

差分隐私和现有的隐私保护方法相结合:从用户群体中学习的系统架构详解
电子说
描述
了解人们如何使用他们的设备通常有助于改善用户体验。但是,若想得到能洞察用户行为的数据(例如用户在键盘上打了什么字、访问了什么网站),可能会侵犯他们的隐私。
近日,苹果公司开发了一个系统架构,利用本地化差分隐私(local differential privacy)并结合现有的保护隐私的最佳方法,实现规模化学习(learning at scale)。研究人员设计了高效可扩展的本地化差分隐私算法,经过严谨的分析确定了应用程序、隐私、服务器计算能力和设备带宽四个要素的重要性应如何分配。平衡这些因素将有助于成功地部署本地差分隐私。这一部署将覆盖数以亿计的用户,例如在Safari中跟踪最受欢迎的emoji、最常用的健康数据类型以及媒体播放偏好。后台回复“dp”可查看完整版论文。
项目介绍
深入了解用户的整体行为对于改善用户体验至关重要,但所需的数据较为敏感私密,公司必须予以保密。除此之外,利用这些数据部署学习系统还必须考虑资源开销、计算成本和通信成本。在本文中,作者概述了将差分隐私和现有的隐私保护方法相结合,然后从用户群体中学习的系统架构。
经过严格的数学证明,差分隐私是目前最强的隐私保障法之一。它的原理在于用仔细调整过的噪声掩盖用户的数据。当许多人提交数据时,增加到其中的噪声达到平衡,并产生有意义的信息。
在差分隐私框架内,有两种设定:中心(central)和本地(local)。在这套系统中,苹果不收集中心化差别隐私所需的服务器上的原始数据,而是采用本地化差别隐私,这种形式更加可靠。本地差分隐私在数据被发送前就做了随机处理,所以服务器无法看到或接收到原始数据。
该系统非常透明,用户可以自愿选择是否加入。若用户不同意上报使用信息,则不会记录或传输他们的私人数据。通过本地化的差分隐私,用户的设备依据时间等级进行加密。另外,该系统还限制上传隐私事件的数量。将信息传输到服务器每天只有一次,而且是在加密通道上进行,没有用户ID。用户信息最终会到达一个访问受限的服务器,其中没有IP标识符,也没有与其他记录相关联的信息。所以,我们无法区分一个emoji和另一个Safari网页记录是否来自同一个用户,也就是说这些信息是完全保密的。这些记录经过处理后加入统计数据中,然后再由苹果内部相关团队进行分析。
同时,苹果的研究人员还在估计各种记录的频率,例如emoji和网络域名。他们有两个想法:从已知的所有类别的记录中生成直方图,或者自己创造一个能表现出数据集中出现频率最多的图表。
系统架构
该系统架构由设备端和服务端的数据组成。在设备上,原始数据在加密阶段分别进行处理。受限访问的服务器在对数据处理后进一步将其分为数据接入和数据聚合阶段。下面就为大家详细介绍每一个阶段。
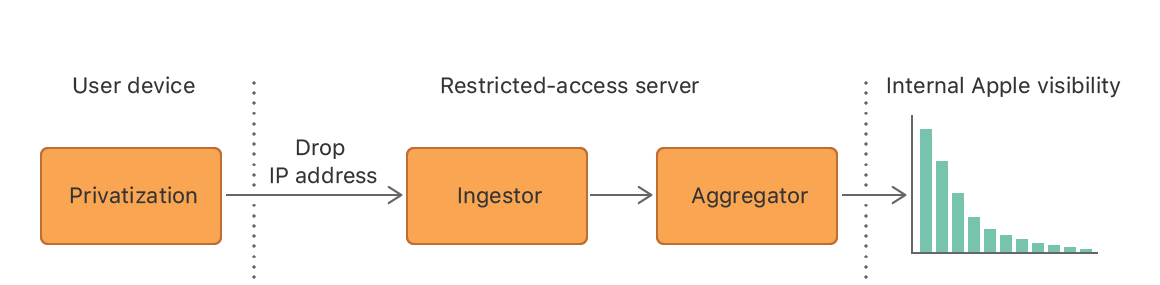
信息加密(Privatization)
用户可在macOS或iOS的“系统偏好设置”里选择是否同意共享个人记录以供分析。对于不愿加入的用户,系统将不会开启服务。而对于愿意使用这项功能的用户,苹果内部为每个用户行为都设置了隐私参数ϵ。
苹果还对每天传输的每项记录设置了数量限制。而对于隐私参数ϵ的选择,则是基于每个记录的基础数据集的隐私特性。这些值与其他研究差分隐私的项目提出的参数是一致的。而且,由于hash冲突,下面的算法给用户提供了进一步的否认条件。除了上述的方法,苹果还会删除用户的ID和IP地址来进一步加强隐私,服务器上所产生的的用户ID和IP地址是分隔开的,所以多个记录之间没有关联。
无论何时用户使用了设备,数据会立即通过有特殊参数ϵ的本地差分隐私进行加密,并使用数据保护(data protection)临时储存在设备上,而不是立即传输到服务器上。
系统会根据设备的情况进行延迟,之后会随机抽取不同的私人记录,并将采样记录发送给服务器。这些记录不包括设备ID或该行为发生的时间。设备和服务器之间的通信使用TLS进行加密。
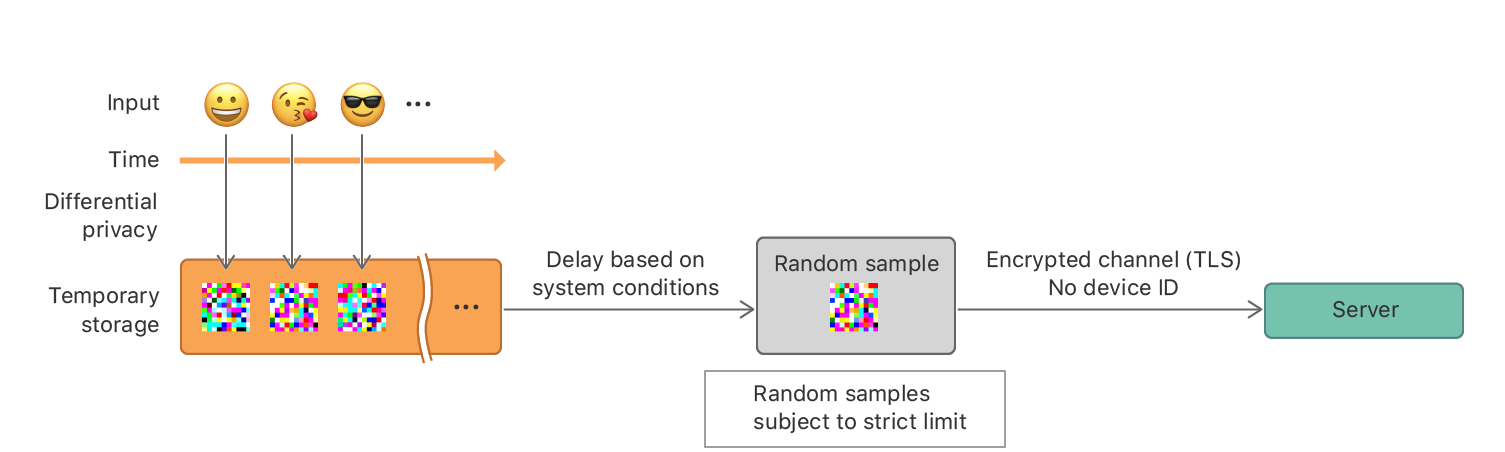
加密过程
在iOS中打开“设置”>“隐私”>“分析”>“分析数据”后可看到“差分隐私”(DifferentialPrivacy)的入口。在macOS上,这些记录在“关于本机”的“系统报告”中可见。下图是算法对最受欢迎的emoji使用情况的样本记录,记录所涉及的算法和参数在下文会有体现。

加密记录的样本报告
数据接入和聚合
在数据接入之前,加密记录会删除掉IP地址,然后数据库收集所有用户数据后进行批量处理。这一过程将删除元数据,例如记录发生的时间,并且根据记录情况把它们分类。在将结果输入到下一阶段前,数据库也会随机对每个用户行为记录进行排序。
聚合器收到来自数据库的记录后,根据算法为每个使用记录生成个性化的直方图。计算统计数据时,无需合并来自多个记录的数据。在这些直方图中,只有高于规定阈值T的域名才算入其中。
算法
下面就为大家介绍三种本地化差分隐私算法。
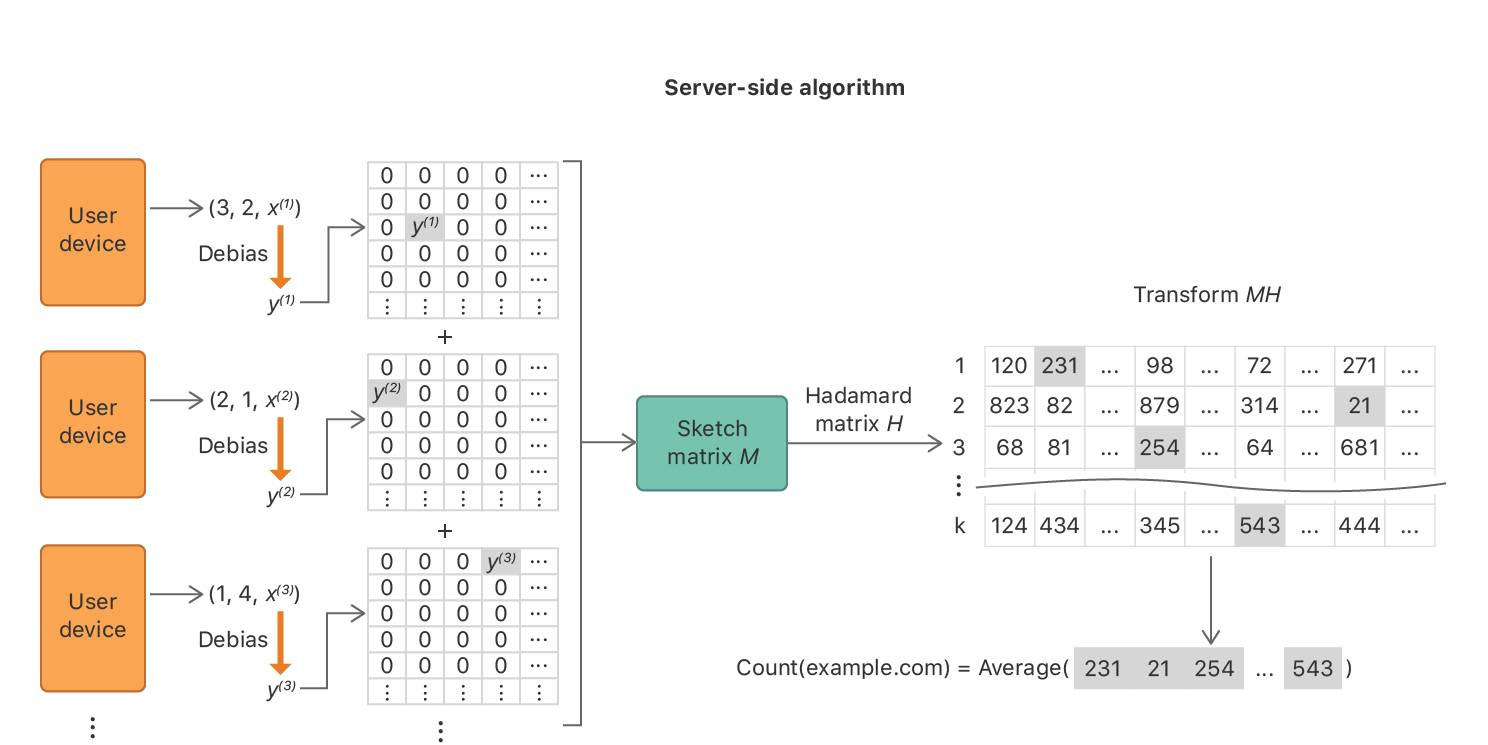
1.Private Count Mean Sketch(CMS)
Private Count Mean Sketch(CMS)算法聚合了设备提交的记录,并在域名类别中输出数量的直方图,同时保留本地化差分隐私。这一过程分为两个阶段:客户端处理和服务器端聚合。
举个例子吧,假设一名用户访问了 www.example.com 这个网站。客户端算法从一组散列函数(hash function){h1,h2,h3,…,hk}中随机抽取一个,假设抽到了h2,然后用它将上述网站域名以m的大小编码,即h2(www.example.com)=31。该编码被写成大小为m的one-hot向量,其中第31位被设置为1。为了确保隐私的差分性,one-hot向量的每一位独立地以概率 翻转,其中ϵ是隐私参数,它构成了私有化的向量。这个向量和被选择的散列函数一起被输送至服务器。
翻转,其中ϵ是隐私参数,它构成了私有化的向量。这个向量和被选择的散列函数一起被输送至服务器。
服务器端的算法通过聚合加密向量组成了sketch矩阵M。该矩阵有k行、m列,每一行都代表一个散列函数,每一列代表从客户端传输来的矢量大小。
当记录到达服务器时,算法将加密过的矢量添加到第j行的矢量,其中j是设备采样的散列函数的指数。然后适当地调整m的值,以便每行都能为每个类别进行无差别的频率计算。
为了计算 www.example.com 的频率,该算法通过读取每个j行的M,然后计算这些结果的平均值。在原始论文中有详细的分析过程。
2.Private Hadamard Count Mean Sketch(HCMS)
在完整版论文中,作者讨论了如何通过增加设备带宽让CMS里的计算更精确。但是,这就增加了用户的传输成本。苹果希望在降低传输成本的同时把对准确性的影响降到最小,于是就有了Private Hadamard Count Mean Sketch算法(HCMS),其优点是设备可以以极小的精度损失进行传输。
依然用上面的来举例。与CMS类似,客户端同样是从一组散列函数{h1,h2,h3,…,hk}中随机抽取一个,假设抽到了h3。然后有h3(www.example.com)=42。编码被写成v=(0,0,…,0,1,0,…,0,0)的one-hot向量,这里第42位设置为1。因为我们只想传输一位信息,所以一个简单的方法就是从向量中抽样并发送一个随机坐标。但是这可能导致结果直方图的错误或变化。为了减少误差,研究人员用Hadamard将v进行转化,即v’=Hv=(+1,-1,…,+1)。同样,为了确保隐私性,向量中的每一位以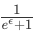 的概率翻转。下图展示了这一过程。
的概率翻转。下图展示了这一过程。
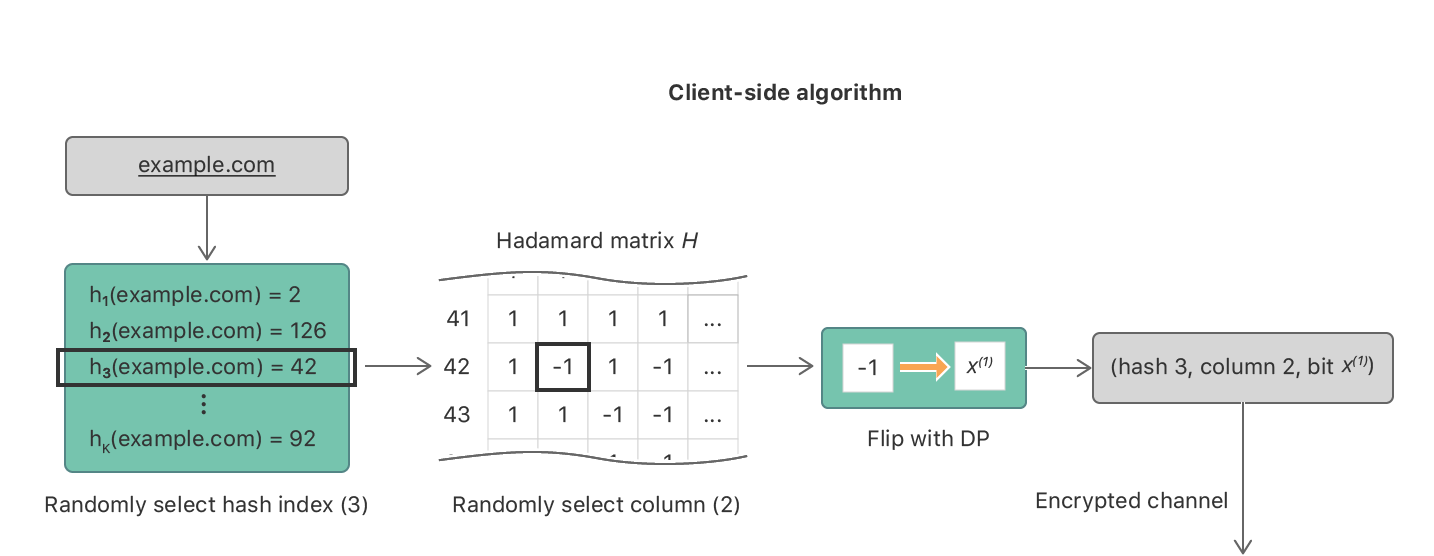
Hadamard Count Mean Sketch中客户端的算法
同样,服务端的算法与CMS的大致相同。
Hadamard Count Mean Sketch中服务端的算法
3.Private Sequence Fragment Puzzle(SFP)
上述两种算法都假设有已知的域名集合,服务器可根据它来列举样本,以确定相应的计数。
然而在某些情况下,一些域名非常大,由于计算能力有限无法全部列举。例如,当研究人员在研究常用单词时,即使限制只能输入10位区分大小写的英文单词,服务器也要进行至少5210次循环。
所以,苹果开发了一种名为Sequence Fragment Puzzle(SFP)的算法,并将其用于发现新单词的任务中。由于一个流行字符串的子字符串使用也很频繁,所以研究人员利用这一点,用客户端的CMS算法对打出的字进行加密。
成果
通过这三种新颖的算法,苹果在提升用户体验方面有了很大的收获。以下是三个典型案例:
发现流行的emoji
emoji是聊天中必不可少的要素,苹果公司想要知道用户最常用的emoji都有哪些,以及地区的相对分布。于是,他们在键盘语言环境中部署了算法。CMS的中的参数设置为:m=1024,k=65536,ϵ=4,本地emoji库中含有2600个emoji。
数据显示,键盘设置不同,emoji使用也有差异。下图是英文和法语两个语言环境下的emoji使用情况。根据这一结果,苹果可以对emoji的快捷输入做本地化调整。
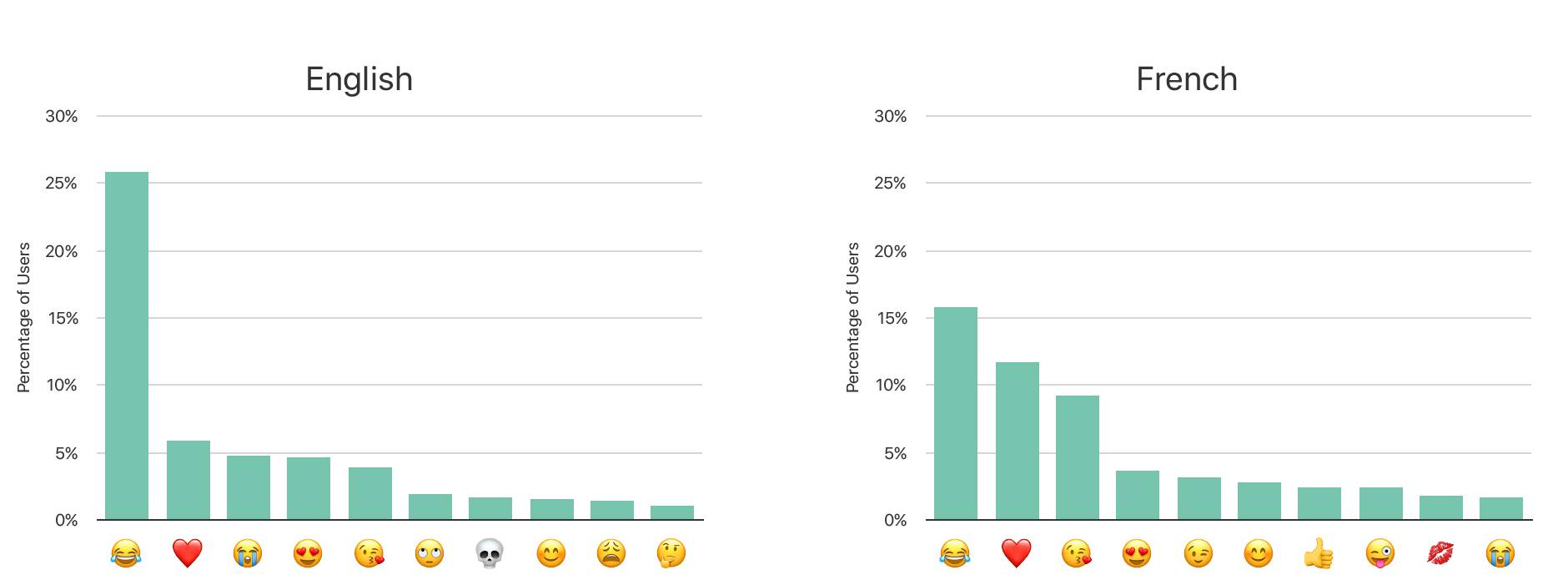
英法两种键盘下人们使用emoji的区别
找到Safari中占用大量内存的网站
有些网站真的是非常消耗资源,苹果公司想找到这些网站,以优化用户体验。他们的目标有两类:浏览时占用大量内存的以及大量占用CPU拖慢速度的。在iOS11和manOS High Sierra中,Safari可以自动检测到这些域名,并通过差分隐私上报这些域名。
利用算法,研究人员发现,最常见的需要消耗大量资源的网站有视频网站、购物网站和新闻网站。
扩充词汇库
为了优化“自动纠错”功能,苹果不断地寻找词库中没有的词语。这里就用到了上面说的SFP算法。
该算法不仅能用在英语环境中,还能用于法语和西班牙语。拿英语来说吧,算法学习到的新单词可以被分为以下几类:
缩写:wyd(what you doing),wbu(what about you),idc(I don’t care);
习惯表达:bruh(bro),hun(honey),bae(baby),tryna(trying to);
流行语:Mayweather,McGregor,Despacito,Moana,Leia;
外文词汇:dia,queso,aqui,jai…
苹果正是利用这些数据不断更新在线词典,改善键盘体验。
他们还发现,现在很多人在打字时都会省去结尾的“e”或者“w”,比如lov(love),th(the)或者kno(know)。所以如果用户不小心选择了第一个预测词语,也就是你目前所打出来的所有字符,那么系统会自动在单词后面添加一个空格,而不是自动替换成你想要输入的那个单词。这一功能正是本地化差分隐私算法带来的。
这篇文章介绍了苹果公司为改善用户体验,同时保护用户隐私推出的一种新颖的学习系统架构,将本地化差分隐私算法覆盖到各个使用层面。同时还提出了三种独特的算法——CMS、HCMS和SFP。这些工具帮助公司看到在不同语言环境下人们使用emoji的差异,并且搜索当下最流行的词语,促进他们改善软件的体验。
研究人员希望这一项目能够弥合隐私理论与实践之间的差距,同时他们相信这一工作将继续推进大规模学习问题的研究,同时进一步增强用户隐私保护。
-
基于差分隐私的轨迹模式挖掘算法2017-11-25 613
-
一种可保护隐私的快速邻近监测方法2017-12-01 491
-
基于查询概率的位置隐私保护方法2017-12-06 680
-
基于差分隐私的数据匿名化隐私保护模型2017-12-11 1030
-
线性查询的一种近似最优差分隐私机制2017-12-26 585
-
一种轨迹差分隐私发布方法2018-01-17 848
-
基于RFID隐私保护分析2018-02-05 889
-
面向随机森林的差分隐私保护算法2018-02-08 747
-
大数据及其隐私保护2018-03-28 797
-
如何使用差分隐私保护进行谱聚类算法2018-12-14 838
-
如何将Qtum量子链与现有的隐私技术相结合2019-06-24 680
-
机器学习框架里不同层面的隐私保护2020-09-04 3810
-
基于ExtraTrees的差分隐私保护算法DiffPETs2021-05-11 673
-
面向差分数据挖掘隐私保护的随机森林算法2021-05-12 627
-
苹果的差分隐私技术原理详解2023-07-19 1328
全部0条评论

快来发表一下你的评论吧 !
