

GPGPU体系结构优化方向(2)
描述
GPGPU体系结构优化方向 [下]
继续之前的文章,我们介绍GPGPU的优化方向:1)增强GPGPU的可编程性 2)CPU-GPU异构架构
增强GPGPU的可编程性
增强GPGPU的可编程性可以增加GPGPU相对其他平台,比如FPGA的优势。主要有以下三个方向:
1. Coherence and Consistency model
2. Transactional Memory
3. Memory Management
Coherence and Consistency model
目前的GPU缺乏cache一致性,需要diable 线程private的L1 cache,或者采用基于软件的bulk coherence决策(比如在同步点,flush掉所有的private L1 cache。
不同于CPU的一致性模型,GPU存在大量的线程,如果也按照CPU的方式维护一致性,那么代价很大。文章【Cache Coherence for GPU Architectures】通过使用全局同步计数器来self-invalidate cache block,不需要显性的信息来维护一致性,称为Temporal Coherence(TC)。
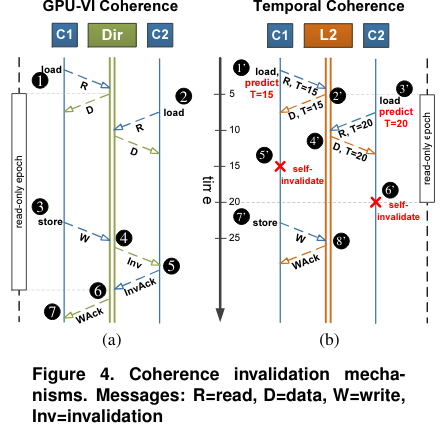
【Exploring Memory Consistency for Massively-Threaded Throughput-Oriented Processors】分析了硬件一致性模型,通过比较了sequential consistency, total store order and relaxed memory model,他们发现硬件一致性在GPU上的代价很小,可以维护strongly ordered,而只需要很小的代价。
Transactional memory
GPU中,跨线程的通信是通过在同一个thread block内的thread的scratch-pad memory进行的。最新的GPU也可以使不同的线程通过全局的原子操作来访问进行全局thread block的通信。
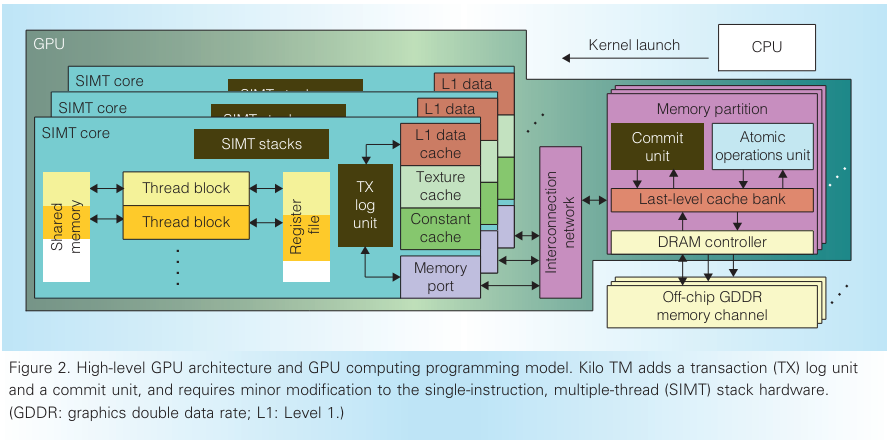
原子操作可以用于实现软件同步原语,比如fine-grain lock,可以简化编程,但是lock-based的同步容易导致死锁。KILO TM (KILO TM: Hardware Transactional Memory for GPU Architecture) 不依赖cache一致性或者原子操作,而是通过细粒度的基于值的方法检测冲突。
Memory management
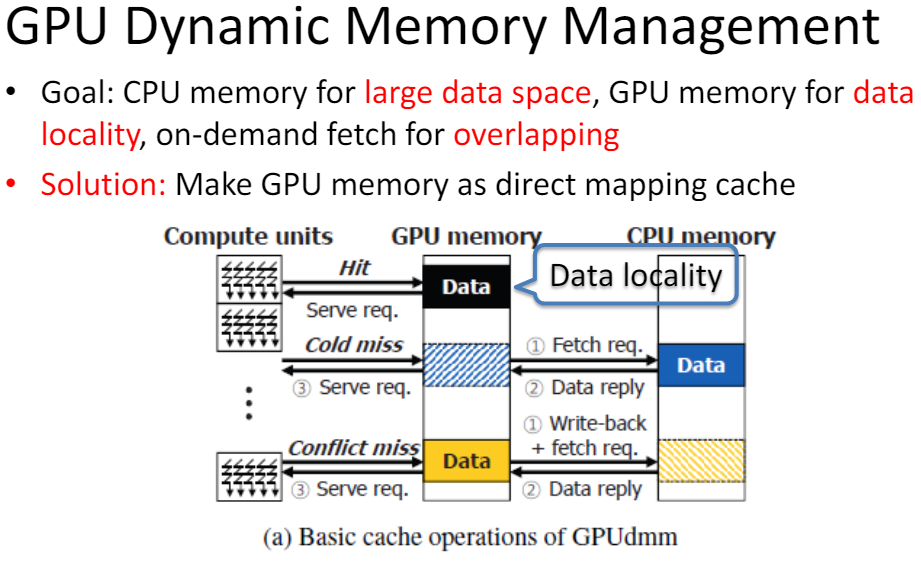
GPUdmmGPUdmm: A High-performance andMemory-Oblivious GPU ArchitectureUsing Dynamic Memory Management通过将GPU的内存看作是CPU的内存的缓存,来进行动态的内存管理。有以下优势:
简化了软件编程对memory的管理
给编程人员一个CPU的memory编程视图
将GPU执行和CPU-GPU数据传输overlap
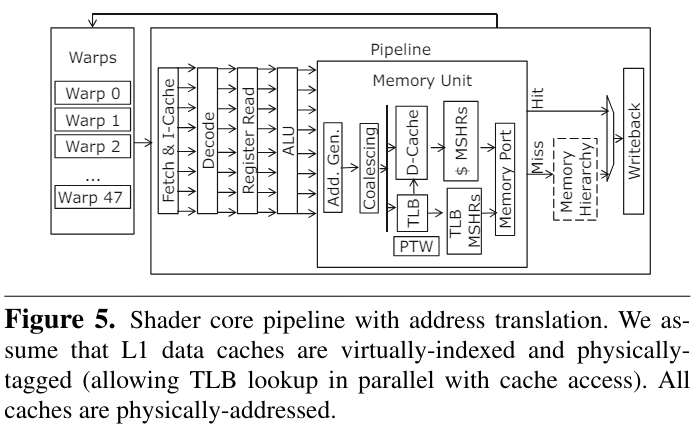
【Architectural Support for Address Translation on GPUs】通过基于GPU的特性修改了传统的TLB和PTW来减少对虚拟地址物理地址转换的overhead。
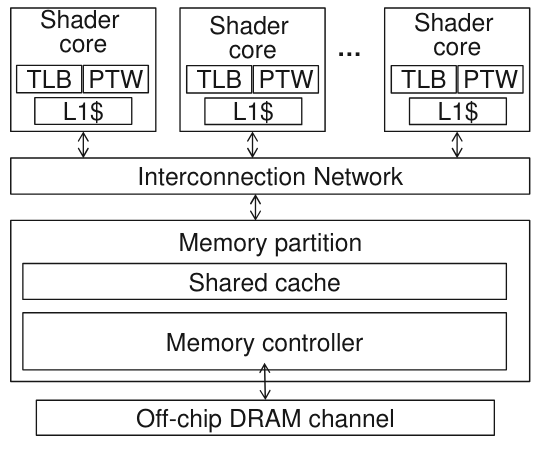
通过在GPGPU内部支持virtual-physical address的转换可以支持unified memory,文章的作者通过比较与CPU TLB和page table walker的不同,主要进行了以下改进:
warp内的线程公用TLB,而不是每个线程独占一个
地址coaleacing之后再进行虚实地址转换
提出了page divergence的观点,即一个warp内只需要3个读口即可满足常用的情况
TLB采用非阻塞tlb
Cache Conscious Warp Scheduling
CPU-GPU与异构架构
CPU-GPU集成
【Redefining the role of the CPU in the era of CPU–GPU integration】文章展示了在将代码部分CPU执行,部分卸载到GPU上执行之后,在CPU执行的代码和传统的CPU优化过的代码完全不同。
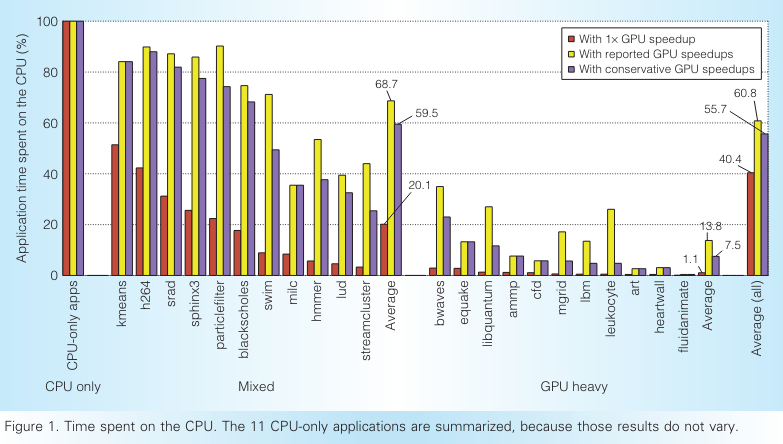
他们展示了剩余给CPU的代码有更低的指令层并行性,更复杂的load store操作,更难进行预取和分支预测。并且剩下的顺序执行的代码不会从SIMD指令获益,也不会从更多的CPU核数上受益,因为线程并行和数据并行都被卸载到GPU上了。
CPU-GPU 编程
【Heterogeneous system coherence for integrated CPU–GPU system】提出以前的基于目录一致性的CPU-GPU的颗粒度是64Byte,可以将其增加到1KB。因为很多GPU程序是有高度的spatial locality的,大多数的请求是不需要访问region directory的。
利用异构架构
【CPU-Assisted GPGPU on Fused CPU-GPU Architectures】提出可以通过在CPU将程序卸载到GPU之后,在编译器的辅助下另起一个线程,这个线程用于专门给GPU预取数据,因为CPU有更高的时钟频率,因此预取提高l3 cache的命中率,可以取得很好的效果。
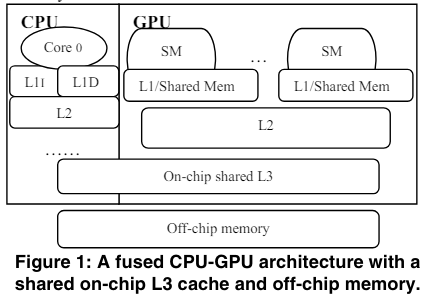
Shared resources management
因为CPU和GPU越来越趋近于共享memory资源,包括last level cache, 片上网络和内存。因为GPU可以产生大量的内存请求,可以竞争掉CPU对内存的请求。主要有两种方式来减少CPU和GPU之间的干扰:
application-aware resource managerment
throttling-based management
【Staged memory scheduling: Achieving high performance and scability in heterogeneous systems】提出了staged memory scheduling策略。在内存的层面对cpu gpu的mem req进行平衡。
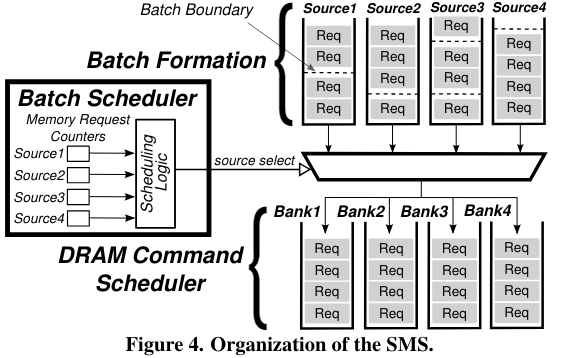
第一个stage是基于row-buffer locality,第二个stage通过平衡 “偏向CPU的shortest job first调度策略” 和 “偏向GPU的round robin调度策略”来保证CPU和GPU的平衡。 【TAP: A TLP-Aware Cache Management Policy for a CPU-GPU Heterogeneous】发现并不是所有的GPU应用都是对latency不敏感,也存在对cache 敏感,对latency敏感的应用,并且发现GPU core会通常比CPU core更频繁地访问Cache。他们引入了cache block lifetime normalization策略来使得对于CPU和GPU,cache都有相似的lifetime。 【Managing GPU concurrency in heterogeneous architectures】通过增加或减少GPU的active warp,来减少其与CPU的竞争。
总结:
增强GPU的可编程性
1. Coherence and Consistency model 通过使用计数器,避免显示的维护cache一致性,self-invalidate。另外硬件维护strongly ordered内存一致性,代价也可以很小。
2. Transactional Memory 可以使用基于value检测冲突。
3. Memory Management 可以将GPU的memory视为CPU memory的cache。另外也有对虚实转换TLB和page table walker的优化工作。
CPU-GPU异构架构
1. CPU的代码特性在将并行性高的代码offload到GPU之后完全不同
2. 同样是对CPU,GPU一致性的优化,将颗粒度从64B增加到1KB
3. 利用异构架构,CPU执行对GPU数据的预取工作
4. 针对CPU和GPU对资源竞争的平衡,可以平衡对memory,cache的访问,也可以调节GPU的active warp。
-
ARM SOC体系结构2016-11-22 6164
-
嵌入式微处理器体系结构2021-11-08 2341
-
Microarchitecture指令集体系结构2021-12-14 2006
-
Arm的DRTM体系结构规范2023-08-08 1167
-
ARM体系结构与编程2010-02-11 844
-
LTE体系结构2009-06-16 10323
-
网络体系结构,什么是网络体系结构2010-04-06 2158
-
ARM体系结构与程序设计2011-10-27 2797
-
ARM体系结构(2).PPT课件2016-01-08 588
-
XScale体系结构及编译优化问题2016-04-18 948
-
软件体系结构的分析2017-11-24 1486
-
基于DoDAF的卫星应用信息链体系结构2018-01-10 1244
-
微处理器体系结构2021-04-14 1507
-
Oracle体系结构讲解2021-09-27 1018
-
GPGPU体系结构优化方向(1)2024-10-09 1948
全部0条评论

快来发表一下你的评论吧 !
