

机器学习之决策树生成详解
人工智能
描述
1.什么是决策树
决策树是一种基本的分类和回归方法,本文主要讲解用于分类的决策树。决策树就是根据相关的条件进行分类的一种树形结构,比如某高端约会网站针对女客户约会对象见面的安排过程就是一个决策树:
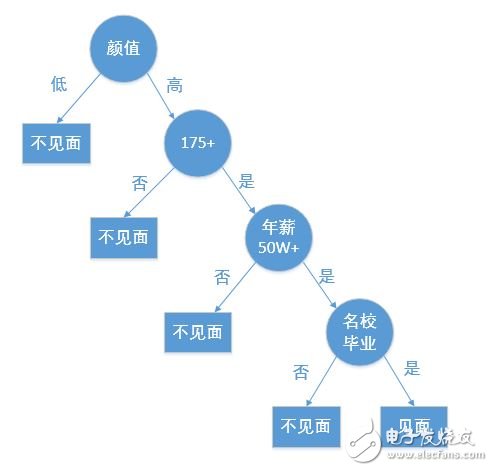
根据给定的数据集创建一个决策树就是机器学习的课程,创建一个决策树可能会花费较多的时间,但是使用一个决策树却非常快。
创建决策树时最关键的问题就是选取哪一个特征作为分类特征,好的分类特征能够最大化的把数据集分开,将无序变为有序。这里就出现了一个问题,如何描述一个数据集有序的程度?在信息论和概率统计中,熵表示随机变量不确定性的度量,即有序的程度。
现给出一个集合D,本文所有的讨论都以该集合为例:
序号 不浮出水面是否可以生存 是否有脚蹼 是否为鱼类
1 是 是 是
2 是 是 是
3 是 否 否
4 否 是 否
5 否 是 否
创建该集合的代码如下:
def create_data_set():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing', 'flippers'] #不浮出水面是否可以生存,是否有脚蹼
return dataSet, labels
2.熵,信息增益和信息增益比
2.1熵(entropy)
博主第一次接触“熵”这个字,是在高中的化学课上,但是感觉“熵”在化学课上的含义和信息论中的含义没什么区别,都是表示混乱的程度,熵越大,越混乱,比如一杯浑浊水的熵就比一杯纯净的水熵大。
在信息论和概率统计中,设X是一个取有限个值的离散随机变量,其概率分布为:

编写计算熵的函数,其中dataSet是建立决策树的数据集,每行最后一个元素表示类别:
def cal_Ent(dataSet): #根据给定数据集计算熵
num = len(dataSet)
labels = {}
for row in dataSet: #统计所有标签的个数
label = row[-1]
if label not in labels.keys():
labels[label] = 0
labels[label] += 1
Ent = 0.0
for key in labels: #计算熵
prob = float(labels[key]) / num
Ent -= prob * log(prob, 2)
return Ent
2.2信息增益(information gain)
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。

当熵和条件熵中的概率由数据估计得到时,所对应的熵与条件熵分别称为经验熵和经验条件熵。
决策树选择某个特征作为其分类特征的依据就是该特征对于集合的信息增益最大,即去除该特征后,集合变得最有序。仍旧以给定的集合D为例,根据计算信息增益准则选择最优分类特征。
以X1表示“不浮出水面是否可以生存”,则

编写选择最佳决策特征的函数,其中dataSet是建立决策树的数据集,每行最后一个元素表示类别:
#按照给定特征划分数据集,返回第axis个特征的值为value的所有数据
def split_data_set(dataSet, axis, value):
retDataSet = []
for row in dataSet:
if (row[axis]) == value:
reducedRow = row[:axis]
reducedRow.extend(row[axis+1:])
retDataSet.append(reducedRow)
return retDataSet
#选择最佳决策特征
def choose_best_feature(dataSet):
num = len(dataSet[0]) - 1 #特征数
baseEnt = cal_Ent(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(num):
featlist = [example[i] for example in dataSet] #按列遍历数据集,选取一个特征的所有值
uniqueVals = set(featlist) #一个特征可以取的值
newEnt = 0.0
for value in uniqueVals:
subDataSet = split_data_set(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEnt += prob * cal_Ent(subDataSet)
infoGain = baseEnt - newEnt #信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
ID3决策树在生成的过程中,根据信息增益来选择特征。
2.3信息增益比(information gain ratio)
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。

以给定的集合D为例,计算信息增益比。
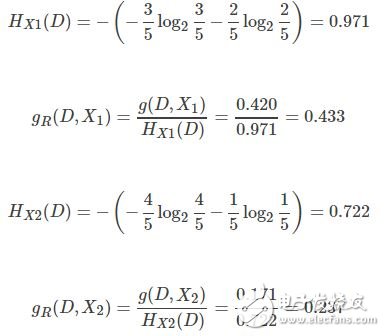
根据信息增益比,选择X1作为分类的最优特征。
C4.5决策树在生成的过程中,根据信息增益比来选择特征。
3.实现一个决策树
3.1创建或载入数据集
首先需要创建或载入训练的数据集,第一节用的是创建数据集的方法,不过更常用的是利用open()函数打开文件,载入一个数据集。
3.2生成决策树
决策树一般使用递归的方法生成。
编写递归函数有一个好习惯,就是先考虑结束条件。生成决策树结束的条件有两个:其一是划分的数据都属于一个类,其二是所有的特征都已经使用了。在第二种结束情况中,划分的数据有可能不全属于一个类,这个时候需要根据多数表决准则确定这个子数据集的分类。
在非结束的条件下,首先选择出信息增益最大的特征,然后根据其分类。分类开始时,记录分类的特征到决策树中,然后在特征标签集中删除该特征,表示已经使用过该特征。根据选中的特征将数据集分为若干个子数据集,然后将子数据集作为参数递归创建决策树,最终生成一棵完整的决策树。
#多数表决法则
def majorityCnt(classList):
print classList
classCount = {}
for vote in classList: #统计数目
if vote not in classCount.keys(): classCount[vote] = 0
classCount += 1
sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return classCount[0][0]
# 生成决策树
def create_tree(dataSet, labels):
labelsCloned = labels[:]
classList = [example[-1] for example in dataSet] #[yes,yes,no,no,no]
if classList.count(classList[0]) == len(classList): #只有一种类别,则停止划分
return classList[0]
if len(dataSet[0]) == 1: #没有特征,则停止划分
return majorityCnt(classList)
#print dataSet
bestFeat = choose_best_feature(dataSet)
bestFeatLabel = labelsCloned[bestFeat] #最佳特征的名字
myTree = {bestFeatLabel:{}}
del(labelsCloned[bestFeat])
featValues = [example[bestFeat] for example in dataSet] #获取最佳特征的所有属性
uniqueVals = set(featValues)
for value in uniqueVals: #建立子树
subLabels = labelsCloned[:] #深拷贝,不能改变原始列表的内容,因为每一个子树都要使用
myTree[bestFeatLabel][value] = create_tree(split_data_set(dataSet, bestFeat, value), subLabels)
return myTree
生成的决策树如下所示:
3.3使用决策树
使用决策树对输入进行分类的函数也是一个递归函数。分类函数需要三个参数:决策树,特征列表,待分类数据。特征列表是联系决策树和待分类数据的桥梁,决策树的特征通过特征列表获得其索引,再通过索引访问待分类数据中该特征的值。
def classify(tree, featLabels, testVec):
firstJudge = tree.keys()[0]
secondDict = tree[firstJudge]
featIndex = featLabels.index(firstJudge) #获得特征索引
for key in secondDict: #进入对应的分类集合
if key == testVec[featIndex]: #按特征分类
if type(secondDict[key]).__name__ == 'dict': #如果分类结果是一个字典,则说明还要继续分类
classLabel = classify(secondDict[key], featLabels, testVec)
else: #分类结果不是字典,则分类结束
classLabel = secondDict[key]
return classLabel
3.4保存或者载入决策树
生成决策树是比较花费时间的,所以决策树生成以后存储起来,等要用的时候直接读取即可。
def store_tree(tree, fileName): #保存树
import pickle
fw = open(fileName, 'w')
pickle.dump(tree, fw)
fw.close()
def grab_tree(fileName): #读取树
import pickle
fr = open(fileName)
return pickle.load(fr)
4.决策树可视化
使用字典的形式表示决策树对于人类来说还是有点抽象,如果能以图像的方式呈现就很方便了。非常幸运,matplotlib中有模块可以使决策树可视化,这里就不讲解了,直接“拿来使用”。将treePlotter.py拷贝到我们文件的根目录,直接导入treePlotter,然后调用treePlotter.createPlot()函数即可:
import treePlotter
treePlotter.createPlot(tree)
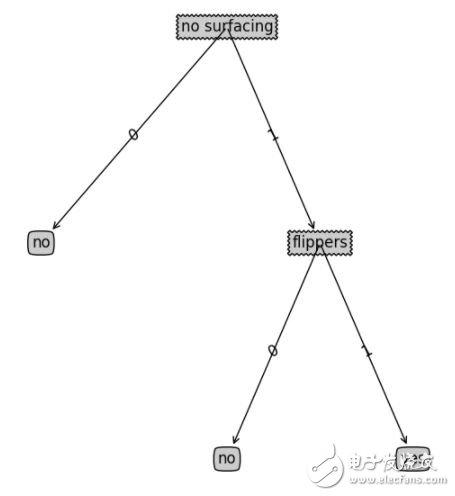
如上面的决策树可视化后如下:
5.使用决策树预测隐形眼镜类型
隐形眼镜数据集包含患者的眼睛状况以及医生推荐的隐形眼镜类型,患者信息有4维,分别表示年龄,视力类型,是否散光,眼睛状况,隐形眼镜类型有3种,分别是软材质,硬材质和不适合带隐形眼镜。
想要把我们编写的脚本应用于别的数据集?没问题,只要修改载入数据集的函数即可,其他的函数不需要改变,具体如下:
#载入数据
def file2matrix():
file = open("lenses.data.txt")
allLines = file.readlines()
row = len(allLines)
dataSet = []
for line in allLines:
line = line.strip()
listFromLine = line.split()
dataSet.append(listFromLine)
labels = ['age', 'prescription', 'astigmatic', 'tear rate'] #年龄,视力类型,是否散光,眼睛状况
return dataSet, labels
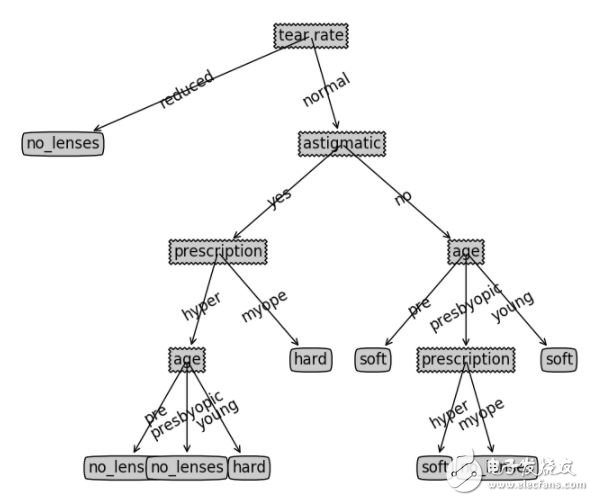
生成的决策树可视化后如下:
其实博主还尝试了其他的数据集,不过决策树实在是太复杂了,太大了,密密麻麻根本看不清楚,谁有兴趣可以尝试一下别的数据集。
- 相关推荐
- 热点推荐
- 机器学习
-
机器学习中常用的决策树算法技术解析2020-10-12 1789
-
关于决策树,这些知识点不可错过2018-05-23 5124
-
决策树在机器学习的理论学习与实践2019-09-20 2148
-
分类与回归方法之决策树2019-11-05 1234
-
机器学习的决策树介绍2020-04-02 1864
-
决策树的生成资料2023-09-08 664
-
基于决策树学习的智能机器人控制方法2015-11-30 534
-
机器学习:决策树--python2017-11-16 2008
-
决策树的原理和决策树构建的准备工作,机器学习决策树的原理2018-10-08 7176
-
详解机器学习决策树的优缺点2020-01-19 8806
-
详谈机器学习的决策树模型2020-07-06 4605
-
决策树的基本概念/学习步骤/算法/优缺点2021-01-27 3381
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 14256
-
决策树的结构/优缺点/生成2021-03-04 8985
-
大数据—决策树2022-10-20 2123
全部0条评论

快来发表一下你的评论吧 !
