

人工智能C4.5算法的概念和优点
人工智能
描述
C4.5算法是由Quinlan提出并开发的用于产生决策树的算法。该算法是对Quinlan之前开发的ID3算法的一个扩展。C4.5算法产生的决策树可以被用作分类目的,因此该算法也可以用于统计分类。
C4.5算法与ID3算法一样使用了信息熵的概念,并和ID3一样通过学习数据来建立决策树。ID3算法使用的是信息熵的变化值,而C4.5算法使用的是信息增益率。在决策树构造过程中进行剪枝,因为某些具有很少元素的结点可能会使构造的决策树过适应(Overfitting),如果不考虑这些结点可能会更好。对非离散数据能处理,并对不完整数据进行处理。
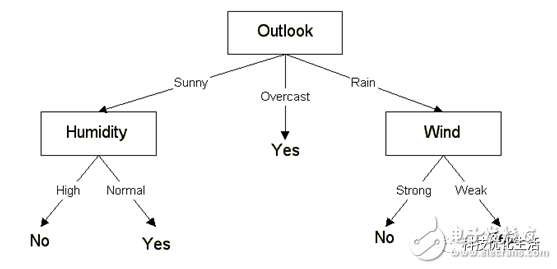
C4.5算法概念:
C4.5算法由Quinlan在ID3算法基础上提出的,用来构造决策树。C4.5算法是用于生成决策树的一种经典算法。它是一系列用在机器学习和数据挖掘分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。
C4.5算法改进:
C4.5算法是ID3算法的一种延伸和优化,C4.5算法对ID3算法主要做的改进是:1)通过信息增益率选择分裂属性,克服了ID3算法中分裂属性的不足;2)通过将连续型的属性进行离散化处理,克服ID3算法不能处理连续型数据缺陷;3)构造决策树之后进行剪枝操作,解决ID3算法中可能会出现的过拟合问题;4)能够处理具有缺失属性值的训练数据。
C4.5算法本质:
ID3采用的信息增益度量。它优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益。信息增益反映的给定一个条件以后不确定性减少的程度,分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大。避免这个不足的一个度量就是不用信息增益来选择Feature,而是用信息增益比率(gain ratio)。
增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature,分裂信息用来衡量Feature分裂数据的广度和均匀性(有点像煎饼中均匀摊鸡蛋的感觉^_^)。
分裂信息公式:
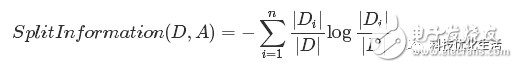
信息增益比率公式:
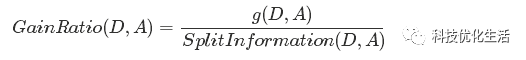
但是当某个Di的大小跟D的大小接近时,则
SplitInformation(D,A)→0
GainRatio(D,A)→∞
为了避免这样的属性,采用启发式思路,只对那些信息增益比较高的属性才用信息增益比率。
C4.5算法流程:
C4.5算法并不是一个算法,而是一组算法。C4.5算法包括非剪枝C4.5和C4.5规则。

C4.5能处理连续属性值,具体步骤为:
1)把需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序;
2)假设该属性对应的不同的属性值一共有N个,那么总共有N?1可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点,根据这个分割点把原来连续的属性分成离散属性(比如BooL属性);
3)用信息增益比率选择最佳划分。
另外,C4.5算法还能对缺失值进行处理:
1)赋上该属性最常见的值;
2)根据节点的样例上该属性值出现的情况赋一个概率;
3)丢弃有缺失值的样本。
C4.5算法采用PEP(Pessimistic Error Pruning)剪枝法。PEP剪枝法由Quinlan提出,是一种自上而下的剪枝法,根据剪枝前后的错误率来判定是否进行子树的修剪,因此不需要单独的剪枝数据集。
C4.5优点:
1)通过信息增益率选择分裂属性,克服了ID3算法中通过信息增益倾向于选择拥有多个属性值的属性作为分裂属性的不足;
2)通过将连续型的属性进行离散化处理,克服ID3算法不能处理连续型数据缺陷,C4.5算法能够处理离散型和连续型的2种属性类型;
3)构造决策树之后进行剪枝(PEP)操作(ID3算法中没有),解决ID3算法中可能会出现的过拟合问题;
4)能够处理具有缺失属性值的训练数据;
5)产生的分类规则易于理解且准确率较高。
C4.5缺点:
1) 在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效;
2) 针对含有连续属性值的训练样本时,算法计算效率较低;
3) 算法在选择分裂属性时没有考虑到条件属性间的相关性,只计算数据集中每一个条件属性与决策属性之间的期望信息,有可能影响到属性选择的正确性;
4) 算法只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
C4.5应用场景:
C4.5算法具有条理清晰,能处理连续型属性,防止过拟合,准确率较高和适用范围广等优点,是一个很有实用价值的决策树算法,可以用来分类,也可以用来回归。C4.5算法在机器学习、知识发现、金融分析、遥感影像分类、生产制造、分子生物学和数据挖掘等领域得到广泛应用。
结语:
C4.5算法是由Quinlan在ID3算法基础上提出的。C4.5算法是ID3算法的一种延伸,对ID3算法做了一些改进和优化。它是一系列用在机器学习和数据挖掘的分类问题中的算法。C4.5算法不是一个算法,而是一组算法。C4.5算法目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。C4.5算法在世界上广为流传,得到极大的关注。C4.5算法在机器学习、知识发现、金融分析、遥感影像分类、生产制造、分子生物学和数据挖掘等领域得到广泛应用。
-
人工智能是什么?2015-09-16 6263
-
人工智能的前世今生 引爆人工智能大时代2016-03-03 5790
-
分享:人工智能算法将带领机器人走向何方?2017-08-16 5823
-
人工智能就业前景2018-03-29 8272
-
人工智能和机器学习的前世今生2018-08-27 3495
-
人工智能技术及算法设计指南2019-02-12 5016
-
智能控制、人工智能、智能算法的发展前景怎么样2019-05-10 5404
-
人工智能:超越炒作2019-05-29 4848
-
人工智能芯片是人工智能发展的2021-07-27 6399
-
智能天线的基本概念2021-08-05 2017
-
人工智能基本概念机器学习算法2021-09-06 2669
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2194
-
基于改进C4.5 算法的税收信用分类应用研究2009-12-29 648
-
AI人工智能的几种常用算法概念2018-02-02 66437
-
人工智能之机器学习C4.5算法解析2018-09-05 1612
全部0条评论

快来发表一下你的评论吧 !
