

ж•°жҚ®д»“еә“е’ҢOLAPжҠҖжңҜжҰӮиҝ°
з”өеӯҗеёёиҜҶ
жҸҸиҝ°
гҖҖгҖҖиҒ”жңәеҲҶжһҗеӨ„зҗҶ
гҖҖгҖҖиҒ”жңәеҲҶжһҗеӨ„зҗҶOLAPжҳҜдёҖз§ҚиҪҜ件жҠҖжңҜпјҢе®ғдҪҝеҲҶжһҗдәәе‘ҳиғҪеӨҹиҝ…йҖҹгҖҒдёҖиҮҙгҖҒдәӨдә’ең°д»Һеҗ„дёӘж–№йқўи§ӮеҜҹдҝЎжҒҜпјҢд»ҘиҫҫеҲ°ж·ұе…ҘзҗҶи§Јж•°жҚ®зҡ„зӣ®зҡ„гҖӮе®ғе…·жңүFASMIпјҲFast Analysis of Shared Multidimensional InformationпјүпјҢеҚіе…ұдә«еӨҡз»ҙдҝЎжҒҜзҡ„еҝ«йҖҹеҲҶжһҗзҡ„зү№еҫҒгҖӮе…¶дёӯFжҳҜеҝ«йҖҹжҖ§пјҲFastпјүпјҢжҢҮзі»з»ҹиғҪеңЁж•°з§’еҶ…еҜ№з”ЁжҲ·зҡ„еӨҡж•°еҲҶжһҗиҰҒжұӮеҒҡеҮәеҸҚеә”пјӣAжҳҜеҸҜеҲҶжһҗжҖ§пјҲAnalysisпјүпјҢжҢҮз”ЁжҲ·ж— йңҖзј–зЁӢе°ұеҸҜд»Ҙе®ҡд№үж–°зҡ„дё“й—Ёи®Ўз®—пјҢе°Ҷе…¶дҪңдёәеҲҶжһҗзҡ„дёҖйғЁ еҲҶпјҢ并д»Ҙз”ЁжҲ·жүҖеёҢжңӣзҡ„ж–№ејҸз»ҷеҮәжҠҘе‘ҠпјӣMжҳҜеӨҡз»ҙжҖ§пјҲMulti—dimensionalпјүпјҢжҢҮжҸҗдҫӣеҜ№ж•°жҚ®еҲҶжһҗзҡ„еӨҡз»ҙи§Ҷеӣҫе’ҢеҲҶжһҗпјӣIжҳҜдҝЎжҒҜжҖ§пјҲInformationпјүпјҢжҢҮиғҪеҸҠж—¶иҺ·еҫ—дҝЎжҒҜпјҢ并且管зҗҶеӨ§е®№йҮҸдҝЎжҒҜгҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“е’ҢиҒ”жңәеҲҶжһҗеӨ„зҗҶпјҲOLAPпјүжҳҜеҶізӯ–ж”ҜжҢҒеҹәжң¬иҰҒзҙ пјҢе·Із»Ҹж—ҘзӣҠжҲҗдёәж•°жҚ®еә“иЎҢдёҡзҡ„йҮҚзӮ№гҖӮи®ёеӨҡе•Ҷдёҡдә§е“Ғе’ҢжңҚеҠЎзҺ°е·ІжҺЁеҮәпјҢ并且жүҖжңүдё»иҰҒзҡ„ж•°жҚ®еә“з®ЎзҗҶзі»з»ҹдҫӣеә”е•ҶзҺ°еңЁе·Із»ҸеңЁиҝҷдәӣйўҶеҹҹжҸҗдҫӣдә§е“ҒгҖӮеҶізӯ–ж”ҜжҢҒпјҢзӣёжҜ”дәҺдј з»ҹзҡ„иҒ”жңәдәӢеҠЎеӨ„зҗҶеә”з”ЁзЁӢеәҸпјҢдјҡжңүдәӣдёҚеҗҢзҡ„иҰҒжұӮж•°жҚ®еә“жҠҖжңҜгҖӮжң¬ж–ҮжҸҗдҫӣзҡ„ж•°жҚ®жҰӮиҝ°ж•°жҚ®д»“еә“е’ҢOLAPжҠҖжңҜпјҢзқҖзңјдәҺ他们зҡ„ж–°зҡ„иҰҒжұӮгҖӮжҲ‘们жҸҸиҝ°еҗҺз«Ҝе·Ҙе…·жқҘжҸҗеҸ–пјҢжё…жҙҒе’Ңж•°жҚ®еҠ иҪҪеҲ°ж•°жҚ®д»“еә“;е…ёеһӢOLAPзҡ„еӨҡз»ҙж•°жҚ®жЁЎеһӢ;еүҚз«Ҝе®ўжҲ·з«Ҝе·Ҙе…·з”ЁдәҺжҹҘиҜўе’Ңж•°жҚ®еҲҶжһҗ;жңҚеҠЎеҷЁжү©еұ•жқҘй«ҳж•Ҳзҡ„жҹҘиҜўеӨ„зҗҶ;з”ЁжқҘз®ЎзҗҶе…ғж•°жҚ®е’Ңд»“еә“е·Ҙе…·гҖӮжӯӨеӨ–пјҢеӢҳжөӢжҠҖжңҜзҺ°зҠ¶пјҢжң¬ж–ҮиҝҳжҢҮеҮәдәҶдёҖдәӣжңүеүҚжҷҜзҡ„з ”з©¶й—®йўҳпјҢе…¶дёӯдёҖдәӣж¶үеҸҠж•°жҚ®еә“з ”з©¶з•ҢеҗҲдҪңеӨҡе№ҙзҡ„з ”з©¶зҡ„й—®йўҳпјҢдҪҶе…¶д»–дёҖдәӣй—®йўҳеҸӘжҳҜеҲҡеҲҡејҖе§Ӣиў«и§ЈеҶігҖӮжң¬жҰӮиҝ°жҳҜеҹәдәҺдёҖдёӘж•ҷзЁӢпјҢжңүдҪңиҖ…们еңЁдјҡи®®VLDB 1996е№ҙжҸҗеҮәгҖӮ
гҖҖгҖҖ1. д»Ӣз»Қ
гҖҖгҖҖж•°жҚ®д»“еә“жҳҜеҶізӯ–ж”ҜжҢҒжҠҖжңҜзҡ„йӣҶеҗҲпјҢж—ЁеңЁдҪҝзҹҘиҜҶе·ҘдҪңиҖ…пјҲжҖ»иЈҒпјҢз»ҸзҗҶпјҢеҲҶжһҗеёҲпјүеҒҡеҮәжӣҙеҝ«жӣҙеҘҪзҡ„еҶізӯ–гҖӮиҝҮеҺ»дёүе№ҙе·Із»ҸзңӢеҲ°зҡ„зҲҶзӮёжҖ§зҡ„еўһй•ҝпјҢж— и®әжҳҜеңЁжүҖжҸҗдҫӣзҡ„дә§е“Ғе’ҢжңҚеҠЎзҡ„ж•°йҮҸпјҢиҝҳжҳҜеңЁйҮҮз”ЁиҝҷдәӣжҠҖжңҜзҡ„е·ҘдёҡйўҶеҹҹгҖӮжҢүз…§METAйӣҶеӣўиҜҙжі•пјҢж•°жҚ®д»“еә“еёӮеңәпјҢеҢ…жӢ¬зЎ¬д»¶пјҢж•°жҚ®еә“иҪҜ件е’Ңе·Ҙе…·пјҢйў„и®ЎжҳҜз”ұ1995е№ҙзҡ„20дәҝзҫҺйҮ‘еўһй•ҝеҲ°1998е№ҙеҲҶ80дәҝзҫҺйҮ‘гҖӮж•°жҚ®д»“еә“жҠҖжңҜе·Із»ҸжҲҗеҠҹйғЁзҪІеңЁи®ёеӨҡиЎҢдёҡпјҡеҲ¶йҖ дёҡпјҲи®ўеҚ•иҝҗиҫ“е’Ңе®ўжҲ·ж”ҜжҢҒпјүпјҢйӣ¶е”®пјҲз”ЁдәҺз”ЁжҲ·еҲҶжһҗе’Ңеә“еӯҳз®ЎзҗҶпјүпјҢйҮ‘иһҚжңҚеҠЎпјҲзҗҶиө”еҲҶжһҗпјҢйЈҺйҷ©еҲҶжһҗпјҢдҝЎз”ЁеҚЎеҲҶжһҗе’Ңж¬әиҜҲжЈҖжөӢпјүпјҢдәӨйҖҡпјҲиҪҰйҳҹз®ЎзҗҶпјүпјҢз”өдҝЎпјҲе‘јеҸ«еҲҶжһҗе’Ңж¬әиҜҲжЈҖжөӢпјүпјҢе…¬з”ЁдәӢдёҡпјҲз”өеҠӣдҪҝз”ЁеҲҶжһҗпјүе’ҢеҢ»з–—дҝқеҒҘпјҲеҜ№дәҺз»“жһңзҡ„еҲҶжһҗпјүгҖӮжң¬ж–Үд»Ӣз»ҚдәҶж•°жҚ®д»“еә“жҠҖжңҜзҡ„и·ҜзәҝеӣҫпјҢзқҖйҮҚдәҺжңүзү№ж®ҠйңҖжұӮзҡ„ж•°жҚ®д»“еә“ж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјҲDBMSпјүгҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“жҳҜдёҖдёӘ“йқўеҗ‘дё»йўҳзҡ„пјҢйӣҶжҲҗзҡ„пјҢйҡҸж—¶й—ҙеҸҳеҢ–зҡ„пјҢйқһжҳ“еӨұжҖ§зҡ„пјҢдё»иҰҒз”ЁдәҺз»„з»ҮеҶізӯ–зҡ„ж•°жҚ®йӣҶеҗҲгҖӮ ”йҖҡеёёжғ…еҶөдёӢпјҢж•°жҚ®д»“еә“з”ЁжқҘеҲҶеҲ«з»ҙжҠӨз»„з»Үзҡ„дёҚеҗҢдёҡеҠЎзҡ„ж•°жҚ®еә“гҖӮжңүеҫҲеӨҡеҺҹеӣ жқҘиҝҷд№ҲеҒҡгҖӮж•°жҚ®д»“еә“ж”ҜжҢҒеңЁзәҝеҲҶжһҗеӨ„зҗҶпјҲOLAP пјүпјҢе®ғзҡ„еҠҹиғҪе’ҢжҖ§иғҪиҰҒжұӮе®Ңе…ЁдёҚеҗҢдәҺз”ұдёҡеҠЎж•°жҚ®еә“жүҖж”ҜжҢҒзҡ„иҒ”жңәдәӢеҠЎеӨ„зҗҶпјҲ OLTPпјүеә”з”ЁзЁӢеәҸгҖӮ
гҖҖгҖҖOLTPеә”з”ЁзЁӢеәҸйҖҡеёёдҪҝеҫ—ж–Үд№Ұж•°жҚ®еӨ„зҗҶд»»еҠЎиҮӘеҠЁеҢ–пјҢеҰӮи®ўеҚ•еҪ•е…Ҙе’Ң银иЎҢдәӨжҳ“зӯүдёҖдәӣз»„з»Үзҡ„ж—ҘеёёиҝҗдҪңгҖӮиҝҷдәӣд»»еҠЎжҳҜз»“жһ„еҢ–е’ҢйҮҚеӨҚжҖ§пјҢд»ҘеҸҠз”ұзҹӯзҡ„пјҢеҺҹеӯҗпјҢеӯӨз«Ӣзҡ„дәӨжҳ“гҖӮиҜҘдәӨжҳ“йңҖиҰҒиҜҰз»ҶпјҢжңҖж–°зҡ„ж•°жҚ®пјҢйҖҡеёёйҖҡеёёи®ҝ问他们зҡ„дё»й”®жқҘиҜ»еҸ–жҲ–жӣҙж–°е°‘ж•°пјҲеҮ еҚҒпјүи®°еҪ•гҖӮж“ҚдҪңж•°жҚ®еә“еҫҖеҫҖжҳҜзҷҫе…ҶеҲ°еҚғе…Ҷеӯ—иҠӮгҖӮж•°жҚ®еә“зҡ„дёҖиҮҙжҖ§е’ҢеҸҜжҒўеӨҚжҖ§жҳҜиҮіе…ійҮҚиҰҒзҡ„пјҢжңҖеӨ§еҢ–дәӢеҠЎеҗһеҗҗйҮҸжҳҜе…ій”®жҖ§иғҪжҢҮж ҮгҖӮеӣ жӯӨпјҢж•°жҚ®еә“иў«и®ҫи®ЎдёәеҸҚжҳ е·ІзҹҘзҡ„еә”з”ЁпјҢзү№еҲ«жҳҜзҡ„ж“ҚдҪңиҜӯд№үпјҢд»Ҙе°ҪйҮҸеҮҸ少并еҸ‘еҶІзӘҒгҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“пјҢзӣёеҸҚзҡ„пјҢжҳҜжңүй’ҲеҜ№жҖ§зҡ„еҶізӯ–ж”ҜжҢҒгҖӮеҺҶеҸІпјҢжҖ»з»“е’Ңж•ҙеҗҲзҡ„ж•°жҚ®жҜ”иҜҰз»Ҷзҡ„пјҢдёӘдәәи®°еҪ•жӣҙйҮҚиҰҒгҖӮз”ұдәҺж•°жҚ®д»“еә“еҢ…еҗ«еҗҲ并数жҚ®пјҢжҲ–и®ёеҸҜд»Ҙд»ҺеҮ дёӘдёҡеҠЎж•°жҚ®еә“пјҢеңЁдёҖж®өж—¶й—ҙеҸҜиғҪеҫҲй•ҝзҡ„ж—¶жңҹпјҢ他们еҫҖеҫҖиҰҒжҜ”дёҡеҠЎж•°жҚ®еә“иҫғеӨ§зҡ„и®ўеҚ•;дјҒдёҡж•°жҚ®д»“еә“йў„и®Ўдёәж•°зҷҫGBеҲ°TBзә§еӨ§е°ҸгҖӮе·ҘдҪңиҙҹиҪҪеӨ§еӨҡжҳҜжҹҘиҜўеҜҶйӣҶеһӢдёҺдёҙж—¶жҖ§зҡ„пјҢеӨҚжқӮжҹҘиҜўеҸҜд»Ҙи®ҝй—®ж•°д»ҘзҷҫдёҮи®Ўзҡ„и®°еҪ•пјҢ并иҝӣиЎҢдәҶеӨ§йҮҸзҡ„жү«жҸҸпјҢиҒ”жҺҘе’ҢиҒҡеҗҲгҖӮжҹҘиҜўеҗһеҗҗйҮҸе’Ңе“Қеә”ж—¶й—ҙжҜ”дәӢеҠЎеҗһеҗҗйҮҸжӣҙйҮҚиҰҒгҖӮ
гҖҖгҖҖдҝғиҝӣеӨҚжқӮзҡ„еҲҶжһҗе’ҢеҸҜи§ҶеҢ–гҖҒж•°жҚ®д»“еә“йҖҡеёёеӨҡз»ҙе»әжЁЎгҖӮдҫӢеҰӮпјҢеңЁдёҖдёӘй”Җе”®ж•°жҚ®д»“еә“пјҢй”Җе”®пјҢй”Җе”®еҢәеҹҹгҖҒй”Җе”®дәәе‘ҳе’Ңдә§е“ҒеҸҜиғҪжҳҜдёҖдәӣж„ҹе…ҙи¶Јзҡ„з»ҙеәҰгҖӮйҖҡеёёпјҢиҝҷдәӣз»ҙеәҰжҳҜеҲҶеұӮж¬Ўзҡ„;й”Җе”®ж—¶й—ҙеҸҜиғҪжҳҜз»„з»Үдёәday-month-quarter-yearзҡ„еұӮж¬Ўз»“жһ„пјҢдә§е“ҒдҪңдёәproduct-category-industryзҡ„еұӮж¬Ўз»“жһ„гҖӮе…ёеһӢзҡ„OLAPж“ҚдҪңеҢ…жӢ¬дёҠй’»пјҲеўһеҠ иҒҡеҗҲзҡ„ж°ҙе№іпјүе’ҢдёӢй’»пјҲеҮҸе°‘иҒҡеҗҲзҡ„ж°ҙе№іжҲ–еўһеҠ з»ҶиҠӮпјүд»ҘеҸҠдёҖдёӘжҲ–еӨҡдёӘз»ҙеәҰеұӮж¬Ўз»“жһ„еҲҮеүІпјҲйҖүжӢ©е’ҢжҠ•еҪұпјүпјҢиҪҙиҪ¬пјҲи°ғж•ҙзҡ„еӨҡз»ҙи§Ҷеӣҫзҡ„ж•°жҚ®пјүгҖӮ
гҖҖгҖҖз”ұдәҺе·Іжңүзҡ„дёҡеҠЎж•°жҚ®еә“е·Із»ҸеҫҲеҘҪзҡ„ж”ҜжҢҒе·ІзҹҘзҡ„OLTPе·ҘдҪңиҙҹиҪҪпјҢжүҖд»ҘиҜ•еӣҫеҜ№дёҡеҠЎж•°жҚ®еә“жү§иЎҢеӨҚжқӮзҡ„OLAPжҹҘиҜўпјҢе°ҶеҜјиҮҙдёҚеҸҜжҺҘеҸ—зҡ„жҖ§иғҪгҖӮжӯӨеӨ–пјҢеҶізӯ–ж”ҜжҢҒйңҖжұӮзҡ„ж•°жҚ®еҸҜиғҪд»ҺдёҡеҠЎж•°жҚ®еә“дёӯдёўеӨұ;дҫӢеҰӮпјҢдәҶи§Ји¶ӢеҠҝжҲ–иҝӣиЎҢйў„жөӢжүҖйңҖиҰҒеҺҶеҸІж•°жҚ®пјҢиҖҢдёҡеҠЎж•°жҚ®еә“еҸӘеӯҳеӮЁеҪ“еүҚзҡ„ж•°жҚ®гҖӮеҶізӯ–ж”ҜжҢҒдёҖиҲ¬йңҖиҰҒд»ҺеӨҡдёӘдёҚеҗҢжқҘжәҗзҡ„ж•°жҚ®иҝӣиЎҢж•ҙеҗҲпјҡиҝҷеҸҜиғҪеҢ…жӢ¬еӨ–йғЁиө„жәҗпјҢеҰӮиӮЎзҘЁзҡ„еёӮеңәеҸҚйҰҲйңҖиҰҒйўқеӨ–зҡ„еҮ дёӘдёҡеҠЎж•°жҚ®еә“гҖӮдёҚеҗҢзҡ„жқҘжәҗеҸҜиғҪеҗ«жңүдёҚеҗҢиҙЁйҮҸзҡ„ж•°жҚ®пјҢжҲ–дҪҝз”ЁдёҚдёҖиҮҙзҡ„йҷҲиҝ°пјҢд»Јз Ғе’Ңж јејҸпјҢйңҖиҰҒеҚҸи°ғгҖӮжңҖеҗҺпјҢж”ҜжҢҒеӨҡз»ҙж•°жҚ®жЁЎеһӢе’Ңж“ҚдҪңзҡ„е…ёеһӢOLAPйңҖиҰҒзү№ж®Ҡзҡ„ж•°жҚ®з»„з»ҮпјҢи®ҝй—®ж–№ејҸе’Ңе®һзҺ°ж–№жі•пјҢдёҚжҳҜеҰӮдёҖиҲ¬зҡ„е•Ҷдёҡж•°жҚ®еә“з®ЎзҗҶзі»з»ҹз”ЁжқҘй’ҲеҜ№OLTPгҖӮз”ұдәҺиҝҷдәӣеҺҹеӣ пјҢж•°жҚ®д»“еә“зҡ„е®һзҺ°жңүеҲ«дәҺдёҡеҠЎж•°жҚ®еә“гҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“еҸҜиғҪдјҡе®һж–ҪеңЁж ҮеҮҶзҡ„жҲ–жү©еұ•зҡ„е…ізі»DBMS дёҠпјҢе°ұжҳҜжүҖи°“е…ізі»еһӢOLAPпјҲROLAP пјүжңҚеҠЎеҷЁгҖӮиҝҷдәӣжңҚеҠЎеҷЁеҒҮи®ҫж•°жҚ®еӯҳеӮЁеңЁе…ізі»ж•°жҚ®еә“пјҢ并且ж”ҜжҢҒжү©еұ•SQLе’Ңзү№ж®Ҡи®ҝй—®еҸҠе®һж–Ҫж–№жі•жқҘжңүж•Ҳе®һзҺ°еӨҡз»ҙж•°жҚ®жЁЎеһӢе’Ңж“ҚдҪңгҖӮзӣёжҜ”д№ӢдёӢпјҢеӨҡз»ҙOLAP пјҲ MOLAPпјүжңҚеҠЎеҷЁзӣҙжҺҘжҠҠеӨҡз»ҙж•°жҚ®еӯҳеӮЁеңЁзү№е®ҡзҡ„ж•°жҚ®з»“жһ„пјҲдҫӢеҰӮпјҢж•°з»„пјүпјҢ并е®һзҺ°дәҶOLAPеңЁиҝҷдәӣзү№зӮ№зҡ„ж•°жҚ®з»“жһ„зҡ„ж“ҚдҪңгҖӮ
гҖҖгҖҖиҝҷдёҚд»…д»…жҳҜе»әи®ҫе’Ңз»ҙжҠӨдёҖдёӘж•°жҚ®д»“еә“пјҢиҝҳйңҖиҰҒйҖүжӢ©дёҖдёӘOLAPжңҚеҠЎеҷЁе№¶дёәд»“еә“жҳҺзЎ®жЁЎејҸе’ҢдёҖдәӣеӨҚжқӮзҡ„жҹҘиҜўгҖӮеӯҳеңЁзқҖдёҚеҗҢз»“жһ„зҡ„жӣҝд»Је“ҒгҖӮи®ёеӨҡз»„з»ҮеёҢжңӣе®һж–Ҫз»јеҗҲжҖ§дјҒдёҡзҡ„д»“еә“пјҢ收йӣҶи·Ёи¶Ҡж•ҙдёӘз»„з»Үзҡ„жүҖжңү科зӣ®пјҲдҫӢеҰӮпјҢе®ўжҲ·пјҢдә§е“ҒдҝЎжҒҜпјҢй”Җе”®пјҢиө„дә§пјҢдәәе‘ҳпјүгҖӮ然иҖҢпјҢжһ„е»әдјҒдёҡзә§ж•°жҚ®д»“еә“жҳҜдёҖдёӘжј«й•ҝиҖҢеӨҚжқӮзҡ„иҝҮзЁӢпјҢйңҖиҰҒе№ҝжіӣзҡ„дёҡеҠЎе»әжЁЎпјҢеҸҜиғҪйңҖиҰҒеӨҡе№ҙжүҚиғҪжҲҗеҠҹгҖӮзӣёеҸҚзҡ„пјҢдёҖдәӣз»„з»Үж»Ўи¶ідәҺж•°жҚ®йӣҶеёӮпјҢе®ғжҳҜй’ҲеҜ№йҖүе®ҡзҡ„科зӣ®зҡ„еӯҗйӣҶпјҲдҫӢеҰӮпјҢиҗҘй”Җж•°жҚ®еҸҜиғҪеҢ…жӢ¬е®ўжҲ·пјҢдә§е“Ғе’Ңй”Җе”®дҝЎжҒҜпјү гҖӮиҝҷдәӣж•°жҚ®йӣҶеёӮе®һзҺ°жӣҙеҝ«зҡ„жҺЁз®—пјҢеӣ дёәе®ғ们дёҚйңҖиҰҒдјҒдёҡе№ҝжіӣзҡ„е…ұиҜҶпјҢдҪҶеҰӮжһңдёҖдёӘе®Ңж•ҙзҡ„е•ҶдёҡжЁЎејҸ并дёҚеҸ‘иҫҫзҡ„иҜқпјҢд»Һй•ҝиҝңжқҘзңӢпјҢе®ғ们еҸҜиғҪдјҡеҜјиҮҙеӨҚжқӮзҡ„йӣҶжҲҗй—®йўҳгҖӮ
гҖҖгҖҖеңЁз¬¬2иҠӮпјҢжҲ‘们жҸҸиҝ°дәҶдёҖдёӘе…ёеһӢзҡ„ж•°жҚ®д»“еә“дҪ“зі»з»“жһ„пјҢе’Ңи®ҫи®Ўе’Ңж“ҚдҪңж•°жҚ®д»“еә“зҡ„иҝҮзЁӢгҖӮеңЁ3-7иҠӮпјҢжҲ‘们еӣһйЎҫдәҶеңЁж•°жҚ®еҠ иҪҪзӣёе…іжҠҖжңҜе’ҢеҲ·ж–°ж•°жҚ®д»“еә“пјҢд»“еә“жңҚеҠЎеҷЁпјҢеүҚз«Ҝе·Ҙе…·е’Ңд»“еә“з®ЎзҗҶе·Ҙе…·гҖӮеңЁжҜҸдёҖз§Қжғ…еҶөдёӢпјҢжҲ‘们жҢҮеҮәд»Җд№ҲжҳҜдј з»ҹзҡ„ж•°жҚ®еә“жҠҖжңҜдёҚеҗҢзҡ„пјҢжҲ‘们дјҡжҸҗеҲ°жңүд»ЈиЎЁжҖ§зҡ„дә§е“ҒгҖӮеңЁжң¬ж–ҮдёӯпјҢжҲ‘们дёҚжү“з®—жҸҗдҫӣжҜҸдёӘзұ»еҲ«зҡ„жүҖжңүдә§е“Ғзҡ„з»јеҗҲжҸҸиҝ°гҖӮжҲ‘们鼓еҠұжңүе…ҙи¶Јзҡ„иҜ»иҖ…зңӢзңӢеңЁжңҖиҝ‘зҡ„е•ҶдёҡжқӮеҝ—пјҢеҰӮDatabased AdvisorпјҢ Database ProgrammingпјҢDesignпјҢ DatamationпјҢDBMS MagazineпјҢ vendors’ Web sitesжқҘиҺ·еҸ–е•Ҷдёҡдә§е“ҒпјҢзҷҪзҡ®д№Ұе’ҢжЎҲдҫӢз ”з©¶зҡ„жӣҙеӨҡз»ҶиҠӮгҖӮOLAP CouncilжҳҜеңЁж•ҙдёӘиЎҢдёҡзҡ„ж ҮеҮҶеҢ–е·ҘдҪңдёҠдёҖдёӘеҫҲеҘҪзҡ„дҝЎжҒҜжәҗгҖӮиҝҳжңү科еҫ·зӯүдәәзҡ„и®әж–Үе®ҡд№үдәҶOLAPдә§е“Ғзҡ„12жқЎи§„еҲҷгҖӮиҝҳжңүпјҢData Warehousing Information CenterжҳҜж•°жҚ®д»“еә“е’ҢOLAPиүҜеҘҪзҡ„иө„жәҗгҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“зҡ„з ”з©¶жҳҜзӣёеҪ“ж–°зҡ„пјҢ并дёҖзӣҙдё“жіЁзҡ„дё»иҰҒжҳҜжҹҘиҜўеӨ„зҗҶе’Ңи§Ҷеӣҫз»ҙжҠӨй—®йўҳгҖӮиҝҳжңүеҫҲеӨҡејҖж”ҫжҖ§зҡ„з ”з©¶й—®йўҳпјҢеңЁз¬¬8иҠӮпјҢжҲ‘们дјҡз®ҖиҰҒжҸҗеҸҠзҡ„иҝҷдәӣй—®йўҳ并еҫ—еҮәз»“и®әгҖӮ
гҖҖгҖҖ2. жһ¶жһ„дёҺз«ҜеҲ°з«ҜжөҒзЁӢ
гҖҖгҖҖеӣҫ1жҳҜдёҖдёӘе…ёеһӢзҡ„ж•°жҚ®д»“еә“жһ¶жһ„гҖӮ
гҖҖгҖҖ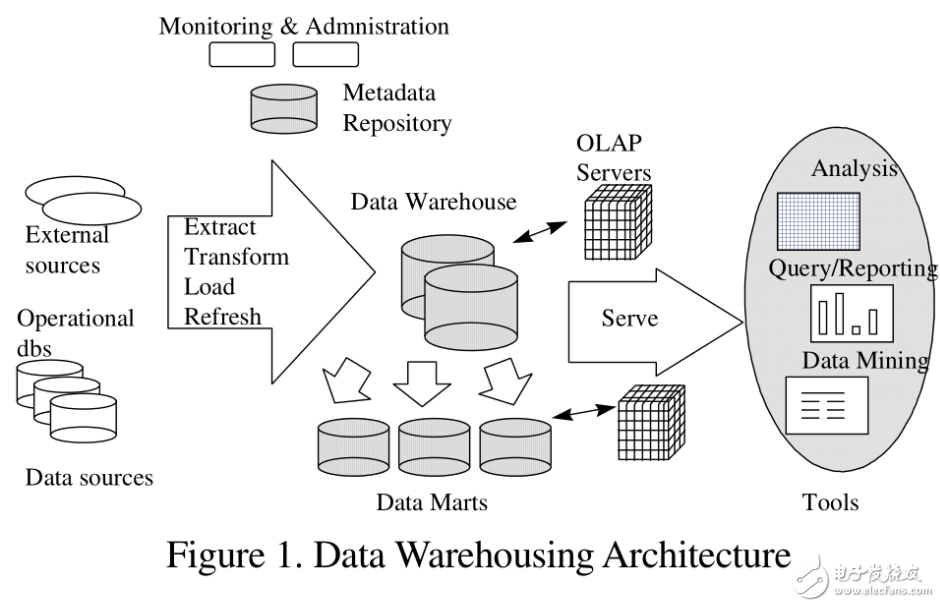
гҖҖгҖҖе®ғеҢ…жӢ¬дёҖдәӣе·Ҙе…·гҖӮиҝҷдәӣе·Ҙе…·еҸҜд»Ҙз”ЁжқҘд»ҺеӨҡз§Қж“ҚдҪңж•°жҚ®еә“е’ҢеӨ–йғЁжәҗдёӯжҸҗеҸ–ж•°жҚ®пјҢ并清жҙ—гҖҒиҪ¬жҚўе’Ңж•ҙеҗҲиҝҷдәӣж•°жҚ®пјҢ然еҗҺжҠҠж•°жҚ®еҠ иҪҪеҲ°ж•°жҚ®д»“еә“;е®ҡжңҹеҲ·ж–°д»“еә“жқҘжӣҙж–°зҡ„жәҗе’Ңжё…йҷӨд»“еә“зҡ„ж•°жҚ®пјҢжҲ–иҖ…жҳҜж…ўеҪ’жЎЈеӯҳеӮЁгҖӮйҷӨдәҶдё»д»“еә“пјҢеҸҜиғҪдјҡжңүеҘҪеҮ дёӘйғЁй—Ёж•°жҚ®йӣҶеёӮгҖӮеӯҳеӮЁеңЁж•°жҚ®д»“еә“е’Ңж•°жҚ®йӣҶеёӮзҡ„ж•°жҚ®пјҢз”ұдёҖдёӘжҲ–еӨҡдёӘд»“еә“жңҚеҠЎеҷЁз®ЎзҗҶпјҢ并е‘ҲзҺ°ж•°жҚ®зҡ„еӨҡз»ҙи§Ҷеӣҫз»ҷдёҚеҗҢзҡ„еүҚз«Ҝе·Ҙе…·пјҢеҰӮпјҡжҹҘиҜўе·Ҙе…·гҖҒжҠҘе‘ҠдҪңиҖ…гҖҒеҲҶжһҗе·Ҙе…·е’Ңж•°жҚ®жҢ–жҺҳе·Ҙе…·гҖӮжңҖеҗҺпјҢиҝҳжңүдёҖдёӘеӯҳеӮЁеә“пјҢз”ЁдәҺеӯҳеӮЁе’Ңз®ЎзҗҶе…ғж•°жҚ®пјҢ并дёәзӣ‘жөӢе’Ңз®ЎзҗҶд»“еӮЁзі»з»ҹгҖӮ
гҖҖгҖҖд»“еә“еҸҜиғҪиў«и®ҫи®ЎжҲҗеҲҶеёғејҸпјҢд»ҘжқҘеҫ—еҲ°иҙҹиҪҪеқҮиЎЎпјҢеҸҜдјёзј©жҖ§е’Ңй«ҳеҸҜз”ЁжҖ§гҖӮеңЁиҝҷж ·дёҖдёӘеҲҶеёғејҸдҪ“зі»з»“жһ„пјҢе…ғж•°жҚ®еӯҳеӮЁеә“йҖҡеёёжҳҜеңЁжҜҸдёӘиҠӮзӮ№зҡ„д»“еә“йғҪиҝӣиЎҢеӨҮд»Ҫзҡ„пјҢж•ҙдёӘд»“еә“йӣҶдёӯз®ЎзҗҶзҡ„гҖӮеҸҰдёҖдёӘдҪ“зі»з»“жһ„пјҢжҳҜд»“еә“жҲ–ж•°жҚ®йӣҶеёӮзҡ„иҒ”еҗҲпјҢжҜҸдёӘд»“еә“жҲ–иҖ…ж•°жҚ®йӣҶеёӮйғҪжңүиҮӘе·ұзҡ„иҙ®еӯҳе’ҢеҲҶзә§з®ЎзҗҶгҖӮиҜҘи®ҫи®Ўе®һзҺ°еҠӣжұӮдҪҝз”Ёж–№дҫҝпјҢжүҖд»ҘеҸҜиғҪиҠұиҙ№иҝҮдәҺжҳӮиҙөзҡ„д»Јд»·жқҘжһ„йҖ дёҖдёӘйҖ»иҫ‘йӣҶжҲҗзҡ„дјҒдёҡд»“еә“гҖӮ
гҖҖгҖҖи®ҫи®Ўе’ҢжҺЁеҮәдёҖдёӘж•°жҚ®д»“еә“жҳҜдёҖдёӘеӨҚжқӮзҡ„иҝҮзЁӢпјҢеҢ…жӢ¬д»ҘдёӢжҙ»еҠЁпјҡ
гҖҖгҖҖе®ҡд№үдҪ“зі»з»“жһ„пјҢе®№йҮҸ规еҲ’пјҢ并йҖүжӢ©еӯҳеӮЁжңҚеҠЎеҷЁгҖҒж•°жҚ®еә“е’ҢOLAPжңҚеҠЎеҷЁе’Ңе·Ҙе…·гҖӮ
гҖҖгҖҖж•ҙеҗҲжңҚеҠЎеҷЁгҖҒеӯҳеӮЁе’Ңе®ўжҲ·з«Ҝе·Ҙе…·гҖӮ
гҖҖгҖҖи®ҫи®Ўд»“еә“иЎЁе’Ңи§ҶеӣҫгҖӮ
гҖҖгҖҖе®ҡд№үзү©зҗҶд»“еә“з»„з»ҮпјҢж•°жҚ®еёғеұҖгҖҒеҲҶеҢәе’Ңи®ҝй—®ж–№жі•гҖӮ
гҖҖгҖҖдҪҝз”ЁзҪ‘е…ігҖҒODBCй©ұеҠЁзЁӢеәҸпјҢжҲ–е…¶д»–зҡ„еҢ…иЈ…еҷЁиҝһжҺҘж•°жҚ®жәҗпјҢгҖӮ
гҖҖгҖҖи®ҫи®Ўе’Ңе®һзҺ°ж•°жҚ®жҸҗеҸ–гҖҒжё…жҙ—гҖҒиҪ¬жҚўгҖҒеҠ иҪҪе’ҢеҲ·ж–°зҡ„и„ҡжң¬гҖӮ
гҖҖгҖҖиҙ®еӯҳиЎЁе’Ңи§Ҷеӣҫзҡ„е®ҡд№үгҖҒи„ҡжң¬е’Ңе…¶д»–е…ғж•°жҚ®гҖӮ
гҖҖгҖҖи®ҫи®Ўе’Ңе®һзҺ°з»Ҳз«Ҝз”ЁжҲ·еә”з”ЁзЁӢеәҸгҖӮ
гҖҖгҖҖжҺЁеҮәд»“еә“е’Ңеә”з”ЁзЁӢеәҸгҖӮ
гҖҖгҖҖ3. еҗҺз«Ҝе·Ҙе…·е’Ңе®һз”ЁзЁӢеәҸ
гҖҖгҖҖж•°жҚ®д»“еә“зі»з»ҹдҪҝз”Ёеҗ„з§Қж•°жҚ®жҸҗеҸ–е’Ңжё…жҙ—е·Ҙе…·пјҢеҪ•е…Ҙд»“еә“зҡ„еҠ иҪҪе’Ңжӣҙж–°зҡ„е®һз”ЁзЁӢеәҸгҖӮйҖҡеёёеӨ–жқҘжәҗзҡ„ж•°жҚ®жҸҗеҸ–зҡ„е®һзҺ°йңҖиҰҒйҖҡиҝҮзҪ‘е…іе’Ңж ҮеҮҶжҺҘеҸЈпјҲеҰӮInformation Builders EDA/SQLпјҢ ODBCпјҢ Oracle Open ConnectпјҢ Sybase Enterprise ConnectпјҢ Informix Enterprise GatewayпјүгҖӮ
гҖҖгҖҖж•°жҚ®жё…жҙ—
гҖҖгҖҖз”ұдәҺж•°жҚ®д»“еә“жҳҜз”ЁдәҺеҶізӯ–пјҢж•°жҚ®д»“еә“дёӯзҡ„ж•°жҚ®жӯЈзЎ®жҖ§зҡ„йқһеёёйҮҚиҰҒзҡ„гҖӮ然иҖҢпјҢеӣ дёәеӨ§йҮҸзҡ„ж•°жҚ®жқҘиҮӘеӨҡдёӘеҸӮдёҺзҡ„ж•°жҚ®жәҗпјҢж•°жҚ®дёӯеҮәзҺ°й”ҷиҜҜе’ҢејӮеёёзҡ„жҰӮзҺҮеҫҲй«ҳгҖӮеӣ жӯӨпјҢеё®еҠ©жЈҖжөӢж•°жҚ®зҡ„ејӮеёёе’ҢеҜ№е…¶ж”№жӯЈзҡ„е·Ҙе…·пјҢеҸҜд»ҘеёҰжқҘеҫҲй«ҳй«ҳж•ҲзӣҠгҖӮеңЁдёҖдәӣжғ…еҶөдёӢпјҢж•°жҚ®жё…жҙ—жҳҫеҫ—йқһеёёжңүеҝ…иҰҒпјҡеӯ—ж®өй•ҝеәҰдёҚдёҖиҮҙпјҢдёҚдёҖиҮҙзҡ„жҸҸиҝ°пјҢдёҚдёҖиҮҙзҡ„д»·еҖјеҲҶй…ҚпјҢзјәеӨұзҡ„жқЎзӣ®е’ҢиҝқиғҢе®Ңж•ҙжҖ§зәҰжқҹгҖӮеҸҜжғіиҖҢзҹҘпјҢж•°жҚ®еҪ•е…ҘиЎЁдёӯзҡ„еҸҜйҖүеӯ—ж®өжҳҜдёҚдёҖиҮҙж•°жҚ®зҡ„йҮҚиҰҒжқҘжәҗгҖӮ
гҖҖгҖҖжңүдёүдёӘзӣёе…іпјҢдҪҶдёҚеҗҢзҡ„зұ»ж•°жҚ®жё…зҗҶе·Ҙе…·гҖӮж•°жҚ®иҝҒ移е·Ҙе…·еҸҜд»ҘеҲ¶е®ҡз®ҖеҚ•иҪ¬жҚўи§„еҲҷпјҢдҫӢеҰӮпјҢз”ЁжҖ§еҲ«з§Қзұ»жқҘжӣҝжҚўжҖ§еҲ«еӯ—з¬ҰдёІгҖӮPrismзҡ„Warehouse ManagerжҳҜиҝҷз§Қзұ»еһӢзҡ„е·Ҙе…·дёӯжҜ”иҫғжөҒиЎҢзҡ„дёҖдёӘгҖӮж•°жҚ®жё…зҗҶе·Ҙе…·дҪҝз”Ёзү№е®ҡйўҶеҹҹзҡ„зҹҘиҜҶпјҲеҰӮйӮ®ж”ҝең°еқҖпјүжқҘеҜ№ж•°жҚ®иҝӣиЎҢжё…зҗҶгҖӮ他们з»ҸеёёеҲ©з”Ёи§Јжһҗе’ҢжЁЎзіҠеҢ№й…ҚжҠҖжңҜжқҘе®ҢжҲҗжқҘзқҖеӨҡдёӘжәҗзҡ„жё…жҙ—гҖӮдёҖдәӣе·Ҙе…·еҸҜд»ҘжҢҮе®ҡжәҗзҡ„“зӣёеҜ№жё…жҙ—”гҖӮ Integrityе’ҢTrillumзӯүе·Ҙе…·еұһдәҺжӯӨзұ»гҖӮж•°жҚ®е®Ўи®Ўе·Ҙе…·еҸҜд»ҘйҖҡиҝҮжү«жҸҸж•°жҚ®д»ҺиҖҢеҸ‘зҺ°и§„еҲҷе’Ңе…ізі»пјҲжҲ–жҸҗйҶ’иҝқиғҢдәҶ规е®ҡзҡ„规еҲҷпјүгҖӮеӣ жӯӨпјҢиҝҷж ·зҡ„е·Ҙе…·еҸҜд»Ҙи®ӨдёәжҳҜж•°жҚ®жҢ–жҺҳе·Ҙе…·зҡ„еҸҳдҪ“гҖӮиҝҷж ·зҡ„е·Ҙе…·еҸҜиғҪдјҡеҸ‘зҺ°дёҖдёӘеҸҜз–‘зҡ„ж ·жң¬пјҲеҹәдәҺз»ҹи®ЎеҲҶжһҗпјүпјҢдҫӢеҰӮпјҢжҹҗжұҪиҪҰз»Ҹй”Җе•Ҷд»ҺжңӘ收еҲ°д»»дҪ•жҠ•иҜүгҖӮ
гҖҖгҖҖеҠ иҪҪ
гҖҖгҖҖжҸҗеҸ–гҖҒжё…жҙ—е’ҢиҪ¬жҚўеҗҺпјҢж•°жҚ®еҝ…йЎ»иў«еҠ иҪҪеҲ°д»“еә“гҖӮйўқеӨ–зҡ„йў„еӨ„зҗҶеҸҜиғҪд»Қ然被йңҖиҰҒпјҡжЈҖжҹҘе®Ңж•ҙжҖ§зәҰжқҹ;жҺ’еәҸ;йҖҡиҝҮжҖ»з»“гҖҒиҒҡеҗҲе’Ңе…¶д»–и®Ўз®—жқҘе»әз«ӢеӯҳеӮЁеңЁд»“еә“дёӯзҡ„жҙҫз”ҹиЎЁ;еҲӣе»әзӣ®еҪ•е’Ңе…¶д»–и®ҝй—®и·Ҝеҫ„;еҲҶеҢәе®һзҺ°еӨҡдёӘзӣ®ж ҮеӯҳеӮЁеҢәеҹҹгҖӮйҖҡеёёжғ…еҶөдёӢпјҢжү№йҮҸиЈ…иҪҪе·Ҙе…·еҸҜд»Ҙз”ЁжқҘеҒҡиҝҷ件дәӢгҖӮйҷӨдәҶеЎ«е……д»“еә“пјҢдёҖдёӘиҙҹиҪҪе·Ҙе…·еҝ…йЎ»е…Ғи®ёзі»з»ҹз®ЎзҗҶе‘ҳзӣ‘жҺ§зҠ¶жҖҒпјҢеҸ–ж¶ҲгҖҒжҢӮиө·е’ҢжҒўеӨҚдёҖдёӘиҙҹиҪҪпјҢеӨұиҙҘеҗҺйҮҚеҗҜиҖҢжІЎжңүжҚҹеӨұж•°жҚ®зҡ„е®Ңж•ҙжҖ§гҖӮ
гҖҖгҖҖж•°жҚ®д»“еә“зҡ„еҠ иҪҪе·Ҙе…·еҝ…йЎ»еӨ„зҗҶжҜ”ж“ҚдҪңж•°жҚ®еә“жӣҙеӨ§и§„жЁЎзҡ„ж•°жҚ®йҮҸгҖӮеҸӘжңүдёҖдёӘе°Ҹж—¶й—ҙзӘ—еҸЈдёӯпјҲйҖҡеёёеңЁжҷҡдёҠпјүпјҢд»“еә“еҸҜд»ҘзҰ»зәҝеҲ·ж–°е®ғгҖӮиҝһз»ӯеҠ иҪҪдјҡиҠұиҙ№еҫҲй•ҝзҡ„ж—¶й—ҙпјҢдҫӢеҰӮгҖӮпјҢеҸҜд»ҘеҠ иҪҪTBзә§зҡ„ж•°жҚ®дјҡиҠұеҮ е‘Ёе’ҢеҮ дёӘжңҲж—¶й—ҙпјҒеӣ жӯӨпјҢйҖҡеёёйңҖиҰҒеҲ©з”Ёз®ЎзәҝејҸе’ҢеҲҶеҢәејҸзҡ„并иЎҢжҖ§гҖӮиҝӣиЎҢдёҖдёӘж»ЎиҪҪзҡ„дјҳеҠҝеңЁдәҺе®ғеҸҜд»Ҙиў«и§ҶдёәдёҖдёӘй•ҝзҡ„жү№еӨ„зҗҶдәӢеҠЎпјҢжқҘе»әз«ӢдёҖдёӘж–°зҡ„ж•°жҚ®еә“гҖӮиҷҪ然еңЁиҝҗиЎҢдёӯпјҢдҪҶжҳҜеҪ“еүҚж•°жҚ®еә“д»Қ然еҸҜд»Ҙж”ҜжҢҒжҹҘиҜў;еҪ“иҙҹиҪҪдәӢеҠЎжҸҗдәӨж—¶пјҢеҪ“еүҚж•°жҚ®еә“иў«ж–°зҡ„ж•°жҚ®еә“жүҖеҸ–д»ЈгҖӮдҪҝз”Ёе‘ЁжңҹжЈҖжҹҘзӮ№дҝқиҜҒпјҢеҰӮжһңеҠ иҪҪиҝҮзЁӢдёӯеҸ‘з”ҹдәҶеӨұиҙҘпјҢиҝҷдёӘиҝӣзЁӢеҸҜд»Ҙд»ҺдёҠдёӘжЈҖжҹҘзӮ№йҮҚеҗҜгҖӮ
гҖҖгҖҖ然иҖҢпјҢеҚідҪҝдҪҝ用并иЎҢжҖ§пјҢдёҖдёӘж»ЎиҪҪеҸҜиғҪд»Қ然йңҖиҰҒеӨӘй•ҝзҡ„ж—¶й—ҙгҖӮеӨ§еӨҡж•°е•Ҷдёҡе·Ҙе…·пјҲеҰӮпјҢRedBrick Table Management UtilityпјүеңЁеҲ·ж–°иҝҮзЁӢдёӯдҪҝз”ЁеўһйҮҸеҠ иҪҪпјҢжқҘйҷҚдҪҺеҝ…йЎ»иў«зәіе…Ҙд»“еә“зҡ„ж•°жҚ®и§„жЁЎгҖӮеҸӘжҸ’е…Ҙжӣҙж–°зҡ„е…ғз»„гҖӮ然иҖҢпјҢиҝҷж ·зҡ„еҠ иҪҪиҝҮзЁӢжӣҙеҠ йҡҫд»Ҙз®ЎзҗҶдәҶгҖӮеўһйҮҸеҠ иҪҪдјҡдёҺжӯЈеңЁиҝӣиЎҢзҡ„жҹҘиҜўиө·еҶІзӘҒпјҢжүҖд»Ҙе®ғиў«дҪңдёәдёҖдёӘзҹӯдәӢеҠЎпјҲе®ҡжңҹжҸҗдәӨпјҢеҰӮпјҢжҜҸйҡ”1000дёӘи®°еҪ•жҲ–жҜҸйҡ”еҮ з§’пјүпјҢдҪҶиҝҷж ·дёҖжқҘиҝҷдёӘдәӢеҠЎзҡ„еәҸеҲ—еҝ…йЎ»иў«и®ҫи®ЎпјҢжқҘзЎ®дҝқеҜјеҮәж•°жҚ®дёҺеҹәзЎҖж•°жҚ®зҡ„зҙўеј•зҡ„дёҖиҮҙжҖ§гҖӮ
-
еҰӮдҪ•жҸҗй«ҳж•°жҚ®д»“еә“зҡ„жҖ§иғҪеҸҠдјҳеҢ–и®ҫи®Ў2023-07-18 963
-
д»Җд№ҲжҳҜж•°жҚ®д»“еә“пјҹж•°жҚ®д»“еә“зҡ„дјҳеҠҝеҲҶжһҗ2020-11-01 10306
-
ж•°жҚ®д»“еә“зҡ„жҰӮиҝ°д»ҘеҸҠеҲӣе»әжӯҘйӘӨз®Җд»Ӣ2020-06-09 2190
-
еӨ§ж•°жҚ®ж•°жҚ®д»“еә“еә”иҜҘеҰӮдҪ•е»әи®ҫ2020-03-10 1423
-
еҰӮдҪ•жҗӯе»әж•°жҚ®д»“еә“2019-06-25 4306
-
еӨ§ж•°жҚ®д№ӢHiveж•°жҚ®д»“еә“2019-03-19 3044
-
ж•°жҚ®д»“еә“жҳҜд»Җд№Ҳ_ж•°жҚ®д»“еә“жңүд»Җд№Ҳзү№зӮ№_ж•°жҚ®еә“е’Ңж•°жҚ®д»“еә“еҢәеҲ«еҲҶжһҗ2018-02-24 20110
-
ж•°жҚ®д»“еә“зҡ„еҹәжң¬жһ¶жһ„еҸҠжһ¶жһ„еӣҫд»Ӣз»Қ2018-02-11 62874
-
ж•°жҚ®д»“еә“зҡ„OLAPеӨҡз»ҙеұ•зҺ°жҠҖжңҜзҡ„з ”з©¶дёҺеә”з”Ё2012-08-08 1228
-
OLAPеңЁз”өдҝЎж•°жҚ®д»“еә“дёӯзҡ„и®ҫи®Ў2010-12-29 1209
-
з”өдҝЎж•°жҚ®д»“еә“и®ҫи®Ў2009-12-18 1002
-
з»ҹи®ЎиЎҢдёҡж•°жҚ®д»“еә“жһ„е»әеҸҠеә”з”Ё2009-09-16 732
-
еӨҡзүҲжң¬ж•°жҚ®д»“еә“жЁЎеһӢи®ҫи®Ў2009-04-21 1311
-
й«ҳж ЎиҙўеҠЎж•°жҚ®д»“еә“зҡ„и®ҫи®ЎдёҺе®һзҺ°2009-04-17 1211
е…ЁйғЁ0жқЎиҜ„и®ә

еҝ«жқҘеҸ‘иЎЁдёҖдёӢдҪ зҡ„иҜ„и®әеҗ§ !
