

Capsule Network的基本原理及其相关算法实例详解
电子说
描述
漫谈Capsule Network基本原理
半个多月前,Hinton的让人期待已久的Dynamic Routing Between Capsules终于在arixv上公开,第一作者是Sara Sabour,据Hinton本人介绍,Sabour是伊朗人,本来想去华盛顿大学读计算机视觉,但是签证被美国拒绝了,于是Google的多伦多人工智能实验室挖到了她,跟随Hinton一起做Capsule Network方面的研究。
Dynamic Routing Between CapsulesMatrix Capsules with EM Routing
首先我们谈谈Hinton为什么要提出Capsule Network,传统的图像识别是使用CNN来做的(如下图所示),CNN通常由卷积层和池化层共同构成,卷积层从原始图像中提取每个局部的特征,池化层则负责将局部特征进行概括,最终模型通过softmax分类器输出每个类别的概率分布。
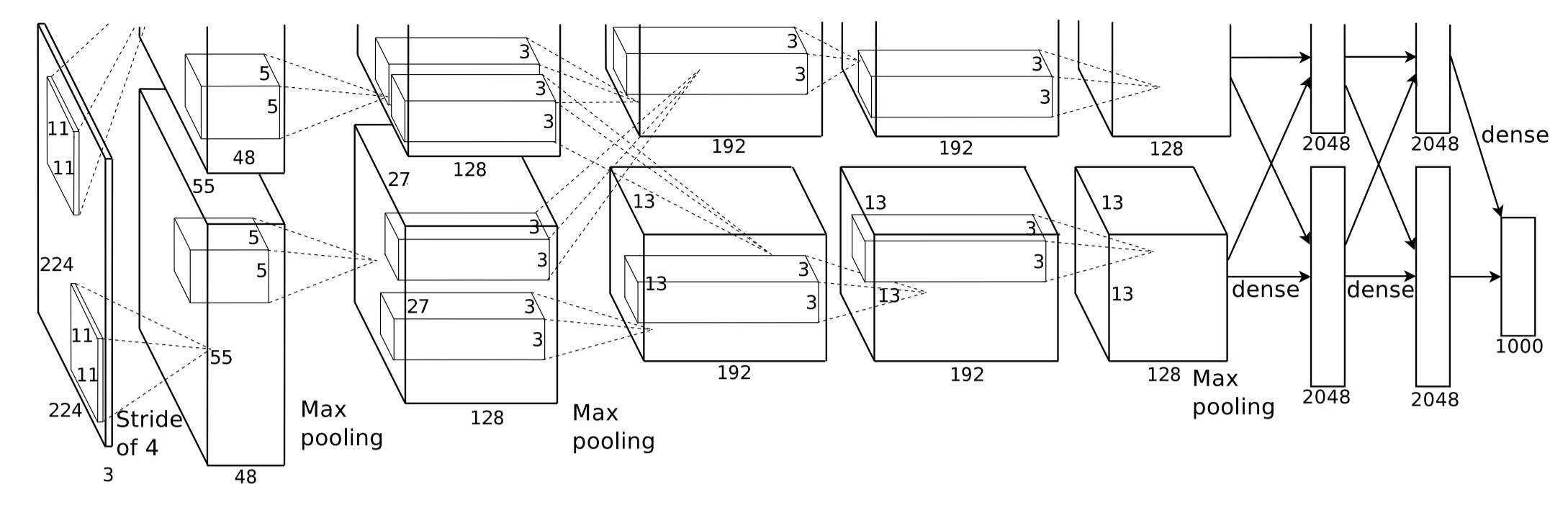
CNN应用到图像识别上似乎非常合理,而且实际表现也非常好,但是Hinton则认为CNN中的池化操作是一个灾难,原因就在于池化操作只能给出粗略的位置信息,允许模型对一些小的空间上的变化视而不见,并不能精准地学习到不同物体的位置关联,比如一个区域内的实体的位置、大小、方向甚至是变形度和纹理。虽然CNN可以识别一张正常的人脸,但是如果把人脸照片中的一只眼睛与嘴巴的位置对调一下,CNN还是会将其识别成人脸,这是不对的。虽然池化的本意是为了保持实体的位置、方向的不变性,但是实际中的简单粗暴的取最大或取平均的池化操作会使得池化的效果事与愿违。
人类识别图片是基于平移和旋转将看到的图片与大脑中已有的模式进行匹配,例如,对于一个雕像,无论以什么角度取拍照,人们都可以轻松识别出它就是一个雕像,但是这个对于CNN来说是十分困难的,为了解决这个问题,即更好地表示实体的各种空间属性信息,Hinton在这篇文章中介绍了Capsule Network的概念。
Capsule Network的每一层是由很多Capsule构成的,一个Capsule可以输出一个活动向量,该向量就代表着一个实体的存在,向量的方向代表着实体的属性信息,向量的长度代表实体存在的概率,所以,即使实体在图片中的位置或者方向发生了改变,则仅仅导致该向量的方向发生变化,而向量的长度没有发生改变,也就是实体存在的概率没有变化。
与传统的神经元模型不同的是,传统的神经元是通过将每个标量进行加权求和作为输入,然后通过一个非线性激活函数(如sigmoid,tanh等等)映射到另外一个标量,而Capsule Network则是每一层都是由一些Capsule构成,其具体的工作原理可以分为以下几个阶段:
(1) 较低层的Capsule产生的活动向量u_i与一个权重矩阵W_ij相乘,得到了预测向量u_ij_hat,这个向量的含义就是根据低维特征预测得到高维特征的位置,举个例子,如果要识别一辆马车,那么某一层低维的特征是马和车,那么根据马就可以判断马车的总体位置,同样也可以根据车来判断马车的位置,如果这两个低维特征的判断的马车的位置完全一致的话,就可以认为这就是一辆马车了;
(2) 如果用u表示上一层的所有Capsule的输出矩阵,用v表示下一层的所有Capsule的输出矩阵,由(1)知道,上一层的每一个Capsule的输出向量u_i经过权重算出了预测向量u_ij_hat,那么接下来它需要把这个预测向量传递给下一层的每个Capsule,但不是完全对等地发给下一层的每一个Capsule,而是先要乘以耦合系数c_ij,这个耦合系数可以认为是代表低维特征对高维特征的预测程度,至于这个耦合系数c是怎么确定的,后文会详细介绍iterative dynamic routing过程;
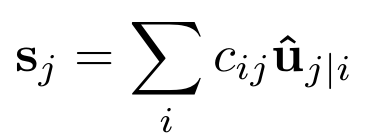
(3) 将传送到下一层的第j个Capsule的所有信号求和,即s_j=SUM(c_ij×u_ij_hat),这一点和神经元模型中的w*x类似,只不过一个是标量运算,另一个是向量运算;
(4) 类似于神经元模型中的激活函数sigmoid将输入映射到0~1的区间,这里作者采用了非线性的squashing函数来将较短的向量映射成长度接近于0的向量,将较长的向量映射成长度接近于1的向量,而方向始终保持不变,这个过程相当于是对预测向量做了归一化,最终得到的v_j就是下一层第j个Capsule的输出向量。
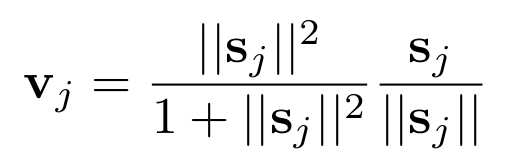
以上就是相邻层之间的Capsule的活动向量的计算流程,接下来我们来看一下相邻层的Capsule之间的耦合向量c_ij是如何确定的。
首先我们需要明白,既然是权重,那么对于上一层的Capsule i,它的所有c_ij之和必定等于1,并且c_ij的个数是等于下一层中Capsule的个数。这个c_ij是经过iterative dynamic routing算法确定的,dynamic routing算法的核心就是要求较浅层的Capsule的活动向量与较高层的Capsule的活动向量保持极高的相似度。

如上图算法图所示,第二行中的b_ij是一个未经归一化的临时累积变量,初始值为0,它的个数是由上一层和下一层的Capsule的个数决定的;每次迭代中,先将b经过softmax归一化得到总和为1均为正数的系数c_ij,第五行和第六行是进行前向计算并经过squashing函数进行归一化得到下一层的Capsule的输出v_j,第七行是更新c_ij(即更新b_ij)的核心,新的b_ij等于旧的b_ij加上上一层的Capsule与下一层的Capsule的“相似度”。从图中可以看到,这个迭代过程似乎没有收敛条件,关于迭代次数,文中并没有给出详细的说明,而是指出了迭代次数越多则发生过拟合的概率越大,在MNIST手写字体识别实验中,迭代次数设置为3得到的性能较好。
上面讲了这么多,仅仅说明了c_ij的确定算法,似乎还有一个问题没有解决,那就是确定其他参数的值?回到老方法,文中依然采用了后向传播算法来更新参数值,这就涉及到目标函数的确定。以MNIST手写数字识别为例,由于输出的类别是10,那么可以在最后一层中设置Capsule的个数为10,对于每个Capsule的loss可以按照如下公式进行计算,总loss就是把10个Capsule的loss求和即可。

除了介绍Capsule Network模型之外,文中还设计了一个基于卷积神经网络的Capsule Network用于MNIST手写字识别,如下图所示是一个简单三层结构的Capsule Network,一幅图片首先经过一层CNN(卷积核大小为9×9,包含256个feature map,stride设置为1,激活函数为ReLU)得到局部特征作为初级Capsule的输入,初级Capsule是一个包含32个feature map的卷积层,卷积核大小为9×9,stride为2,卷积神经元个数为8,也就是说这一层中一共有32×6×6个Capsule,并且每个Capsule的活动向量的维度是8,每个Capsule都是处在6×6的网格之中,它们彼此共享着它们的权重,并且卷积中用的激活函数就是前文说的squashing函数。最后一层DigitCaps是由10个Capsule组成的,每个Capsule的活动向量维度是16,在PrimaryCapsules与DigitCaps之间需要执行iterative dynamic routing算法来确定耦合系数c_ij,整个过程使用的是Adam优化算法来对参数进行更新。
文中仅仅使用了较小的数据集MNIST作为模型性能的评估,期待Capsule Network应用到更大规模机器学习任务上的表现,接下来几期将继续关注Capsule Network的研究进展及其在语音识别中的TensorFlow实践。
-
嵌入式系统中语音算法的基本原理是什么2021-12-23 1762
-
PID算法基本原理及其执行流程2021-12-21 1264
-
DMA基本原理及相关实验相关资料推荐2021-12-10 1242
-
PCB布局布线的相关基本原理和设计技巧2021-11-05 1730
-
视频增强算法的基本原理是什么?2021-06-03 1532
-
蚁群算法的基本原理及其改进算法.ppt2018-04-23 1482
-
蚁群算法基本原理及其应用实例2018-02-02 94199
-
遗传算法的基本原理2018-01-07 1960
-
傅立叶变换红外光谱仪的基本原理及其应用2017-02-07 1672
-
ZoomFFT算法基本原理及其应用介绍(雷达频谱局部细化,提高分辨率)2016-06-15 11054
-
扩频通信的基本原理2013-11-15 4708
-
脉宽调制的基本原理及其应用实例2010-01-10 1194
-
FFT的基本原理及算法结构2009-06-14 87341
-
LSB算法的基本原理2008-12-09 8198
全部0条评论

快来发表一下你的评论吧 !
