

详细剖析神经网络和深度神经网络的区别
电子说
描述
深度网络,顾名思义,就是有“很多”层的网络。
那么到底多少层算深度呢?这个问题可能没有一个明确的答案。某种意义上,这个问题类似“有多少粒沙子才能算沙丘”。但是,一般而言,我们把有两层或两层以上隐藏层的网络叫做深度网络。相反,只有一个隐藏层的网络通常被认为是“浅度网络”。当然,我怀疑我们也许会经历网络层数的通货膨胀。十年之后,人们也许会认为10层隐藏层的网络都是“浅度网络”,只适合幼儿园小孩做练习用。非正式的说法,“深度”暗示应对这样的网络比较困难。
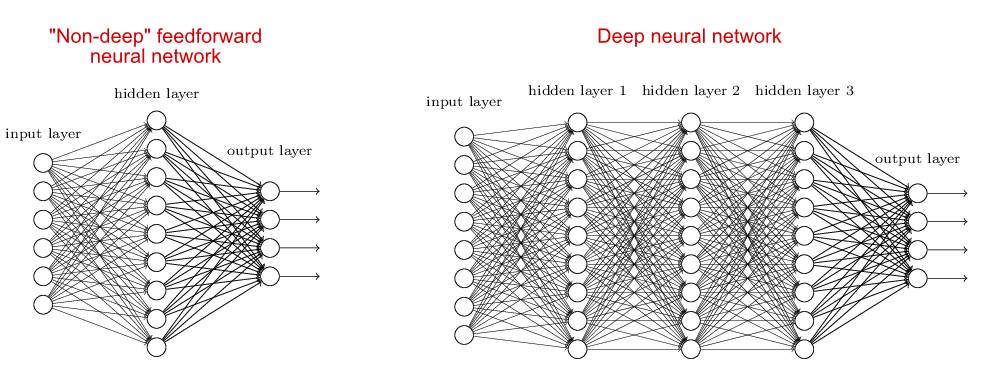
但是,你真正想问的问题,其实是为什么更多的隐藏层有用?
多少让人吃惊的是,其实没人知道真正的原因。下面我将简要地介绍一些常见的解释,但是这些解释的真实性还不能令人信服。我们甚至都不能确信更多的层真的起到了作用。
我说这让人吃惊,是因为深度学习在业界非常流行,年年在图像辨识、围棋、自动翻译等很多领域突破记录。然而我们却始终不清楚深度学习的效果为什么这么好。
通用逼近理论(universal approximation theorem)表明,一个“浅度”神经网络(有一个隐藏层的神经网络)可以逼近任何函数,也就是说,浅度神经网络原则上可以学习任何东西。因此可以逼近许多非线性激活函数,包括现在深度网络广泛使用的ReLu函数。
既然如此,为什么大家还要用深度网络?
好吧,一个朴素的回答是因为它们效果更好。下图是Goodfellow等著《深度学习》中的一张图片,表明对某个特定问题而言,隐藏层越多,精确度越高。在其他许多任务和领域中同样可以观察到这个现象。
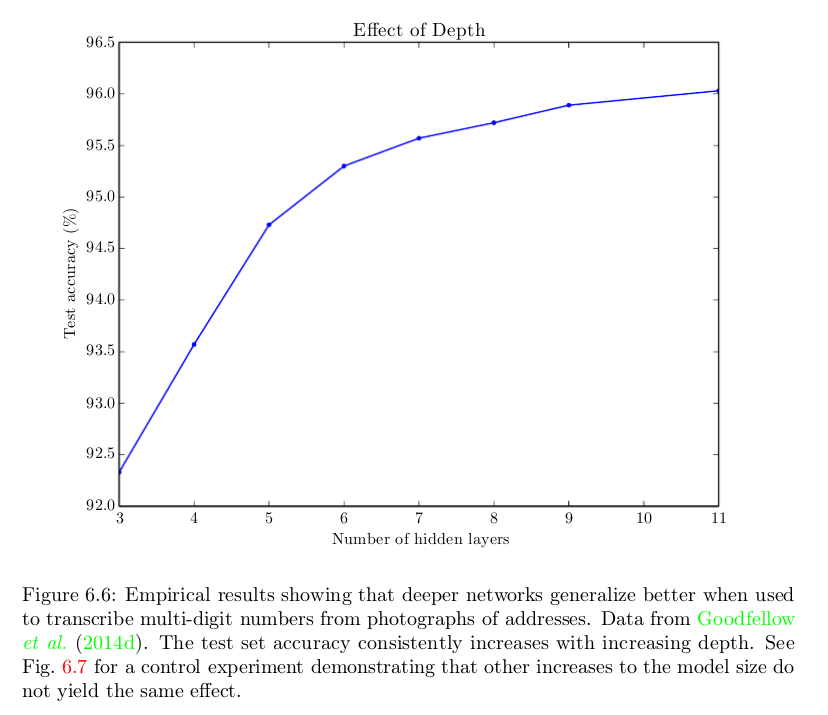
我们知道一个浅度网络本可以做得和深度网络一样好,但是事实往往并非如此。问题来了——为什么?可能的答案包括:
也许一个浅度网络需要比深度网络更多的神经元?
也许我们目前的算法不适合训练浅度网络?
也许我们通常试图解决的问题不适合浅度网络?
其他原因?
Goodfellow等著《深度学习》为上面的第一个和第三个答案提供了一些理由。浅度网络的神经元数量将随着任务复杂度的提升进行几何级数的增长,因此浅度网络要发挥作用,会变得很大,很可能比深度网络更大。这个理由的依据是很多论文都证明了在某些案例中,浅度网络的神经元数量将随着任务复杂度的提升进行几何级数的增长,但是我们并不清楚这一结论是否适用于诸如MNIST分类和围棋这样的任务。
关于第三个答案,《深度学习》一书是这么说的:
选择深度模型编码了一个非常通用的信念,我们想要学习的函数应该涉及若干较简单的函数的组合。从表征学习的视角来说,我们相信正学习的问题包括发现一组差异的底层因素,这些因素可以进一步用其他更简单的差异的底层因素来描述。
我认为目前的“共识”是上述第一个和第三个答案的组合是深度网络有效的原因。
但是这离证明还很远。2015年提出的150+层的残差网络赢得了多项图像辨识竞赛的冠军。这是一个巨大的成功,看起来是一个令人难以抗拒的越深越好的论据。
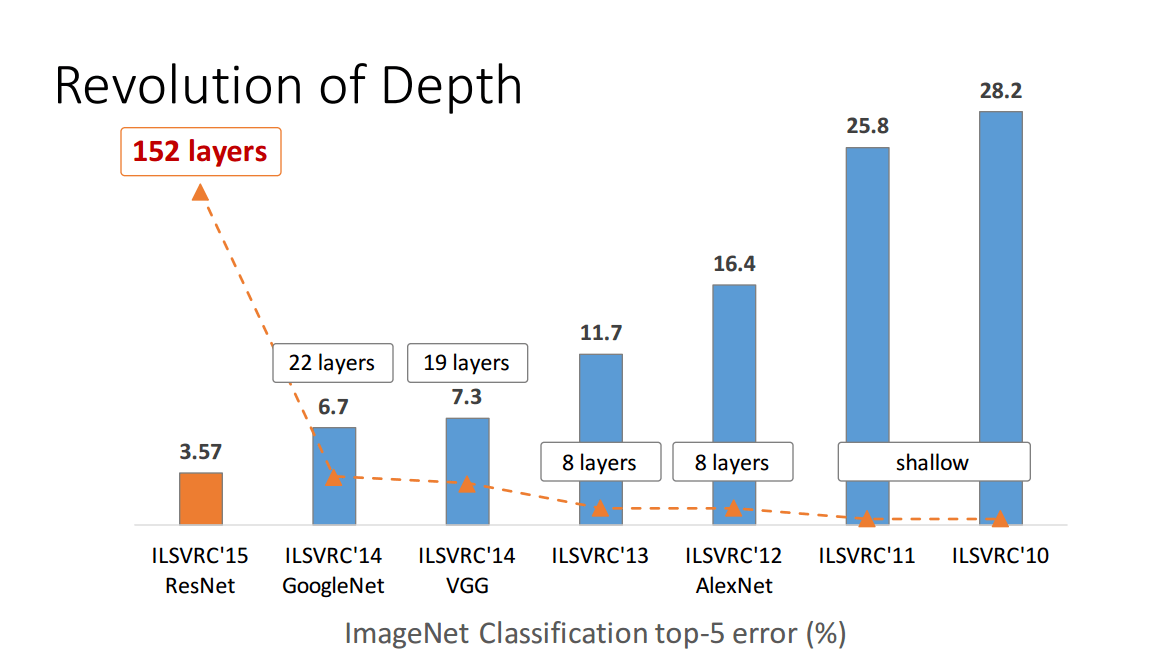
然而,2016年提出的广残差网络(Wide Residual Networks)以16层的网络超越了150+层的残差网络。
Ba和Caruana在2014年发表的论文《Do Deep Nets Really Need to be Deep?》(深度网络真的需要那么深吗?)通过模型压缩方案,用浅度网络模拟一个训练好的深度网络,对某些深度网络而言,模拟它们的浅度网络能表现得一样好,尽管直接在相应数据集上训练浅度网络无法达到这样的表现。
所以,也许真正的答案是上文提到的第二个答案。
正如我一开始说的那样,现在还没人确定自己知道真正的答案。
过去10年来,深度学习方面的进展令人惊叹!然而,大多数进展是通过试错法得到的,我们仍然缺乏对到底是什么让深度网络起效的基本理解。甚至,对到底什么是配置高效的深度网络的关键这个问题,人们的答案也经常变来变去。
Geoffrey Hinton在神经网络方面工作了20+年,却长期没有得到多少关注。直到2006年发表了一系列突破性的论文,介绍了训练深度网络的有效技巧——在梯度下降前先进行无监督预训练。之后很久的一段时间人们都认为无监督预训练是关键。
接着,在2010年Martens表明Hessian-free优化的效果更好。在2013年,Sutskever等人表明随机梯度下降加上一些非常聪明的技巧能表现得更好。同时,在2010年大家意识到用ReLu代替Sigmoid能显著改善梯度下降的表现。2014年提出了dropout。2015年提出了残差网络。人们提出了越来越多有效的训练网络的方法,10年前至关重要的洞见在今天常常被人厌烦。这些大部分都是由试错法驱动的,我们对为什么某种技巧效果这么好,另一种技巧效果不那么好知之甚少。
我们甚至不知道为什么深度网络达到表现高原;10年前人们归咎于极小值,但现在人们不这么看了(达到表现高原时梯度趋向于保持一个较大值)。这是一个非常基本的有关深度网络的问题,而我们甚至连这也不知道。
-
神经网络资料2019-05-16 0
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 0
-
卷积神经网络如何使用2019-07-17 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
深度神经网络是什么2021-07-12 0
-
如何构建神经网络?2021-07-12 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
【人工神经网络基础】为什么神经网络选择了“深度”?2018-09-06 695
-
什么是神经网络?什么是卷积神经网络?2023-02-23 3583
-
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别2023-08-21 4170
-
人工神经网络和bp神经网络的区别2023-08-22 4547
-
卷积神经网络和bp神经网络的区别2024-07-02 4282
-
深度神经网络与基本神经网络的区别2024-07-04 931
-
循环神经网络和卷积神经网络的区别2024-07-04 1345
-
BP神经网络和人工神经网络的区别2024-07-10 1158
全部0条评论

快来发表一下你的评论吧 !
