

自适应滤波算法理解与应用
人工智能
描述
什么是自适应滤波器
自适应滤波器是能够根据输入信号自动调整性能进行数字信号处理的数字滤波器。作为对比,非自适应滤波器有静态的滤波器系数,这些静态系数一起组成传递函数。
对于一些应用来说,由于事先并不知道所需要进行操作的参数,例如一些噪声信号的特性,所以要求使用自适应的系数进行处理。在这种情况下,通常使用自适应滤波器,自适应滤波器使用反馈来调整滤波器系数以及频率响应。
总的来说,自适应的过程涉及到将代价函数用于确定如何更改滤波器系数从而减小下一次迭代过程成本的算法。价值函数是滤波器最佳性能的判断准则,比如减小输入信号中的噪声成分的能力。
随着数字信号处理器性能的增强,自适应滤波器的应用越来越常见,时至今日它们已经广泛地用于手机以及其它通信设备、数码录像机和数码照相机以及医疗监测设备中。
下面图示的框图是最小均方滤波器(LMS)和递归最小平方(en:Recursive least squares filter,RLS,即我们平时说的最小二乘法)这些特殊自适应滤波器实现的基础。框图的理论基础是可变滤波器能够得到所要信号的估计。
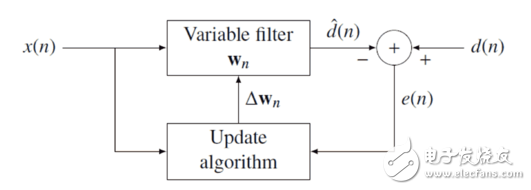
自适应滤波器有4种基本应用类型:
1) 系统辨识:这时参考信号就是未知系统的输出,当误差最小时,此时自适应滤波器就与未知系统具有相近的特性,自适应滤波器用来提供一个在某种意义上能够最好拟合未知装置的线性模型
2) 逆模型:在这类应用中,自适应滤波器的作用是提供一个逆模型,该模型可在某种意义上最好拟合未知噪声装置。理想地,在线性系统的情况下,该逆模型具有等于未知装置转移函数倒数的转移函数,使得二者的组合构成一个理想的传输媒介。该系统输入的延迟构成自适应滤波器的期望响应。在某些应用中,该系统输入不加延迟地用做期望响应。
3) 预测:在这类应用中,自适应滤波器的作用是对随机信号的当前值提供某种意义上的一个最好预测。于是,信号的当前值用作自适应滤波器的期望响应。信号的过去值加到滤波器的输入端。取决于感兴趣的应用,自适应滤波器的输出或估计误差均可作为系统的输出。在第一种情况下,系统作为一个预测器;而在后一种情况下,系统作为预测误差滤波器。
4) 干扰消除:在一类应用中,自适应滤波器以某种意义上的最优化方式消除包含在基本信号中的未知干扰。基本信号用作自适应滤波器的期望响应,参考信号用作滤波器的输入。参考信号来自定位的某一传感器或一组传感器,并以承载新息的信号是微弱的或基本不可预测的方式,供给基本信号上。
这也就是说,得到期望输出往往不是引入自适应滤波器的目的,引入它的目的是得到未知系统模型、得到未知信道的传递函数的倒数、得到未来信号或误差和得到消除干扰的原信号。
自适应滤波通俗点讲就是混合信号向期望信号的逼近。在逼近的过程中,根据观测信号与真实(期望)信号的均放误差(MSE)为量化指标,按照一定规则进行迭代(迭代规则自己可以设定),直到算法收敛(收敛条件有很多,比如达到预先设定的迭代次数、或达到允许的误差等)。现有的常见自适应算法有RLS,LMS,NLMS,往往都是按照梯度下降法或牛顿法进行迭代。
算法背景
经典的滤波算法包括维纳滤波,卡尔曼滤波,这些滤波算法都需要对输入信号的相关系数,噪声功率等参数进行估计,而实际中很难实现这些参数的准确估计,而这些参数的准确估计直接影响到滤波器的滤波效果。另一方面,这两类滤波器一般设计完成,参数便不可改变,实际应用中,希望滤波器的参数能够随着输入信号的变化而改变,以取得较好的实时性处理效果。为了弥补传统滤波算法的不足,满足信号处理的要求,又发展了自适应滤波。
算法基本原理
自适应滤波与维纳滤波,卡尔曼滤波最大的区别在于,自适应滤波在输出与滤波系统之间存在有反馈通道,根据某一时刻滤波器的输出与期望信号的误差调整滤波器的系数,从而实现滤波器系数的动态调整,实现最优滤波。
(1)信号模型
自适应滤波的目的仍然是从观测信号中提取真实准确的期望信号,因此涉及到的信号有:
期望信号 d(n)
输入信号 x(n)=d(n)+v(n)
输出信号 y(n)
(2)算法原理
一个M阶滤波器,系数为w(m),则输出为:
y(n)=Σw(m)x(n-m) m=0…M
写成矩阵形式: y(j)=WT(j)*X(j)
n时刻的输出误差为: e(j)=d(j)-y(j)= d(j)- WT(j)*X(j)
定义目标函数为 E[e(j)^2],则有:
J(j)=E[e(j)^2]= E[(d(j)- WT(j)*X(j))^2]
当上述误差达到最小时,即实现最优滤波,这种目标函数确定的为最小方差自适应滤波。
对于目标函数J(j),需要求得使其取到最小值对应的W,这里使用梯度下降法进行最优化:
W(j+1)=W(j)+1/2*μ(-▽J(j))
▽J(j)=-2E[X(j)*( d(j)- WT(j)*X(j))]= -2E[X(j)e(j)]
W(j+1)=W(j)+μE[X(j)e(j)]
其中-2X(j)e(j)称为瞬时梯度,因为瞬时梯度是真实梯度的无偏估计,这里可以使用瞬时梯度代替真实梯度。
W(j+1)=W(j)+μX(j)e(j)
由此,可以得到自适应滤波最佳系数的迭代公式。
3.算法的收敛性
在最小均方误差自适应滤波算法中,最佳滤波器系数应该满足:
▽J(j)=0
即:-2E[X(j)*( d(j)- WT(j)*X(j))]=0
经整理后,可以得到:
WoptT =Rxx-1*Rxd
上式说明,自适应滤波的最佳滤波器系数同维纳滤波相同,与输入信号以及期望信号的相关矩阵有关。
对W(j+1)=W(j)+μX(j)e(j)等号两边求期望,并通过一系列推导,可得:
E[W(j+1)]=Wopt+Q(I-μΛ)jQH(W0-Wopt)
式中Rxx=QHΛQ, W0为自适应滤波系数的初值。
当j取到无穷大时,滤波器应达到最优状态,因此:
(I-μΛ)j=0,则有:|I-μΛ|《=1
上式即为最小均方自适应滤波的收敛条件。
Λ为输入信号的自相关矩阵Rxx的特征值构成的对角阵。
4.变步长自适应滤波算法
在整个迭代过程中,步长不变的情况称为定步长算法。为了保证算法的收敛性,一般要取一个比较小的步长值,但步长过小又容易导致算法收敛过慢。比较理想的情况是,在迭代的初始阶段,误差值较大时,取一个较大的迭代步长,以实现较快的收敛速度;随着迭代次数增加,误差逐渐减小,步长也应相应减小,达到较高的收敛精度。这种思想便称为变步长自适应滤波算法。
常用的变步长自适应滤波算法根据输入信号的或者误差值确定步长。
这里介绍两种具体的变步长算法:
(1)归一化变步长自适应滤波算法
μj =α/(β+XjTXj)
α,β均为常数,且满足0《α《2,β》=0。
该算法使用输入信号的能量对步长因子进行归一化,确保其取到合适的值。
(2)Sigmod函数变步长自适应滤波算法
μj=β(1-exp(-αej^2))
α,β均为常数,且满足0《α,0=《β《μmax。
从上述表达式中可以明显看出,随着误差增大,步长值也增大。
5.解相关自适应滤波算法
实验发现,当输入信号之间的相关性比较强时,自适应滤波的效果比较差。因此需要去除相邻两次输入信号序列的相关性,以得到较好的滤波效果。
解相关自适应滤波算法的实现过程为:
r= XjTXj-1/ Xj-1TXj-1
Zj=Xj-rXj-1
μj=βej/ ZjTXj
Wj+1=Wj+μjZj
6.变换域自适应滤波算法
根据解相关自适应滤波算法的思想,使用一组正交基对输入信号进行变换,在变换域上进行自适应滤波,最后再将滤波结果逆变换至时间域。常见的变换有傅里叶变换,分数阶傅里叶变换,小波变换,余弦变换。
算法应用与实现
下面讲述如何在实际问题中应用自适应滤波算法:
问题背景:一个点目标在x,y平面上绕单位圆做圆周运动,由于外界干扰,其运动轨迹发生了偏移。其中,x方向的干扰为均值为0,方差为0.05的高斯噪声;y方向干扰为均值为0,方差为0.06的高斯噪声。
问题分析与思路:
将物体的运动轨迹分解为X方向和Y方向,并假设两个方向上运动相互独立。分别将运动轨迹离散为一系列点,作为滤波器的输入,分别在两个方向上进行滤波,最终再合成运动轨迹。
程序设计思路:
生成期望信号-添加噪声-设置滤波器系数初值-迭代运算-最优滤波输出
滤波结果分析:
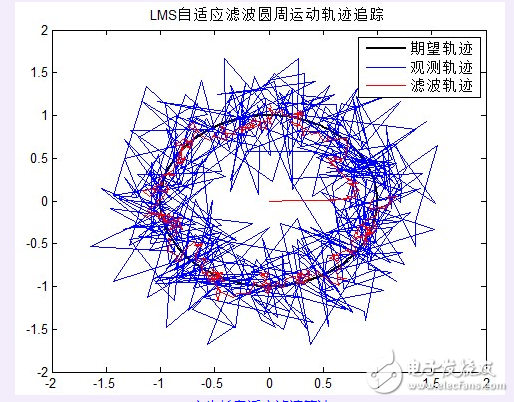
定步长自适应滤波算法
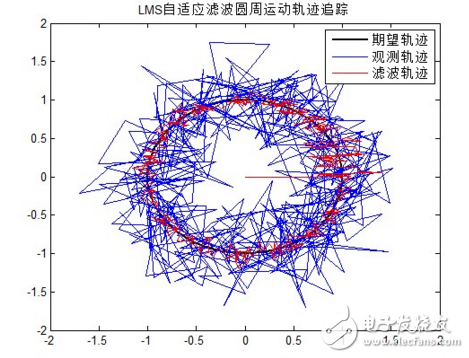
变步长自适应滤波算法
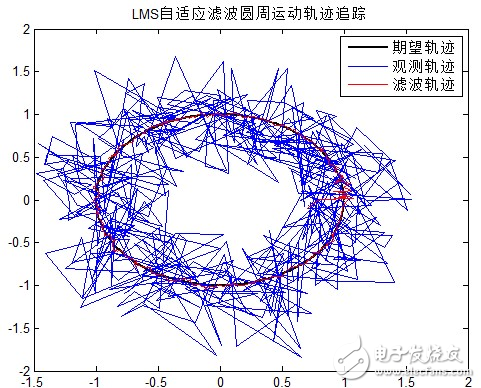
解相关自适应滤波算法
- 相关推荐
- 热点推荐
- 滤波算法
-
如何实现基于四阶累积量的自适应均值滤波算法?2021-04-14 1827
-
自适应滤波算法与实现的PDF电子书免费下载2020-07-10 2966
-
matlab实现的自适应滤波算法2017-12-14 38113
-
改进的自适应加权中值滤波算法_王松林2017-03-19 1014
-
变阶自适应滤波器及其算法研究2017-01-08 931
-
一种变阶数自适应滤波算法2017-01-03 866
-
自适应滤波算法2016-01-15 904
-
一种改进的自适应中值滤波算法2015-11-20 786
-
LMS自适应滤波算法中参考信号的选取问题2013-05-21 5372
-
基于LMS算法与RLS算法的自适应滤波2012-07-06 2738
-
改进的变阶数LMS自适应滤波算法2010-05-13 3780
-
变步长LMS自适应滤波算法及其分析2010-04-26 3555
-
基于AccelDSP的自适应滤波器设计2010-04-24 3176
全部0条评论

快来发表一下你的评论吧 !
