

unicode与javascript详解
编程语言及工具
描述
Unicode是什么?
Unicode源于一个很简单的想法:将全世界所有的字符包含在一个集合里,计算机只要支持这一个字符集,就能显示所有的字符,再也不会有乱码了。

它从0开始,为每个符号指定一个编号,这叫做“码点”(code point)。比如,码点0的符号就是null(表示所有二进制位都是0)。
U+0000 = null
上式中,U+表示紧跟在后面的十六进制数是Unicode的码点。

目前,Unicode的最新版本是7.0版,一共收入了109449个符号,其中的中日韩文字为74500个。可以近似认为,全世界现有的符号当中,三分之二以上来自东亚文字。比如,中文“好”的码点是十六进制的597D。
U+597D = 好
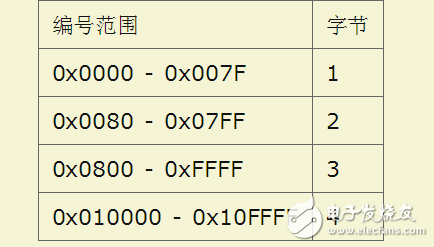
这么多符号,Unicode不是一次性定义的,而是分区定义。每个区可以存放65536个(216)字符,称为一个平面(plane)。目前,一共有17个(25)平面,也就是说,整个Unicode字符集的大小现在是221。
最前面的65536个字符位,称为基本平面(缩写BMP),它的码点范围是从0一直到216-1,写成16进制就是从U+0000到U+FFFF。所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
剩下的字符都放在辅助平面(缩写SMP),码点范围从U+010000一直到U+10FFFF。
javascript是什么?
JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML网页增加动态功能。
在1995年时,由Netscape公司的Brendan Eich,在网景导航者浏览器上首次设计实现而成。因为Netscape与Sun合作,Netscape管理层希望它外观看起来像Java,因此取名为JavaScript。但实际上它的语法风格与Self及Scheme较为接近。
为了取得技术优势,微软推出了JScript,CEnvi推出ScriptEase,与JavaScript同样可在浏览器上运行。为了统一规格,因为JavaScript兼容于ECMA标准,因此也称为ECMAScript。
UTF-32与UTF-8
Unicode只规定了每个字符的码点,到底用什么样的字节序表示这个码点,就涉及到编码方法。
最直观的编码方法是,每个码点使用四个字节表示,字节内容一一对应码点。这种编码方法就叫做UTF-32。比如,码点0就用四个字节的0表示,码点597D就在前面加两个字节的0。
U+0000 = 0x0000 0000
U+597D = 0x0000 597D

UTF-32的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
我们需要一种节省空间的表示法。
人们真正需要的是一种节省空间的编码方法,这导致了UTF-8的诞生。UTF-8是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同。
由于UTF-8这种节省空间的特性,导致它成为互联网上最常见的网页编码。
JavaScript使用哪一种编码?
JavaScript语言采用Unicode字符集,但是只支持一种编码方法。
这种编码既不是UTF-16,也不是UTF-8,更不是UTF-32。上面那些编码方法,JavaScript都不用。
JavaScript用的是UCS-2!
UCS-2编码
互联网还没出现的年代,曾经有两个团队,不约而同想搞统一字符集。一个是1988年成立的Unicode团队,另一个是1989年成立的UCS团队。等到他们发现了对方的存在,很快就达成一致:世界上不需要两套统一字符集。
1991年10月,两个团队决定合并字符集。也就是说,从今以后只发布一套字符集,就是Unicode,并且修订此前发布的字符集,UCS的码点将与Unicode完全一致。

UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是基本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即基本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。
两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2。
JavaScript的诞生背景
那么,为什么JavaScript不选择更高级的UTF-16,而用了已经被淘汰的UCS-2呢?
答案很简单:非不想也,是不能也。因为在JavaScript语言出现的时候,还没有UTF-16编码。
1995年5月,Brendan Eich用了10天设计了JavaScript语言;10月,第一个解释引擎问世;次年11月,Netscape正式向ECMA提交语言标准(整个过程详见《JavaScript诞生记》)。对比UTF-16的发布时间(1996年7月),就会明白Netscape公司那时没有其他选择,只有UCS-2一种编码方法可用!

JavaScript字符函数的局限
由于JavaScript只能处理UCS-2编码,造成所有字符在这门语言中都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。JavaScript的字符函数都受到这一点的影响,无法返回正确结果。

还是以字符为例,它的UTF-16编码是4个字节的0xD834 DF06。问题就来了,4个字节的编码不属于UCS-2,JavaScript不认识,只会把它看作单独的两个字符U+D834和U+DF06。前面说过,这两个码点是空的,所以JavaScript会认为是两个空字符组成的字符串!

上面代码表示,JavaScript认为字符的长度是2,取到的第一个字符是空字符,取到的第一个字符的码点是0xDB34。这些结果都不正确!
解决这个问题,必须对码点做一个判断,然后手动调整。下面是正确的遍历字符串的写法。
while (++index 《 length) {
// 。。。
if (charCode 》= 0xD800 && charCode 《= 0xDBFF) {
output.push(character + string.charAt(++index));
} else {
output.push(character);
}
}
上面代码表示,遍历字符串的时候,必须对码点做一个判断,只要落在0xD800到0xDBFF的区间,就要连同后面2个字节一起读取。
类似的问题存在于所有的JavaScript字符操作函数。
String.prototype.replace()
String.prototype.substring()
String.prototype.slice()
。。。
上面的函数都只对2字节的码点有效。要正确处理4字节的码点,就必须逐一部署自己的版本,判断一下当前字符的码点范围。
ECMAScript 6
JavaScript的下一个版本ECMAScript 6(简称ES6),大幅增强了Unicode支持,基本上解决了这个问题。
(1)正确识别字符
ES6可以自动识别4字节的码点。因此,遍历字符串就简单多了。
for (let s of string ) {
// 。。。
}
但是,为了保持兼容,length属性还是原来的行为方式。为了得到字符串的正确长度,可以用下面的方式。
Array.from(string).length
(2)码点表示法
JavaScript允许直接用码点表示Unicode字符,写法是“反斜杠+u+码点”。
‘好’ === ‘u597D’ // true
但是,这种表示法对4字节的码点无效。ES6修正了这个问题,只要将码点放在大括号内,就能正确识别。

(3)字符串处理函数
ES6新增了几个专门处理4字节码点的函数。
String.fromCodePoint():从Unicode码点返回对应字符
String.prototype.codePointAt():从字符返回对应的码点
String.prototype.at():返回字符串给定位置的字符
(4)正则表达式
ES6提供了u修饰符,对正则表达式添加4字节码点的支持。

(5)Unicode正规化
有些字符除了字母以外,还有附加符号。比如,汉语拼音的Ǒ,字母上面的声调就是附加符号。对于许多欧洲语言来说,声调符号是非常重要的。
Unicode提供了两种表示方法。一种是带附加符号的单个字符,即一个码点表示一个字符,比如Ǒ的码点是U+01D1;另一种是将附加符号单独作为一个码点,与主体字符复合显示,即两个码点表示一个字符,比如Ǒ可以写成O(U+004F) + ˇ(U+030C)。
// 方法一
‘u01D1’
// ‘Ǒ’
// 方法二
‘u004Fu030C’
// ‘Ǒ’
这两种表示方法,视觉和语义都完全一样,理应作为等同情况处理。但是,JavaScript无法辨别。
‘u01D1’===‘u004Fu030C’
//false
ES6提供了normalize方法,允许“Unicode正规化”,即将两种方法转为同样的序列。
‘u01D1’.normalize() === ‘u004Fu030C’.normalize()
// true
- 相关推荐
- 热点推荐
- javascript
- Unicode
-
javascript属于前端吗2023-12-03 2745
-
javascript:;怎么解决2023-11-26 11166
-
javascript怎么开启2023-11-16 4173
-
Openerp PyChart Unicode Report2022-04-18 678
-
JavaScript JavaScript是什么语言2021-07-27 7593
-
JavaScript 简介2020-09-09 2013
-
JavaScript语言基础2018-04-03 901
-
javascript应用程序经典实例详解2015-11-10 778
-
字符Unicode标准编码计算器免费下载2012-09-16 1527
-
Unicode编码介绍2011-04-18 2118
-
使用Java语言进行Unicode代理编程2010-11-25 1165
-
汉字Unicode码生成软件2009-03-15 736
-
JavaScript源码大全(CHM)2008-12-08 1751
-
JavaScript教程2008-10-21 6255
全部0条评论

快来发表一下你的评论吧 !
