

系统机器学习算法总结知识分享
电子说
描述
Statsbot数据科学家Daniil Korbut简明扼要地介绍了用于推荐系统的主流机器学习算法:协同过滤、矩阵分解、聚类、深度学习。
现在有许多公司使用大数据来制定高度相关的建议以提高收入。数据科学家需要根据业务的限制和需求,在各种推荐算法中选择最好的算法。
为了简化这一任务,Statsbot团队准备了一份现有主要推荐系统算法的概览。
协同过滤
协同过滤(collaborative filtering, CF)及其改版是最常用的推荐算法之一。 即使是数据科学初学者也可以使用它来构建他们的个人电影推荐系统,比如用它写一个简历项目。
当我们想向用户推荐东西时,最符合逻辑的做法是找到有相似兴趣的人,分析他们的行为,然后给我们的用户推荐相同的东西。 或者我们可以查看与用户之前所购类似的物品,并进行相应的推荐。
这正是CF的两种基本方法:基于用户的协作过滤和基于物品的协作过滤。
在这两种情形下,推荐引擎分两步:
-
找出数据库中有多少用户/物品与给定的用户/物品类似。
-
评估其他用户/物品,这一评估基于比待评估用户/物品更相似的用户/物品的总权重,以预测给用户推荐相应产品的评分。
算法中的“最相似”是什么意思?
假设我们有一个表示每个用户的偏好的向量(矩阵 R的行)和一个表示用户给每件产品评分的向量(矩阵 R的列)。
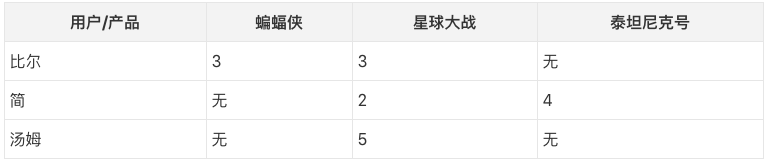
首先,让我们去除一些元素,只保留两个向量中值均已知的元素。
例如,如果我们想比较比尔和简,我们可以看到,比尔还没有看过《泰坦尼克号》,而简到现在为止还没看过《蝙蝠侠》,所以我们只能通过《星球大战》来衡量他们的相似性。怎么会有人不看《星球大战》,是吧?:)
最流行的衡量相似性的技术是用户/物品向量之间的余弦相似性或加权平均数。
矩阵分解
下一个有趣的算法是矩阵分解。这是一个非常优雅的推荐算法,因为使用矩阵分解时通常不用考虑要在结果矩阵的列和行中保留的物品。
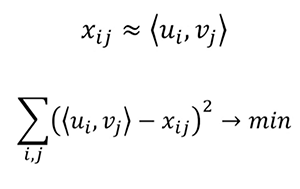
u是第i个用户的兴趣向量,v是表示第j部电影的参数的向量。因此,我们可以使用u和v的点积来逼近x(第i个用户对第j部电影的评分)。我们使用已知评分来构建这些向量,并使用它们来预测未知评分。
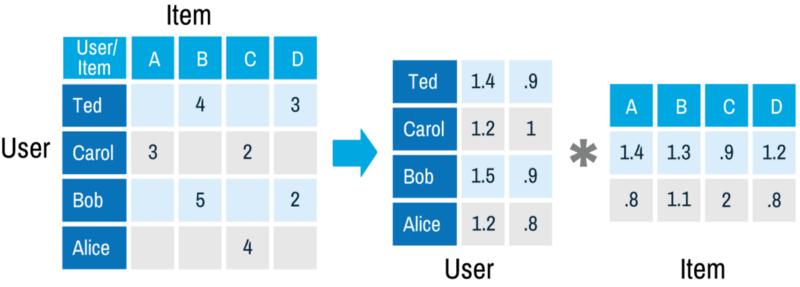
例如,我们有表示用户特德的向量(1.4; .9)和表示电影A的向量(1.4; .8),矩阵分解之后我们可以直接通过计算(1.4; .9)和(1.4; .8)的点积来还原电影A——特德的评分,结果为2.68。
聚类
前面两个推荐算法非常简单,比较适合小型系统。到目前为止,我们将推荐问题看作一个监督学习任务。现在到了应用无监督方法来解决这个问题的时候了。
想象一下,我们正在建立一个大型推荐系统,协同过滤和矩阵分解会花很长时间。这时第一个想到的应该是聚类(clustering)。
根据属于同一聚类的所有客户的偏好,每个聚类会被分配一个典型偏好。每个聚类中的客户将收到在聚类层次计算出的推荐。
业务初期缺乏用户评分,因此聚类会是最佳选择。
不过,单独使用的话,聚类有点弱。因为通过聚类,我们识别出用户群组,然后给同一群组中的每个用户都推荐相同的物品。当我们有足够多的数据的时候,更好的选择是将聚类作为第一步,用来调整相关用户/物品选取,以供协同过滤算法使用。聚类也能提升复杂推荐系统的性能。
深度学习
十年来,神经网络有一个巨大的飞跃。今天,神经网络被应用到许多领域,正逐渐取代传统的机器学习方法。我想谈一下YouTube使用的深度学习方法。
毫无疑问,为这样的服务打造推荐系统是一项非常具有挑战性的任务,因为这一服务的规模很大,语料库是动态的,还有各种难以观察的外部因素。
根据《YouTube推荐系统的深度神经网络》,YouTube推荐系统算法包括两个神经网络:一个用于生成候选视频,另一个用于排名。如果你没有足够的时间阅读上面的论文,我这里有一个快速总结。
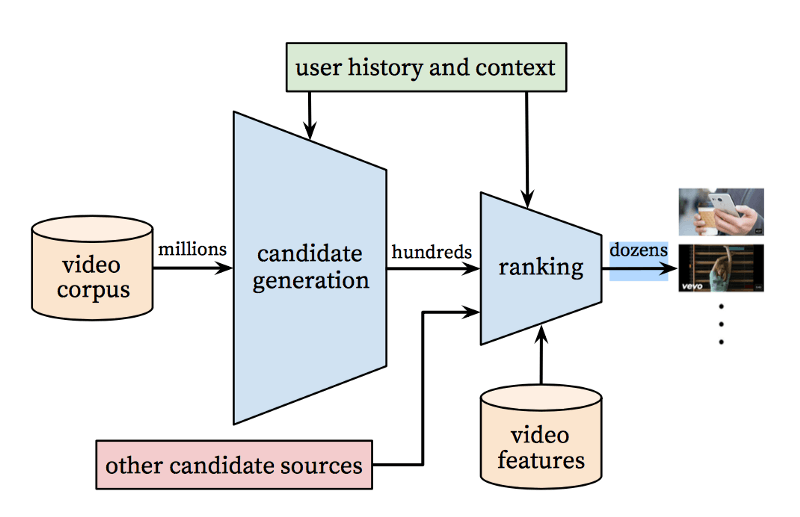
接受用户的历史事件作为输入,候选生成网络显著减少了视频的数量,从一个巨大的语料库抽取出一组相关性最高的视频。生成的候选视频是最和用户相关的,我们即将预测用户给候选视频的评分。这个网络的目标只是通过协同过滤来提供一些范围较广的个性化候选视频。
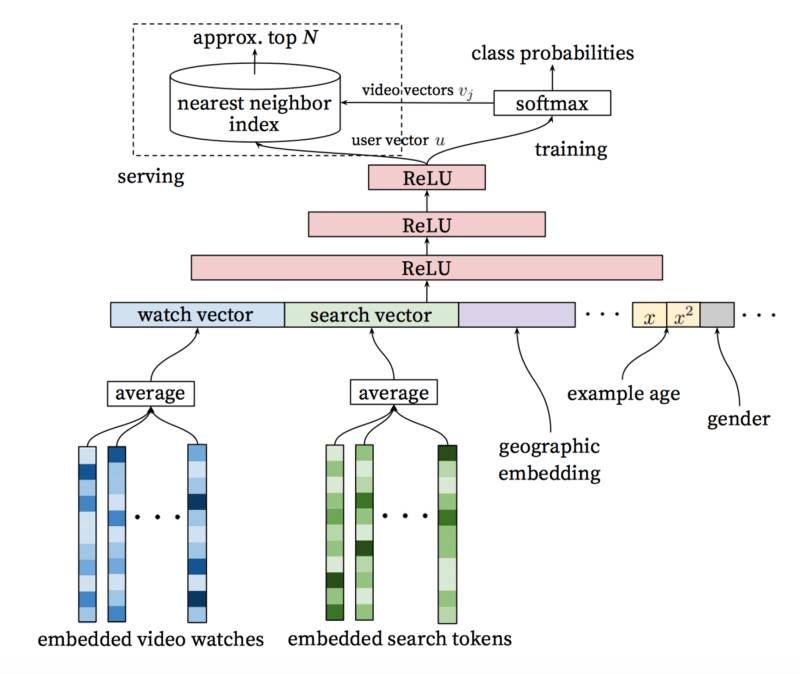
接下来我们需要更仔细地分析这些候选视频,以挑选出其中最好的视频。我们通过评分网络完成这一任务,评分网络可以通过一个期望目标函数给每个视频赋值一个分数,该期望目标函数使用描述视频的数据和有关用户行为的信息。评分最高的那些视频将被推荐给用户。
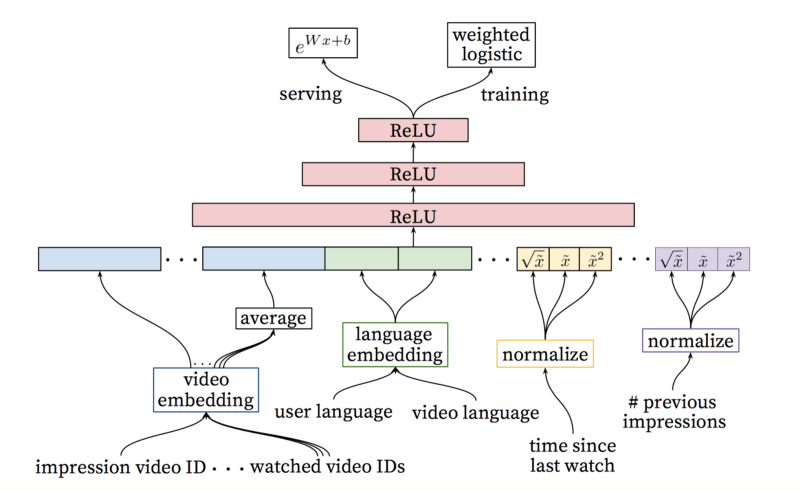
使用这一两步方法,我们可以基于一个非常巨大的视频语料库推荐视频,同时保证推荐的少量视频是个性化的。这一设计也允许我们混合从其他来源生成的候选视频。
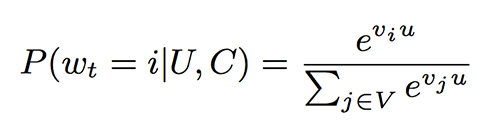
这一推荐任务构成了一个极端多类分类(extreme multiclass classification)问题,基于用户(U)和情境(C)精确地分类在给定时刻t观看(wt)的特定视频,这一视频取自一个语料库(V),总共有数百万的视频类别(i)。
构建你自己的推荐系统
-
基于大型数据库的在线推荐,最好的办法是将这个问题拆分成两个子问题:1)选择排名最高的N个候选 2)对它们进行评分。
-
如何评估模型质量?除了标准的质量指标之外,还有一些特别针对推荐问题的指标:Recall at K和Precision at K,Average Recall at K和Average Precision at K。另外可以参考《A Survey of Accuracy Evaluation Metrics of Recommendation Task》(JMLR 10 (2009))
-
如果使用分类算法解决推荐问题,则应考虑生成负样本。如果用户购买了推荐的物品,不应将其作为正样本,也不应将未购买的推荐物品作为负样本。
-
基于在线分数和离线分数考量算法质量。 仅使用历史数据的训练模型可能导向简陋的推荐系统,因为该算法不知道新的潮流和偏好。
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2372
-
机器学习小白的总结2020-07-08 1830
-
机器学习算法分享2020-06-09 2429
-
机器学习之高级算法课程学习总结2020-05-05 1535
-
机器学习十大算法精髓总结2019-05-05 4664
-
机器学习算法常用指标汇总2019-02-13 6150
-
从数据、算力、算法、教学总结机器学习的民主化2018-08-18 4158
-
经典的机器学习算法汇总2018-08-11 6991
-
人工智能之机器学习常见算法2018-02-02 2075
-
Spark机器学习库的各种机器学习算法2017-09-28 1371
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 3615
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199345
全部0条评论

快来发表一下你的评论吧 !
