

GPGPU体系结构优化方向(1)
描述
继续上文GPGPU体系结构优化方向 [上],介绍提高并行度和优化流水线的方向。
不同的workload因为存在不同的input size和对寄存器以及memory的需要,有时会导致只有少量的活跃thread block,这降低了执行单元的利用率。因此可以通过同时运行多个workload,增加并行度来提高利用率。另一种方法则是利用scalar opportunity以及运行的warp之间的value similarity。
具体的子方向:
减少资源碎片化增加并行度
Unifying Primary Cache, Scratch and Register File Memory in a Throughput processor提出不同的workload对资源的需求不同,因此可以动态的对不同workload的资源进行划分。
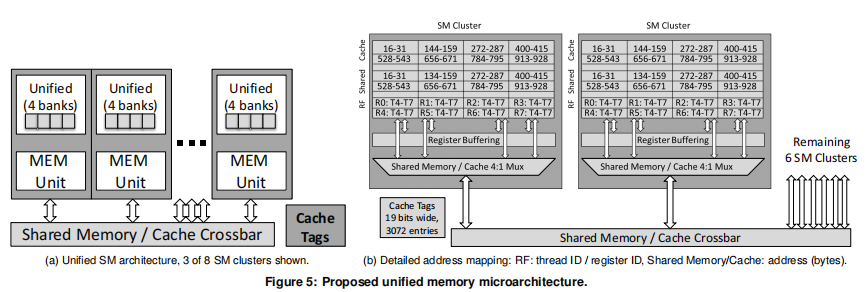
Shared Memory Multiplexing: A Novel Way to ImproveGPGPU Throughput注意到在一个thread block内的warp会在不同的时间点结束,此时,即使是较早完成的warp占用的资源也不会释放,这导致了资源的低效利用,此时应该可以launch新的warp。
他们将资源的低效利用划分为temporal和spatial:
temporal低效是因为warp的不同时间结束导致的
spatial的低效则是因为没有足够的资源launch新的warp
他们提出了在资源不够launch一个新的thread block时,只launch部分thread block的方法。GPU Multitaksing
多任务同时在GPU上执行
可以有效的提高GPU的利用率。
有助于操作系统调用GPU时,对GPU的虚拟化以及在云上deploy GPU
Improving GPGPU Concurrency with Elastic Kernels将task不能够进行并行化的原因分成了几类:
Serialization due to Lack of Resources
Serialization due to Inter-stream Scheduling
Serialization due to Memory Transfers
Serialization in the CUDA API
Serialization in the Implementation
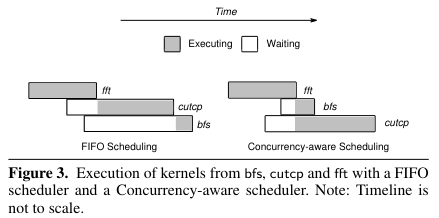
他们观察到如果bfs只占用了部分资源,但是fft和cutcp占用了全部资源,那么即使bfs较晚进入queue中,也可以不按照fifo的调度顺序,将bfs优先调度,空置的资源同时执行cutcp,这样提高了并行度。
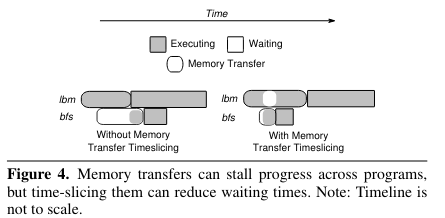
此外,观察到GPU的DMA只能在一个时间段内进行拷贝到GPU和拷出GPU中的一种。如果下图中的bfs等到数据的拷贝,但是此时lbm正在将数据拷出,会导致bfs的等待,因此可以将DMA的任务切片,提高并行度。
此外,Increasing GPU throughput using kernel interleaved thread block scheduling等也发现可以将memory intensive和compute intensive的workloads混合调度,这样提高资源的利用效率。
在调度workloads时,也需要注意到workload的优先级,如果优先级较高的workload等待时间较长,那么应当切换到优先级高的workload。Enabling preemptive multiprogramming on GPUs提出了两种抢占的方式,context swtiching和draning。
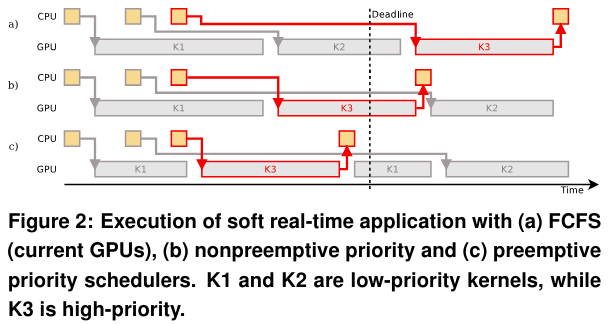
Chimera: Collaborative Preemptionfor Multitasking on a Shared GPU提出了被抢占的workload可以不需要保存上下文,直接放弃,在获得资源后重新从头开始执行。
利用scalar and value similarity opprotunities
Characterizing Scalar Opportunities inGPGPU Applications提出了 scalar opportunity,即在各个threads中同时对相同的数据执行相同的计算,也就得到相同的结果,写回相同的值。AMD将这类计算单独放在GPU core中的标量单元中进行计算。
“We define a scalar opportunity as a SIMD instructionoperating on the same data in all of its active threads. Atypical example of scalar opportunities is loading a constantvalue when each active thread loads the same value frommemory and then stores it in the corresponding component ofthe destination vector register. Finally those components storethe same value.”
基于这个的工作主要有几类:
检测方法:硬件或者软件编译器
执行方法:单独的标量单元或者单独使用一个core计算
专门的寄存器或者和其他指令共用寄存器
取址译码执行和其他指令的资源共享或者单独设计
支持的指令类型
Improving execution pipeling
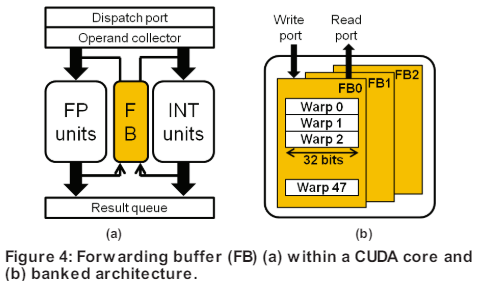
现代 GPU为了有效地共享资源,在 GPU 管道中插入了buffering和collisionavoidance stage,从而增加指令的读后写 (RAW) 延迟。通常大家认为GPU通过warp的调度可以隐藏RAW延迟,因而GPU没有设计data forward networking。但是Exploiting GPU Peak-power and Performance Tradeoffs through Reduced Effective Pipeline Latency 观察到许多 GPGPU 应用程序没有足够的活动线程来准备发出指令来隐藏这些 RAW 延迟。
因此他们使用most recent result forwarding(MORF)来实现data forwarding,同时相对于传统的data forwarding,降低了功耗。
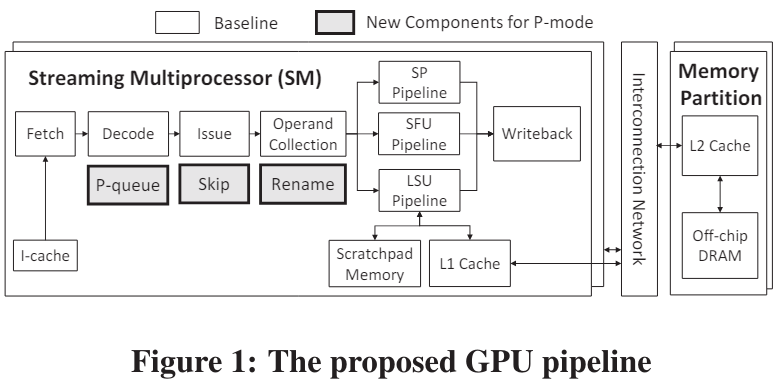
Warped-Preexecution: A GPU Pre-execution Approachfor Improving Latency Hiding文章提出在warp的线程进入长期等待的idle状态时,可以进入P-mode。在P-mode模式下,识别出程序中后续的不存在依赖关系的指令,先执行后续的指令,也即实现了乱序执行。
-
ARM体系结构和编程2012-12-04 11178
-
ARM嵌入式体系结构与接口技术.ARM SoC体系结构(中文版)2013-03-23 5159
-
ARM SOC体系结构2016-11-22 6149
-
嵌入式微处理器体系结构2021-11-08 2329
-
Microarchitecture指令集体系结构2021-12-14 1994
-
Arm的DRTM体系结构规范2023-08-08 1139
-
ARM体系结构与编程2010-02-11 826
-
LTE体系结构2009-06-16 10307
-
网络体系结构,什么是网络体系结构2010-04-06 2143
-
ARM体系结构与程序设计2011-10-27 2765
-
ARM体系结构(1)PPT课件2016-01-08 801
-
XScale体系结构及编译优化问题2016-04-18 918
-
软件体系结构的分析2017-11-24 1458
-
基于DoDAF的卫星应用信息链体系结构2018-01-10 1212
-
GPGPU体系结构优化方向(2)2024-10-09 1489
全部0条评论

快来发表一下你的评论吧 !
