

unicode和ascii的区别是什么
编程语言及工具
描述
什么是Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 是为了解决传统的字符编码方案的局限而产生的,例如ISO 8859所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有一个共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。
作用
能够使计算机实现跨语言、跨平台的文本转换及处理。
什么是ASCII
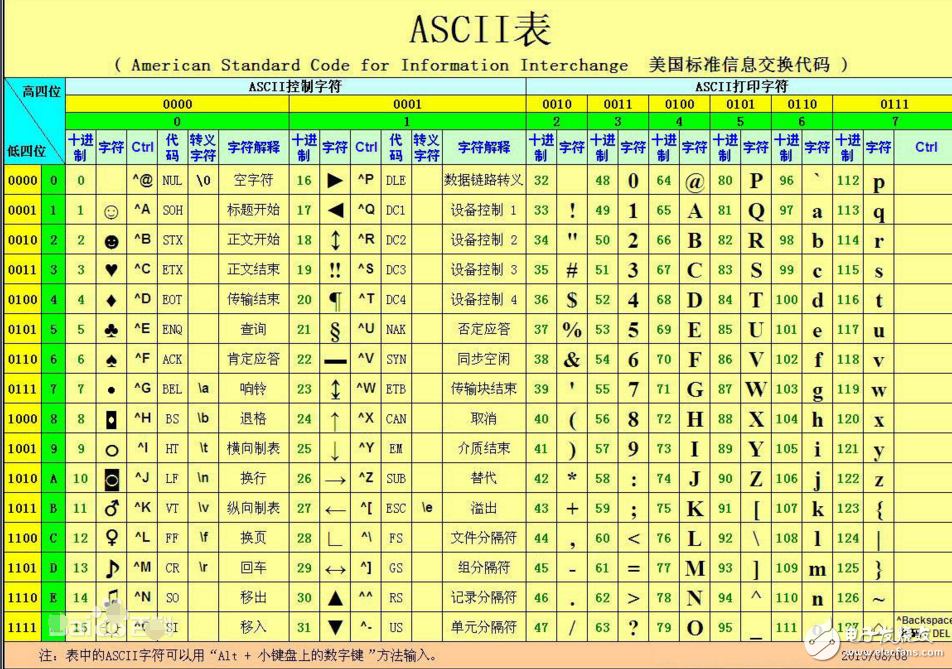
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
请注意,ASCII是American Standard Code for Information Interchange缩写,而不是ASCⅡ(罗马数字2),有很多人在这个地方产生误解。
产生
计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
美国标准信息交换代码是由美国国家标准学会(American National Standard Institute , ANSI )制定的,标准的单字节字符编码方案,用于基于文本的数据。起始于50年代后期,在1967年定案。它最初是美国国家标准,供不同计算机在相互通信时用作共同遵守的西文字符编码标准,它已被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母。
表述方式
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。其中:
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
UNICODE与ASCII的区别
最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。

1.ASCII的特点
ASCII 是用来表示英文字符的一种编码规范。每个ASCII字符占用1 个字节,因此,ASCII 编码可以表示的最大字符数是255(00H—FFH)。这对于英文而言,是没有问题的,一般只什么用到前128个(00H--7FH,最高位为0)。而最高位为1 的另128 个字符(80H—FFH)被称为“扩展ASCII”,一般用来存放英文的制表符、部分音标字符等等的一些其它符号。
但是对于中文等比较复杂的语言,255个字符显然不够用。于是,各个国家纷纷制定了自己的文字编码规范,其中中文的文字编码规范叫做“GB2312—80”, 它是和ASCII 兼容的一种编码规范, 其实就是利用扩展ASCII没有真正标准化这一点,把一个中文字符用两个扩展ASCII 字符来表示,以区分ASCII 码部分。
但是这个方法有问题,最大的问题就是中文的文字编码和扩展ASCII 码有重叠。而很多软件利用扩展ASCII 码的英文制表符来画表格,这样的软件用到中文系统中,这些表格就会被误认作中文字符,出现乱码。另外,由于各国和各地区都有自己的文字编码规则,它们互相冲突,这给各国和各地区交换信息带来了很大的麻烦。
2.UNICODE的产生
要真正解决这个问题,不能从扩展ASCII 的角度入手,UNICODE作为一个全新的编码系统应运而生,它可以将中文、法文、德文……等等所有的文字统一起来考虑,为每一个文字都分配一个单独的编码。
3.什么是UNICODE
Unicode与ASCII一样也是一种字符编码方法,它占用两个字节(0000H—FFFFH),容纳65536 个字符,这完全可以容纳全世界所有语言文字的编码。在Unicode 里,所有的字符都按一个字符来处理, 它们都有一个唯一的Unicode 码。
4.使用UNICODE的好处
使用Unicode 编码可以使您的工程同时支持多种语言, 使您的工程国际化。即在不同语言的系统下不至于产生乱码。
-
ASCII码与Unicode的区别2024-11-10 3552
-
unicode如何转GBK字库制作2023-08-14 1041
-
LED和OLED的区别是什么2022-01-14 18760
-
"stm32单片机平台上ASCII(GBK,GB2312)转unicode转UTF-8"2021-11-30 3102
-
cob光源和led的区别是什么2020-12-24 11391
-
从ASCII码->Unicode-> UTF-8历史变迁,及其差异2020-02-27 3905
-
ascii和utf8的区别_ASCII编码与UTF-8的关系2018-01-30 32705
-
Unicode编码介绍2011-04-18 2062
-
UNICODE,GBK,UTF-8区别2011-03-28 2904
-
ascii码表,ascii码对照表2009-06-30 15422
-
ascii码是什么,ascii码字符是什么2009-06-28 22026
-
汉字Unicode码生成软件2009-03-15 710
全部0条评论

快来发表一下你的评论吧 !
