广泛。
字节流与字符流主要的区别是他们的的处理方式
流分类:
1.Java的字节流
InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先。
2.Java的字符流
Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先。
InputStream,OutputStream,Reader,writer都是抽象类。所以不能直接new
字节流是最基本的,所有的InputStream和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的
但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化
这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联
在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的
在从字节流转化为字符流时,实际上就是byte[]转化为String时,
public String(byte bytes[], String charsetName)
有一个关键的参数字符集编码,通常我们都省略了,那系统就用操作系统的lang
而在字符流转化为字节流时,实际上是String转化为byte[]时,
byte[] String.getBytes(String charsetName)
也是一样的道理
至于java.io中还出现了许多其他的流,按主要是为了提高性能和使用方便,
如BufferedInputStream,PipedInputStream等
-
字节流和字符流有什么区别?看完就知道!2023-12-09 2236
-
java的字符流分析2023-10-10 972
-
Java中如何判断字符相等2023-02-24 1104
-
如何将字节流数据正确恢复为底层硬件实际发送的数据呢?2021-01-15 1389
-
Java中的输入输出流盘点2019-07-11 1011
-
基础:Java IO流学习总结2019-03-08 2343
-
java教程之流式输入输出的原理和实现的资料免费下载2018-09-28 1060
-
字符流和字节流有什么那区别2017-12-20 8908
-
Java 字节流 字符流 转换流2017-12-04 1688
-
java 字节流转字符流2017-09-27 1115
-
基于数据流的Java字节码分析2009-12-25 1090
-
Java的输入/输出课程2009-04-10 415
-
java流与文件实验2008-09-23 2045
全部0条评论

快来发表一下你的评论吧 !
