

lms算法基本思想及原理
人工智能
描述
一、最小均方算法(LMS)概述
1959年,Widrow和Hoff在对自适应线性元素的方案一模式识别进行研究时,提出了最小均方算法(简称LMS算法)。LMS算法是基于维纳滤波,然后借助于最速下降算法发展起来的。通过维纳滤波所求解的维纳解,必须在已知输入信号与期望信号的先验统计信息,以及再对输入信号的自相关矩阵进行求逆运算的情况下才能得以确定。因此,这个维纳解仅仅是理论上的一种最优解。所以,又借助于最速下降算法,以递归的方式来逼近这个维纳解,从而避免了矩阵求逆运算,但仍然需要信号的先验信息,故而再使用瞬时误差的平方来代替均方误差,从而最终得出了LMS算法。
因LMS算法具有计算复杂程度低、在信号为平稳信号的环境中的收敛性好、其期望值无偏地收敛到维纳解和利用有限精度实现算法时的稳定性等特性,使LMS算法成为自适应算法中稳定性最好、应用最广泛的算法。
下图是实现算法的一个矢量信号流程图:
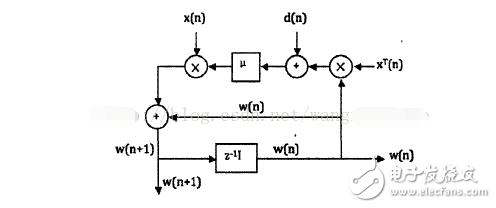
图1 LMS算法矢量信号流程图
由图1我们可以知道,LMS算法主要包含两个过程:滤波处理和自适应调整。
一般情况下,LMS算法的具体流程为:
(1)确定参数:全局步长参数β以及滤波器的抽头数(也可以称为滤波器阶数)
(2)对滤波器初始值的初始化
(3)算法运算过程:
滤波输出:y(n)=wT(n)x(n)
误差信号:e(n)=d(n)-y(n)
权系数更新:w(n+1)=w(n)+βe(n)x(n)
二、性能分析
在很大程度上,选取怎样的自适应算法决定着自适应滤波器是否具有好的性能。因此,对应用最为广泛的算法算法进行性能分析则显得尤为重要。平稳环境下算法的主要性能指标有收敛性、收敛速度、稳态误差和计算复杂度等。
1、收敛性
收敛性就是指,当迭代次数趋向于无穷时,滤波器权矢量将达到最优值或处于其附近很小的邻域内,或者可以说在满足一定的收敛条件下,滤波器权矢量最终趋近于最优值。
2、收敛速度
收敛速度是指滤波器权矢量从最初的初始值向其最优解收敛的快慢程度,它是判断LMS算法性能好坏的一个重要指标。
3、稳态误差
稳态误差,是指当算法进入稳态后滤波器系数与最优解之间距离的远近情况。它也是一个衡量LMS算法性能好坏的重要指标。
4、计算复杂度
计算复杂度,是指在更新一次滤波器权系数时所需的计算量。LMS算法的计算复杂度还是很低的,这也是它的一大特点。
三、LMS算法分类
1、量化误差LMS算法
在回声消除和信道均衡等需要自适应滤波器高速工作的应用中,降低计算复杂度是很重要的。LMS算法的计算复杂度主要来自在进行数据更新时的乘法运算以及对自适应滤波器输出的计算,量化误差算法就是一种降低计算复杂度的方法。其基本思想是对误差信号进行量化。常见的有符号误差LMS算法和符号数据LMS算法。
2、解相关LMS算法
在LMS算法中,有一个独立性假设横向滤波器的输入u(1),u(2),…, u(n-1)是彼此统计独立的向量序列。当它们之间不满足统计独立的条件时,基本LMS算法的性能将下降,尤其是收敛速度会比较慢。为解决此问题,提出了解相关算法。研究表明,解相关能够有效加快LMS算法的收敛速度。解相关LMS算法又分为时域解相关LMS算法和变换域解相关LMS算法。
3、并行延时LMS算法
在自适应算法的实现结构中,有一类面向VLSI的脉动结构,由于其具有的高度并行性和流水线特性而备受关注。将算法直接映射到脉动结构时,在权值更新和误差计算中存在着严重的计算瓶颈。该算法解决了算法到结构的计算瓶颈问题,但当滤波器阶数较长时,算法的收敛性能会变差,这是由于其本身所具有的延时影响了它的收敛性能。可以说,延时算法是以牺牲算法的收敛性能为代价的。
4、自适应格型LMS算法
LMS滤波器属于横向自适应滤波器且假定阶数固定,然而在实际应用中,横向滤波器的最优阶数往往是未知的,需要通过比较不同阶数的滤波器来确定最优的阶数。当改变横向滤波器的阶数时,LMS算法必须重新运行,这显然不方便而且费时。格型滤波器解决了这一问题。
格型滤波器具有共轭对称的结构,前向反射系数是后向反射系数的共轭,其设计准则和LMS算法一样是使均方误差最小。
5、Newton-LMS算法
Newton-LMS算法是对环境信号二阶统计量进行估计的算法。其目的是为了解决输入信号相关性很高时算法收敛速度慢的问题。一般情况下,牛顿算法能够快速收敛,但对R-1的估计所需计算量很大,而且存在数值不稳定的问题。
四、LMS算法基本原理
根据小均方误差准则以及均方误差曲面,自然的我们会想到沿每一时刻均方误差 的陡下降在权向量面上的投影方向更新,也就是通过目标函数k反梯度向量来反 复迭代更新。由于均方误差性能曲面只有一个唯一的极小值,只要收敛步长选择恰当, 不管初始权向量在哪,后都可以收敛到误差曲面的小点,或者是在它的一个邻域内。 这种沿目标函数梯度反方向来解决小化问题的方法,我们一般称为速下降法,表达式如下:
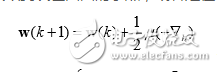
基于随机梯度算法的小均方 自适应滤波算法的完整表达式如下:
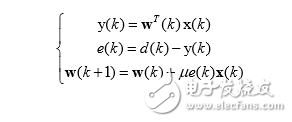
LMS 自适应算法是一种特殊的梯度估计,不必重复使用数据,也不必对相关矩阵 和互相关矩阵 进行运算,只需要在每次迭代时利用输入向量和期望响应,结构简单, 易于实现。虽然 LMS 收敛速度较慢,但在解决许多实际中的信号处理问题,LMS 算法 是仍然是好的选择。
3 LMS算法性能分析
随机梯度 LMS 算法的性能前人有过大量研究,按照前一章所提到的自适应滤波性能 指标,假设输入信号和期望信号具有联合平稳性,详细讨论基于横向 FIR 结构的滤波器 的标准 LMS 算法的四个性能:一、收敛性;二、收敛速度;三、稳态误差;四、计算复 杂度。 只有在输入信号具有严格稳定的统计特性时,权向量的优解是不变的。否则, 将会随着统计特性的变化而变化。自适应算法则能够通过不断的调整滤波器权向量,使权向量接近优解 。因此,自适应算法在平稳条件下的性能表现可以认为是非平稳条件下的一种特殊情况。如果在平稳条件下,自适应算法能够快 速,平稳的逼近权向量的优值,那么在非平稳条件下,该算法也能很好的逼近时变的 权向量优解。
五、算法流程
下面介绍一下LMS算法的基本流程。
1. 初始化工作,为各个输入端的权值覆上随机初始值;
2. 随机挑选一组训练数据,进行计算得出计算结构C;
3. 利用公式3对每一个输入端的权值进行调整;
4. 利用公式1计算出均方差MSE;
5. 对均方差进行判断,如果大于某一个给定值,回到步骤2,继续算法;如果小于给定值,就输出正确权值,并结束算法。
六、算法实现
以下就给出一段LMS算法的代码。
[cpp] view plain copyconst unsigned int nTests =4;
const unsigned int nInputs =2;
const double rho =0.005;
struct lms_testdata
{
doubleinputs[nInputs];
doubleoutput;
};
double compute_output(constdouble * inputs,double* weights)
{
double sum =0.0;
for (int i = 0 ; i 《 nInputs; ++i)
{
sum += weights[i]*inputs[i];
}
//bias
sum += weights[nInputs]*1.0;
return sum;
}
//计算均方差
double caculate_mse(constlms_testdata * testdata,double * weights)
{
double sum =0.0;
for (int i = 0 ; i 《 nTests ; ++i)
{
sum += pow(testdata[i].output -compute_output(testdata[i].inputs,weights),2);
}
return sum/(double)nTests;
}
//对计算所得值,进行分类
int classify_output(doubleoutput)
{
if(output》 0.0)
return1;
else
return-1;
}
int _tmain(int argc,_TCHAR* argv[])
{
lms_testdata testdata[nTests] = {
{-1.0,-1.0, -1.0},
{-1.0, 1.0, -1.0},
{ 1.0,-1.0, -1.0},
{ 1.0, 1.0, 1.0}
};
doubleweights[nInputs + 1] = {0.0};
while(caculate_mse(testdata,weights)》 0.26)//计算均方差,如果大于给定值,算法继续
{
intiTest = rand()%nTests;//随机选择一组数据
doubleoutput = compute_output(testdata[iTest].inputs,weights);
doubleerr = testdata[iTest].output - output;
//调整输入端的权值
for (int i = 0 ; i 《 nInputs ; ++i)
{
weights[i] = weights[i] + rho * err* testdata[iTest].inputs[i];
}
weights[nInputs] = weights[nInputs] +rho * err;
cout《《“mse:”《《caculate_mse(testdata,weights)《《endl;
}
for(int w = 0 ; w 《 nInputs + 1 ; ++w)
{
cout《《“weight”《《w《《“:”《《weights[w]《《endl;
}
cout《《“\n”;
for (int i = 0 ;i 《 nTests ; ++i)
{
cout《《“rightresult:êo”《《testdata[i].output《《“\t”;
cout《《“caculateresult:” 《《 classify_output(compute_output(testdata[i].inputs,weights))《《endl;
}
//
char temp ;
cin》》temp;
return 0;
}
- 相关推荐
- 热点推荐
- LMS算法
-
设计的基本思想,就是尽可能利用“芯片”性能2017-06-20 1813
-
变步长LMS自适应滤波算法及其分析2010-04-26 3690
-
求lms算法的程序2012-05-02 3417
-
基于matlab的LMS算法实用小程序2012-09-05 8345
-
计算机解题的基本思想方法和步骤2020-11-02 1457
-
PID控制算法的基本思想是什么?PID控制算法是如何形成的?2021-06-30 3571
-
Matlab-LMS算法演示2021-08-17 2173
-
PID控制算法的基本思想是什么2021-12-21 1410
-
新的变步长LMS算法及DSP设计2010-05-14 3098
-
FDTD算法基本思想2010-08-13 11517
-
图像处理基本思想和算法研究2018-01-12 2627
-
基于FPGA的定点LMS算法的实现讲解2021-04-28 1178
-
基于FPGA的自适应LMS算法的实现2021-05-28 1483
-
浮点LMS算法的FPGA实现2023-12-21 2138
-
信号分析的基本思想是什么2024-06-03 2264
全部0条评论

快来发表一下你的评论吧 !
