

深度学习框架Keras代码解析
人工智能
描述
总体来讲keras这个深度学习框架真的很“简易”,它体现在可参考的文档写的比较详细,不像caffe,装完以后都得靠技术博客,keras有它自己的官方文档(不过是英文的),这给初学者提供了很大的学习空间。
这个文档必须要强推!英文nice的可以直接看文档,我这篇文章就是用中文来讲这个事儿。
Keras官方文档
首先要明确一点:我没学过Python,写代码都是需要什么百度什么的,所以有时候代码会比较冗余,可能一句话就能搞定的能写很多~
论文引用——3.2 测试平台
项目代码是在Windows 7上运行的,主要用到的Matlab R2013a和Python,其中Matlab用于patch的分割和预处理,卷积神经网络搭建用到了根植于Python和Theano的深度学习框架Keras。Keras是基于Theano的一个深度学习框架,它的设计参考了Torch,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU,用起来特别简单,适合快速开发。
参考资料
基于Theano的深度学习(Deep Learning)框架Keras学习随笔-12-核心层
基于Theano的深度学习(Deep Learning)框架Keras学习随笔-13-卷积层
1. 直接上卷积神经网络构建的主函数
def create_model(data):
model = Sequential()
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’, input_shape=data.shape[-3:]))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Convolution2D(32, 3, 3, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3, border_mode=‘valid’))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512, init=‘normal’))
model.add(Activation(‘relu’))
model.add(Dropout(0.5))
model.add(Dense(LABELTYPE, init=‘normal’))
model.add(Activation(‘softmax’))
sgd = SGD(l2=0.0, lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=‘categorical_crossentropy’, optimizer=sgd, class_mode=“categorical”)
return model
这个函数相当的简洁清楚了,输入训练集,输出一个空的神经网络,其实就是卷积神经网络的初始化。model = Sequential()是给神经网络起了头,后面的model.add()是一直加层,像搭积木一样,要什么加什么,卷积神经网络有两种类型的层:1)卷积,2)降采样,对应到代码上是:
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’))
# 加一个卷积层,卷积个数64,卷积尺寸5*5
model.add(MaxPooling2D(pool_size=(2, 2)))
# 加一个降采样层,采样窗口尺寸2*2
1.1 激活函数
注意:每个卷积层后面要加一个激活函数,就是在教科书上说的这个部分
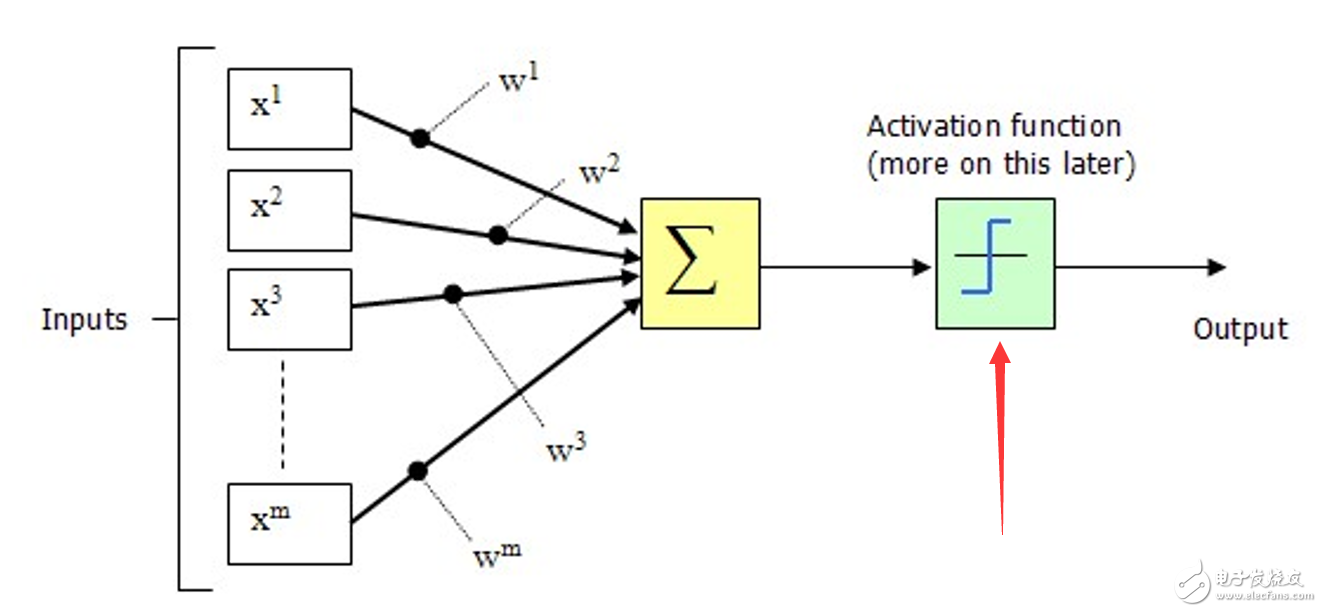
它可以将卷积后的结果控制在某一个数值范围内,如0~1,-1~1等等,不会让每次卷积完的数值相差悬殊
对应到代码上是这句:
model.add(Activation(‘relu’))
这个激活函数(Activation)keras提供了很多备选的,我这儿用的是ReLU这个,其他还有
tanh
sigmoid
hard_sigmoid
linear
等等,keras库是不断更新的,新出来的论文里面用到的更优化的激活函数里面也会有收录,比如:
LeakyReLU
PReLU
ELU
等等,都是可以替换的,美其名曰“优化网络”,其实就只不过是改一下名字罢了哈哈,内部函数已经都帮你写好了呢。注意一下:卷积神经网络的最后一层的激活函数一般就是选择“softmax”。我这儿多说一嘴这些激活函数应该怎么去选择吧,一句话

参考的是这篇文章
原因分别是
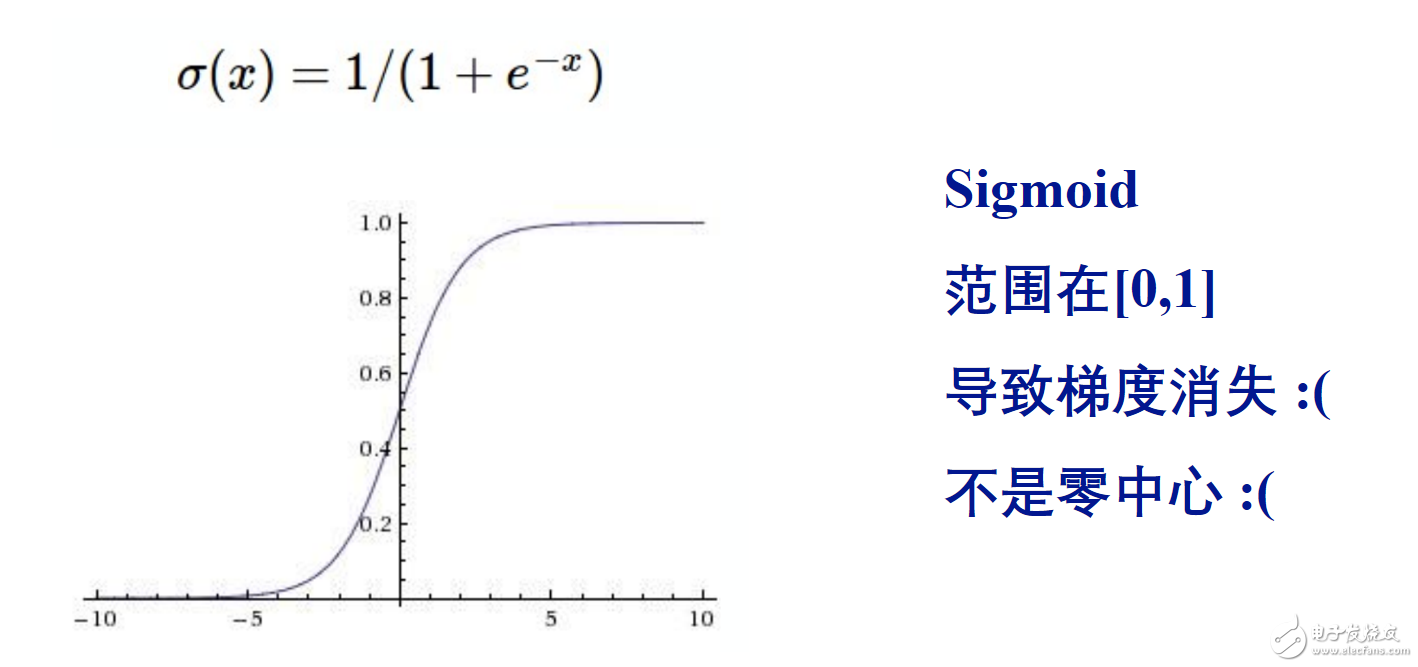
导致梯度消失,不是零中心
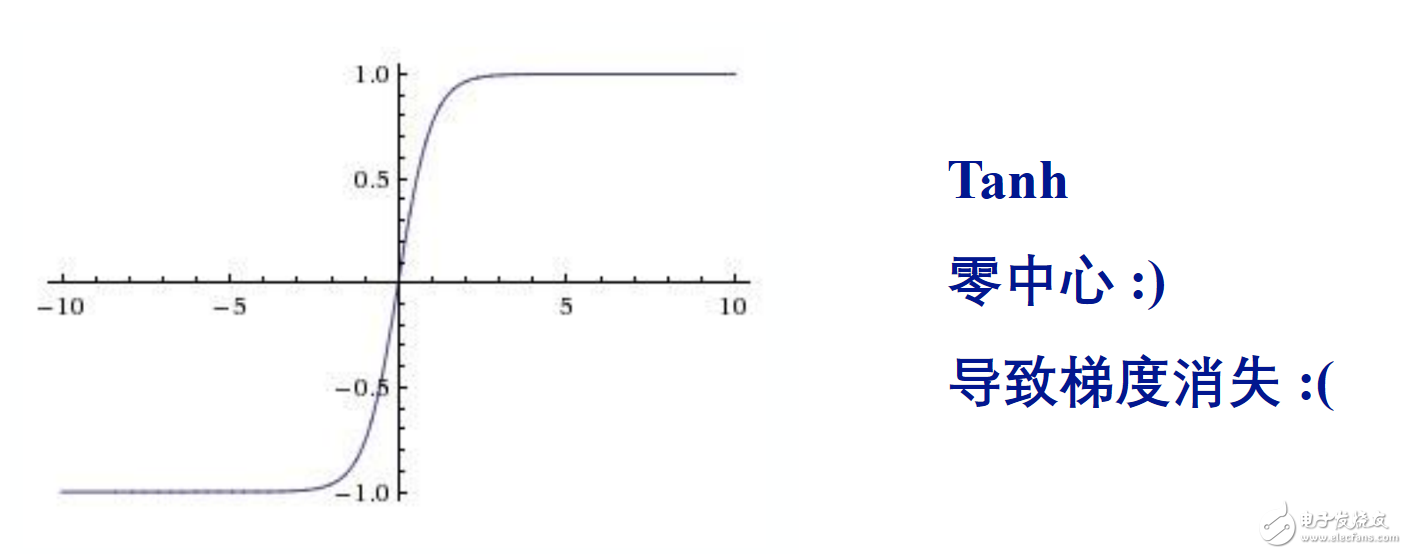
导致梯度消失
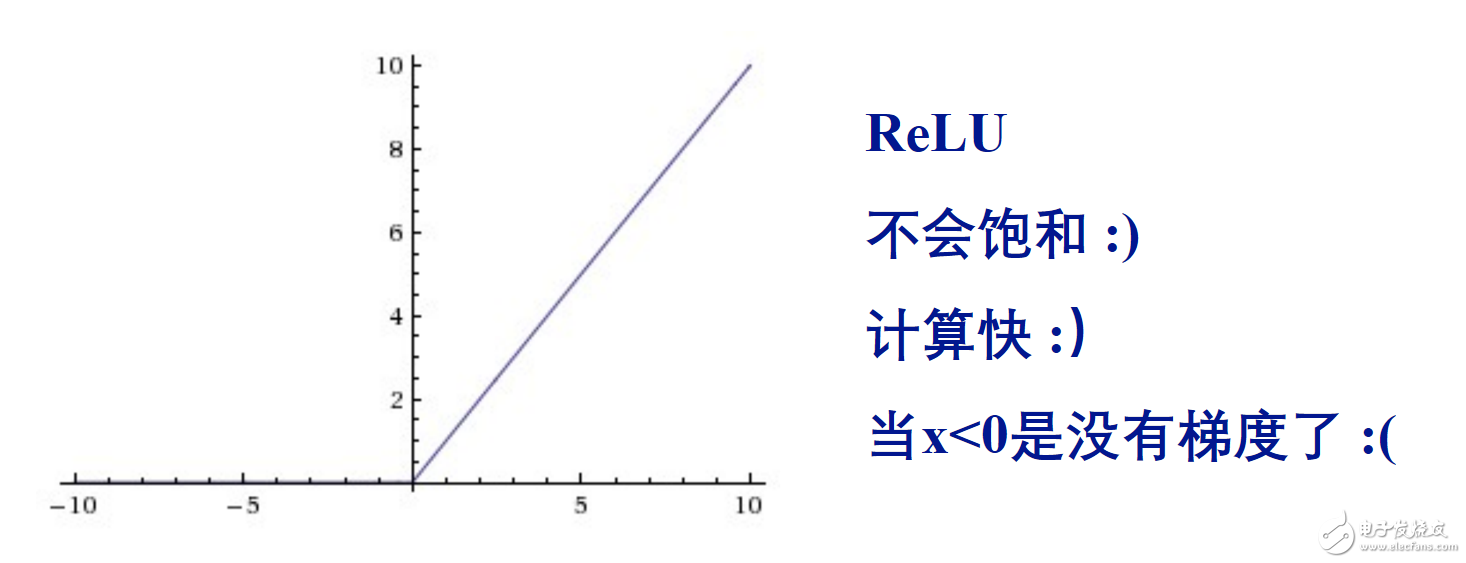
x《0时梯度没了
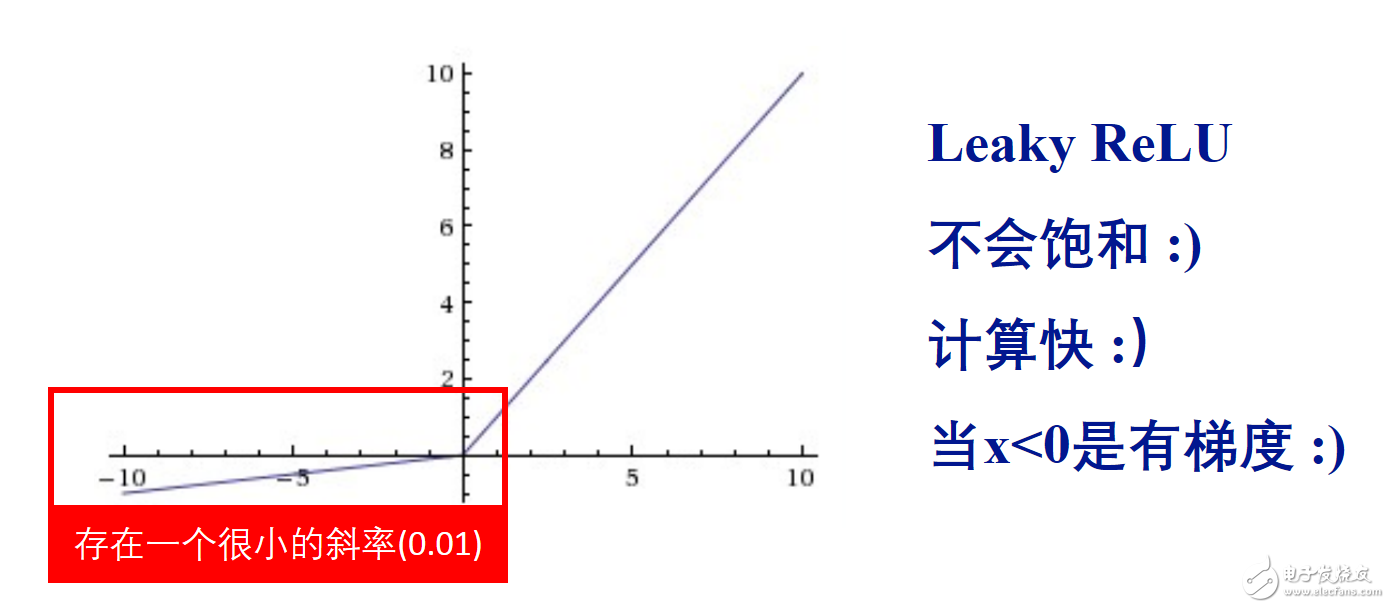
我知道Leaky ReLU已经有现成的了,但是暂时还没有用,现在还用的是ReLU这个,别问我为什么:)
1.2 Dropout层
弃权(Dropout):针对“过度拟合”问题
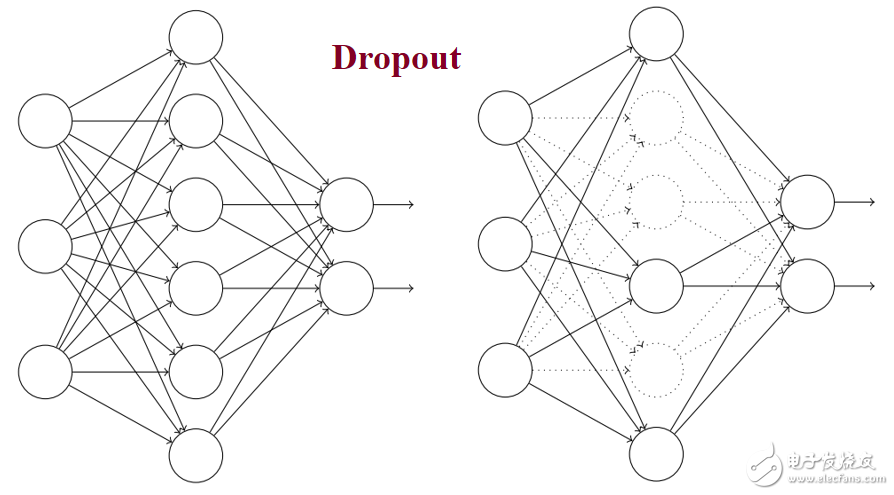
不让某些神经元兴奋
人脑在处理信号的时候并不是所有的神经元都处于兴奋状态的,原因是1) 大脑的能量供给跟不上,2)神经元的特异性,特定的神经元处理特定信号,3) 全部的神经元都激活的话增加了反应时间。所以我们用神经网络模拟的也要有所取舍,比如把信号强度低于某个值的神经元都抑制下来,这样能提高了网络的速度和鲁棒性,降低“过拟合”的可能性。额,废话不说了,反正就是好!体现在代码上是这个:
model.add(Dropout(0.5))
这个0.5可以改,意思是信号强度排在后50%的神经元都被抑制,就是把他们都扔掉~
1.3 还有点细节
到现在为止对这个网络初始化的函数应该只有一些小东西不清楚了吧:
model.add(Convolution2D(64, 5, 5, border_mode=‘valid’, input_shape=data.shape[-3:]))
你会发现第一个卷积层代码比其他的长,原因是它还需要加上训练集的一些参数,也就是input_shape = data.shape[-3:]这个,它的意思是说明一下训练集的样本有几个通道和每个输入图像的尺寸,我这儿是
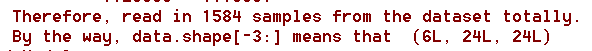
data.shape[-3:],表示我用了六通道,每个patch的尺寸是24*24像素。
通道的概念就是比如一幅黑白图,就是一通道,即灰度值;一幅彩色图就是三通道,即RGB;当然也可以不用颜色作为通道,比如我用的六通道。但是通道内部的机制我并不是很清楚,可能它就是为RGB设置的也说不定。这儿打一个问号?
model.add(Flatten())
model.add(Dense(512, init=‘normal’))
这儿加个一个全连接层,就是这两句代码,相当于卷积神经网络中的这个
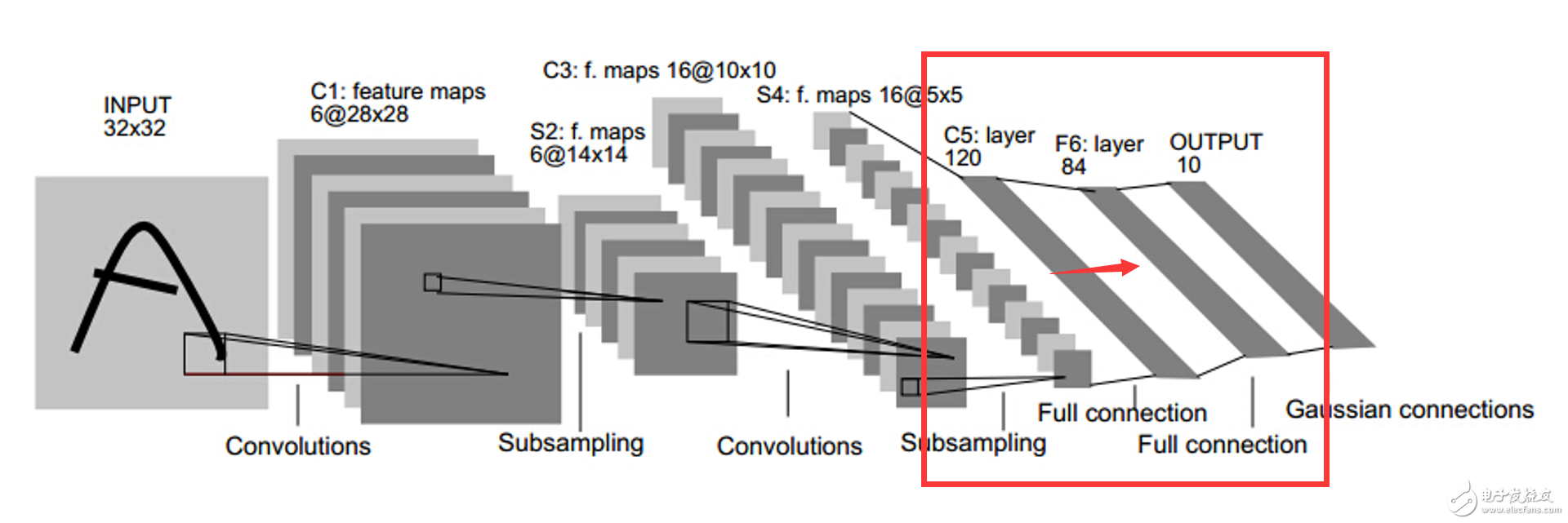
512意思就是这个层有512个神经元
没什么可说的,就是模型里的一部分,可以有好几层,但一般放在网络靠后的地方。
sgd = SGD(l2=0.0, lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=‘categorical_crossentropy’, optimizer=sgd, class_mode=“categorical”)
这部分就是传说中的“梯度下降法”,它用在神经网络的反馈阶段,不断地学习,调整每一层卷积的参数,即所谓“学习”的过程。我这儿用的是最常见的sgd,参数包括学习速度(lr),,虽然吧其他的参数理论上也能改,但是我没有去改它们,呵呵。
小建议:学习参数一般比较小,我用的是0.01,这个是根据不同的训练集数据决定的,太小的话训练的速度很慢,太大的话容易训练自爆掉,像这样
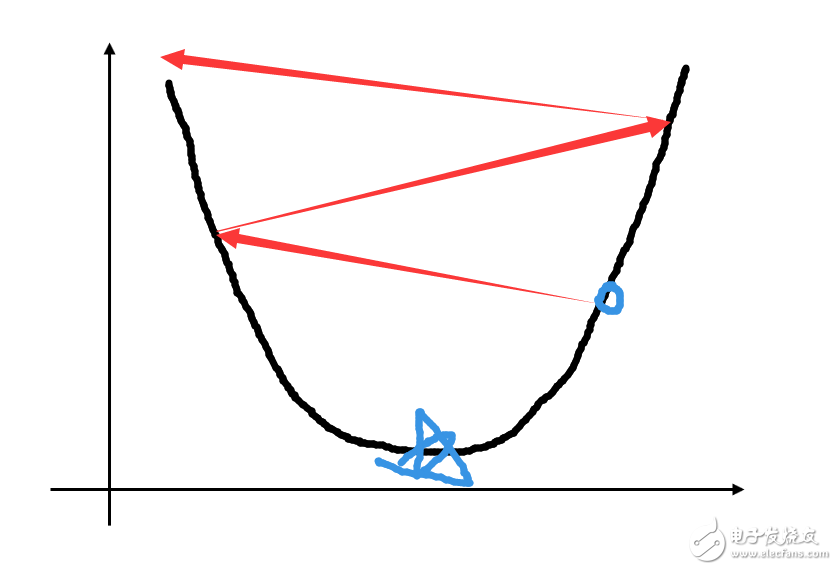
圆圈是当前位置,五角星是目标位置,若学习速度过快容易直接跳过目标位置,导致训练失败
对于keras提供的其他反馈的方法(Optimizer),我并没有试过,也不清楚它们各自的优缺点,这儿列举几个其他的可选方法:
RMSprop
Adagrad
Adadelta
Adam
Adamax
等等,我猜每一个方法都能对应一篇深度学习的论文吧,代码keras已经都提供了,想了解详情就去追溯论文吧。这儿我提一嘴代价函数的事儿,针对“学习缓慢”和“过渡拟合”问题,有提出对代价函数进行修改的方法。道理都懂,具体在keras的哪儿做修改我还在摸索中,先来讲一波道理:

由此可见,比较好的代价函数是
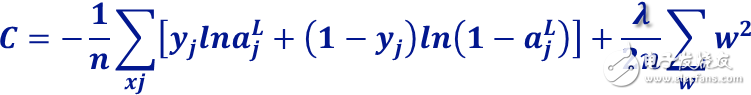
找机会把keras内部这一部分的代码改了
主代码部分,The End
2. 训练前期代码
在开始训练以前需要做几个步骤
导入需要的python包
导入数据
瓜分训练集和测试集
2.1 相关的python包导入
#coding:utf-8
‘’‘
GPU run command:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python cnn.py
CPU run command:
python cnn.py
’‘’
######################################
# 导入各种用到的模块组件
######################################
# ConvNets的模块
from __future__ import absolute_import
from __future__ import print_function
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.advanced_activations import PReLU, LeakyReLU
import keras.layers.advanced_activations as adact
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax
from keras.utils import np_utils, generic_utils
from six.moves import range
from keras.callbacks import EarlyStopping
# 统计的模块
from collections import Counter
import random, cPickle
from cutslice3d import load_data
from cutslice3d import ROW, COL, LABELTYPE, CHANNEL
# 内存调整的模块
import sys
这儿就没的说了,相当于C语言里面的#include,后面要用到什么就导入什么。对了具体导入哪些包就是去keras安装的位置看看,我的安装路径是
C:UsersAdministratorAnaconda2Libsite-packageskeras
你会看到一个个的.py文件
keras目录下就这样子的
比如你需要导入Sequential()这个函数的话首先得知道它在keras的models.py中定义的,然后就很自然的出来这个代码
from keras.models import Sequential
# 从keras的models.py中导入Sequential。
你看,代码简单的都能直译了。难点是你根本不知道Sequential()函数在哪儿定义的,这个就需要好好地去系统得看一下keras的文档了,这么多函数我这儿也不可能逐一举例。
这部分我个人感觉挺需要python的知识,因为除去keras,很多包都蛮有用的,有了这些函数能省不少事儿。举例:
from collections import Counter
作用是统计一个矩阵里面的不同元素分别出现的次数,落实到后面的代码就是
cnt = Counter(A)
for k,v in cnt.iteritems():
print (‘\t’, k, ‘--》’, v)
# 实现了统计A矩阵的元素各自出现的次数
2.2 数据的简单处理模块
######################################
# 对于本次试验的描述
######################################
print(“\n\n\nHey you, this is a trial on malignance and benign tumors detection via ConvNets. I‘m Zongwei Zhou. :)”)
print(“Each input patch is 51*51, cutted from 1383 3d CT & PT images. The MINIMUM is above 30 segment pixels.”)
######################################
# 加载数据
######################################
print(“》》 Loading Data 。。.”)
TrData, TrLabel, VaData, VaLabel = load_data()
######################################
# 打乱数据
######################################
index = [i for i in range(len(TrLabel))]
random.shuffle(index)
TrData = TrData[index]
TrLabel = TrLabel[index]
print(’\tTherefore, read in‘, TrData.shape[0], ’samples from the dataset totally.‘)
# label为0~1共2个类别,keras要求格式为binary class matrices,转化一下,直接调用keras提供的这个函数
TrLabel = np_utils.to_categorical(TrLabel, LABELTYPE)
这儿我用到了一个load_data()函数,是自己写的,就是一个数据导入,从.mat文件中分别读入训练集和测试集。也就是对于输入patch的平移,旋转变换以及训练集测试集划分都是在MATLAB中完成的,得到的数据量爆大,截止到4月7日,我的训练集以及达到了31.4GB的规模,而python端的函数就比较直观了,是这样的
def load_data():
######################################
# 从.mat文件中读入数据
######################################
mat_training = h5py.File(DATAPATH_Training);
mat_training.keys()
Training_CT_x = mat_training[Training_CT_1];
Training_CT_y = mat_training[Training_CT_2];
Training_CT_z = mat_training[Training_CT_3];
Training_PT_x = mat_training[Training_PT_1];
Training_PT_y = mat_training[Training_PT_2];
Training_PT_z = mat_training[Training_PT_3];
TrLabel = mat_training[Training_label];
TrLabel = np.transpose(TrLabel);
Training_Dataset = len(TrLabel);
mat_validation = h5py.File(DATAPATH_Validation);
mat_validation.keys()
Validation_CT_x = mat_validation[Validation_CT_1];
Validation_CT_y = mat_validation[Validation_CT_2];
Validation_CT_z = mat_validation[Validation_CT_3];
Validation_PT_x = mat_validation[Validation_PT_1];
Validation_PT_y = mat_validation[Validation_PT_2];
Validation_PT_z = mat_validation[Validation_PT_3];
VaLabel = mat_validation[Validation_label];
VaLabel = np.transpose(VaLabel);
Validation_Dataset = len(VaLabel);
######################################
# 初始化
######################################
TrData = np.empty((Training_Dataset, CHANNEL, ROW, COL), dtype = “float32”);
VaData = np.empty((Validation_Dataset, CHANNEL, ROW, COL), dtype = “float32”);
######################################
# 裁剪图片,通道输入
######################################
for i in range(Training_Dataset):
TrData[i,0,:,:]=Training_CT_x[:,:,i];
TrData[i,1,:,:]=Training_CT_y[:,:,i];
TrData[i,2,:,:]=Training_CT_z[:,:,i];
TrData[i,3,:,:]=Training_PT_x[:,:,i];
TrData[i,4,:,:]=Training_PT_y[:,:,i];
TrData[i,5,:,:]=Training_PT_z[:,:,i];
for i in range(Validation_Dataset):
VaData[i,0,:,:]=Validation_CT_x[:,:,i];
VaData[i,1,:,:]=Validation_CT_y[:,:,i];
VaData[i,2,:,:]=Validation_CT_z[:,:,i];
VaData[i,3,:,:]=Validation_PT_x[:,:,i];
VaData[i,4,:,:]=Validation_PT_y[:,:,i];
VaData[i,5,:,:]=Validation_PT_z[:,:,i];
print ’\tThe dimension of each data and label, listed as folllowing:‘
print ’\tTrData : ‘, TrData.shape
print ’\tTrLabel : ‘, TrLabel.shape
print ’\tRange : ‘, np.amin(TrData[:,0,:,:]), ’~‘, np.amax(TrData[:,0,:,:])
print ’\t\t‘, np.amin(TrData[:,1,:,:]), ’~‘, np.amax(TrData[:,1,:,:])
print ’\t\t‘, np.amin(TrData[:,2,:,:]), ’~‘, np.amax(TrData[:,2,:,:])
print ’\t\t‘, np.amin(TrData[:,3,:,:]), ’~‘, np.amax(TrData[:,3,:,:])
print ’\t\t‘, np.amin(TrData[:,4,:,:]), ’~‘, np.amax(TrData[:,4,:,:])
print ’\t\t‘, np.amin(TrData[:,5,:,:]), ’~‘, np.amax(TrData[:,5,:,:])
print ’\tVaData : ‘, VaData.shape
print ’\tVaLabel : ‘, VaLabel.shape
print ’\tRange : ‘, np.amin(VaData[:,0,:,:]), ’~‘, np.amax(VaData[:,0,:,:])
print ’\t\t‘, np.amin(VaData[:,1,:,:]), ’~‘, np.amax(VaData[:,1,:,:])
print ’\t\t‘, np.amin(VaData[:,2,:,:]), ’~‘, np.amax(VaData[:,2,:,:])
print ’\t\t‘, np.amin(VaData[:,3,:,:]), ’~‘, np.amax(VaData[:,3,:,:])
print ’\t\t‘, np.amin(VaData[:,4,:,:]), ’~‘, np.amax(VaData[:,4,:,:])
print ’\t\t‘, np.amin(VaData[:,5,:,:]), ’~‘, np.amax(VaData[:,5,:,:])
return TrData, TrLabel, VaData, VaLabel
读入.mat中储存的数据,输出的就直接是划分好的训练集(TrData, TrLabel)和测试集(VaData, VaLabel)啦,比较简单,不展开说了。关于MATLAB端的数据拓展(Data Augmentation),我将在后续再介绍。说明一下数据拓展的作用也是针对“过度拟合”问题的。
注意一点:我的label为0~1共2个类别,keras要求格式为binary class matrices,所以要转化一下,直接调用keras提供的这个函数np_utils.to_categorical()即可。
3. 训练中后期代码
前面的硬骨头啃完了,这儿就是向开玩笑一样,短短几句代码解决问题。
print(“》》 Build Model 。。.”)
model = create_model(TrData)
######################################
# 训练ConvNets模型
######################################
print(“》》 Training ConvNets Model 。。.”)
print(“\tHere, batch_size =”, BATCH_SIZE, “, epoch =”, EPOCH, “, lr =”, LR, “, momentum =”, MOMENTUM)
early_stopping = EarlyStopping(monitor=’val_loss‘, patience=2)
hist = model.fit(TrData, TrLabel, \
batch_size=BATCH_SIZE, \
nb_epoch=EPOCH, \
shuffle=True, \
verbose=1, \
show_accuracy=True, \
validation_split=VALIDATION_SPLIT, \
callbacks=[early_stopping])
######################################
# 测试ConvNets模型
######################################
print(“》》 Test the model 。。.”)
pre_temp=model.predict_classes(VaData)
3.1 训练模型
先调用1. 直接上卷积神经网络构建的主函数中的函数create_model()建立一个初始化的模型。然后的训练主代码就是一句话
hist = model.fit(TrData, TrLabel, \
batch_size=100, \
nb_epoch=10, \
shuffle=True, \
verbose=1, \
show_accuracy=True, \
validation_split=0.2, \
callbacks=[early_stopping])
:)没错,就一句话,不过这句话里面的事儿稍微比较多一点。。。我这儿就简单列举一下我关注的项:
TrData:训练数据
TrLabel:训练数据标签
batch_size:每次梯度下降调整参数是用的训练样本
nb_epoch:训练迭代的次数
shuffle:当suffle=True时,会随机打算每一次epoch的数据(默认打乱),但是验证数据默认不会打乱。
validation_split:测试集的比例,我这儿选了0.2。注意,这和2.2 数据的简单处理模块中的测试集不是一个东西,这个测试集是一次训练的测试集,也就是下次训练他有可能变成训练集了。而2.2 数据的简单处理模块中的是全局的测试集,对于训练好的网络做的最终测试。
early_stopping:是否提前结束训练,网络自己判断,当本次训练和上次训练的结果差不多了自动回停止训练迭代,也就是不一定训练完nb_epoch(10)次哦
early_stopping的调用在这儿
early_stopping = EarlyStopping(monitor=’val_loss‘, patience=2)
其他的都是和训练的时候的界面有关,按照我的或者默认的来就可以了:)
提一嘴,如果你想要看每一次的训练的结果是可以做到的!hist = model.fit()的hist中存放的是每一次训练完的结果和测试精确度等信息。
再来一嘴,如果你想要看每一层的输出的啥,也是可以做到的!
这个可以用到卷积神经网络和其他传统分类器结合来优化softmax方法的实验,涉及到比较高级的算法了,我以后再说。这儿先只放上看每一层输出的代码:
get_feature = theano.function([origin_model.layers[0].input],origin_model.layers[12].get_output(train=False),allow_input_downcast=False)
feature = get_feature(data)
好吧,再提供一下SVM和Random Forests的Python函数代码吧,如果大家想做这个实验可以用哈:
######################################
# SVM
######################################
def svc(traindata,trainlabel,testdata,testlabel):
print(“Start training SVM.。。”)
svcClf = SVC(C=1.0,kernel=“rbf”,cache_size=3000)
svcClf.fit(traindata,trainlabel)
pred_testlabel = svcClf.predict(testdata)
num = len(pred_testlabel)
accuracy = len([1 for i in range(num) if testlabel[i]==pred_testlabel[i]])/float(num)
print(“\n》》 cnn-svm Accuracy”)
prt(testlabel, pred_testlabel)
######################################
# Random Forests
######################################
def rf(traindata,trainlabel,testdata,testlabel):
print(“Start training Random Forest.。。”)
rfClf = RandomForestClassifier(n_estimators=100,criterion=’gini‘)
rfClf.fit(traindata,trainlabel)
pred_testlabel = rfClf.predict(testdata)
print(“\n》》 cnn-rf Accuracy”)
prt(testlabel, pred_testlabel)
收~打住。
3.2 测试模型
呼呼,这个最水,也是一句话
pre_temp=model.predict_classes(VaData)
套用一个现有函数predict_classes()输入测试集VaData,返回训练完的网络的预测结果pre_temp。好了,最后把pre_temp和正确的测试集标签VaLabel对比一下,就知道这个网络训练的咋样了,实验阶段性胜利!发个截图:
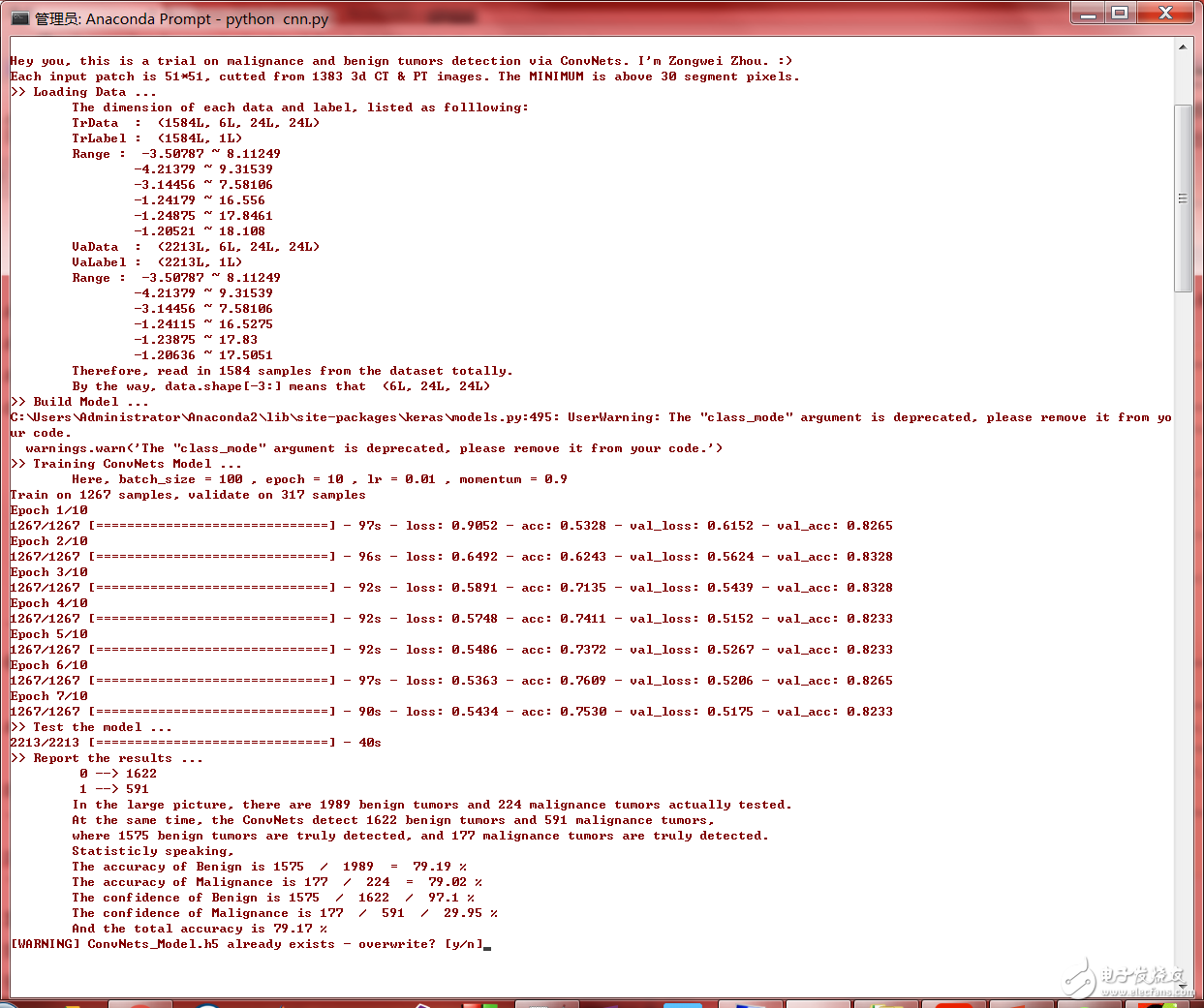
Everybody Happy
3.3 保存模型
训练一个模型不容易,不但需要调整参数,调整网络结构,训练的时间还特别长,所以要学会保存训练完的网络,代码是这样的:
######################################
# 保存ConvNets模型
######################################
model.save_weights(’MyConvNets.h5‘)
cPickle.dump(model, open(’。/MyConvNets.pkl‘,“wb”))
json_string = model.to_json()
open(W_MODEL, ’w‘).write(json_string)
就保存好啦,是这三个文件

保存的模型文件
当你回头要调用这个网络时,用这个代码就可以了
model = cPickle.load(open(’MyConvNets.pkl’,“rb”))
model中就读入了pkl文件内存储的模型啦。
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 0
-
Nanopi深度学习之路(4)深度学习框架安装前的依赖项安装2018-06-08 0
-
【NanoPi K1 Plus试用体验】搭建深度学习框架2018-07-17 0
-
迅为RK3399开发板人工智能深度学习框架2021-05-21 0
-
TensorFlow实战之深度学习框架的对比2017-11-16 4627
-
基于Keras搭建的深度学习网络示例2018-06-06 8357
-
八种主流深度学习框架的介绍2022-04-26 8897
-
深度学习框架是什么?深度学习框架有哪些?2023-08-17 2971
-
深度学习框架的作用是什么2023-08-17 1661
-
深度学习框架tensorflow介绍2023-08-17 2626
-
深度学习算法库框架学习2023-08-17 770
-
深度学习框架连接技术2023-08-17 843
-
深度学习框架和深度学习算法教程2023-08-17 1144
-
keras的模块结构介绍2024-07-05 441
-
keras模型转tensorflow session2024-07-05 616
全部0条评论

快来发表一下你的评论吧 !
