

基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能
电子说
1.4w人已加入
描述
背景
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它允许用户在不需要深入了解分布式底层细节的情况下,开发分布式程序。Hadoop充分利用集群的威力进行高速运算和存储,特别适用于处理超大数据集。
Hadoop的生态系统非常丰富,包括许多相关工具和技术,如Hive、Pig、HBase等,这些工具可以方便地构建复杂的大数据应用。Hadoop广泛应用于各种场景,包括数据处理和分析、数据挖掘和机器学习、日志分析、图像和音频处理等。
解决方案
Kepware拥有强大的驱动数据采集能力,也可以提供自定义的驱动数据采集能力,本方案使用UDD(Universal Device Driver)驱动连接Hadoop,通过其HBase的引擎,通过简单的JS代码编写即可实现和大数据处理Hadoop的互联互通。通过此方案,方便企业发现数据中的模式和趋势,做出更好的业务决策,以及处理和分析大规模数据集。
应用架构图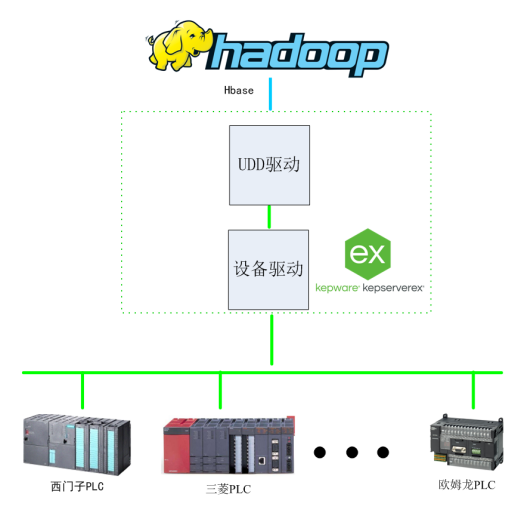
UDD驱动代码示例
填入HBase的地址:
数据存储格式
Row
kepTagValue:name
kepTagValue:quality
kepTagValue:value
1001
Tag1
192
100
1002
Tag1
192
101
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
如何从零学大数据?2018-03-01 3972
-
基于阿里云数加MaxCompute的企业大数据仓库架构建设思路2018-03-15 3849
-
大数据运用的技术2018-04-08 3827
-
大数据专业技术学习之大数据处理流程2018-06-11 4330
-
hadoop不同版本有哪些2018-09-18 2176
-
DKHadoop大数据平台架构详解2018-10-17 4655
-
基于hadoop的免费大数据平台有哪些?2018-11-07 3033
-
工业大数据分析平台的应用价值探讨2018-11-12 3632
-
大数据hadoop入门之hadoop家族产品详解2018-12-26 3031
-
大数据的来源分析2019-08-27 3634
-
hadoop大数据windows搭建环境2017-09-08 883
-
hadoop是什么_华为大数据平台hadoop你了解多少2017-12-25 23916
-
hadoop与数据挖掘的关系_区别_哪个好2018-01-02 6432
-
大数据工程师的日常工作是什么2019-05-30 6634
-
大数据对于企业存在什么价值2020-01-08 3829
全部0条评论

快来发表一下你的评论吧 !
