

VILA与其他模型在提供边缘AI 2.0方面的表现
描述
VILA 是 NVIDIA 研究部门与麻省理工学院共同开发的高性能视觉语言模型系列。最大的模型约有 400 亿参数,最小的模型约有 30 亿参数,并且完全开源(包括模型检查点、训练代码和训练数据)。
本文将比较 VILA 与其他模型在提供边缘 AI 2.0 方面的表现。
最初几个版本的边缘 AI 需要在边缘设备上部署经过压缩的 AI 模型。该阶段被称为边缘 AI 1.0,侧重于特定任务模型,这种方法的挑战在于需要用不同的数据集来训练不同的模型,而其中的负样本难以采集,离群情况也很难处理。这一过程非常耗时,因此需要适应性更强、通用性更好的 AI 解决方案。
边缘 AI 2.0:生成式 AI 的兴起
边缘 AI 2.0 标志着向增强泛化的转变,由基础视觉语言模型(VLM)提供支持。
VILA 等视觉语言模型具有惊人的多功能性,能够理解复杂的指令并迅速适应新场景,这种灵活性使其成为诸多应用中的重要工具。它们可以优化自动驾驶汽车的决策,在物联网和智能物联网环境中创建个性化交互,进行事件检测,提升智能家居体验等。
VLM 的核心优势在于其在语言预训练过程中获得的世界知识,以及用户使用自然语言进行查询的能力。这就为由 AI 驱动的智能相机提供了动态处理能力,而无需对定制的视觉管道进行硬编码。
边缘 VLM:
VILA 与 NVIDIA Jetson Orin
要实现边缘 AI 2.0,VLM 必须具有高性能且易于部署。VILA 通过以下方式实现这两点:
精心设计的训练管道和高质量的混合数据
精度损失可忽略不计的 AWQ 4 位量化
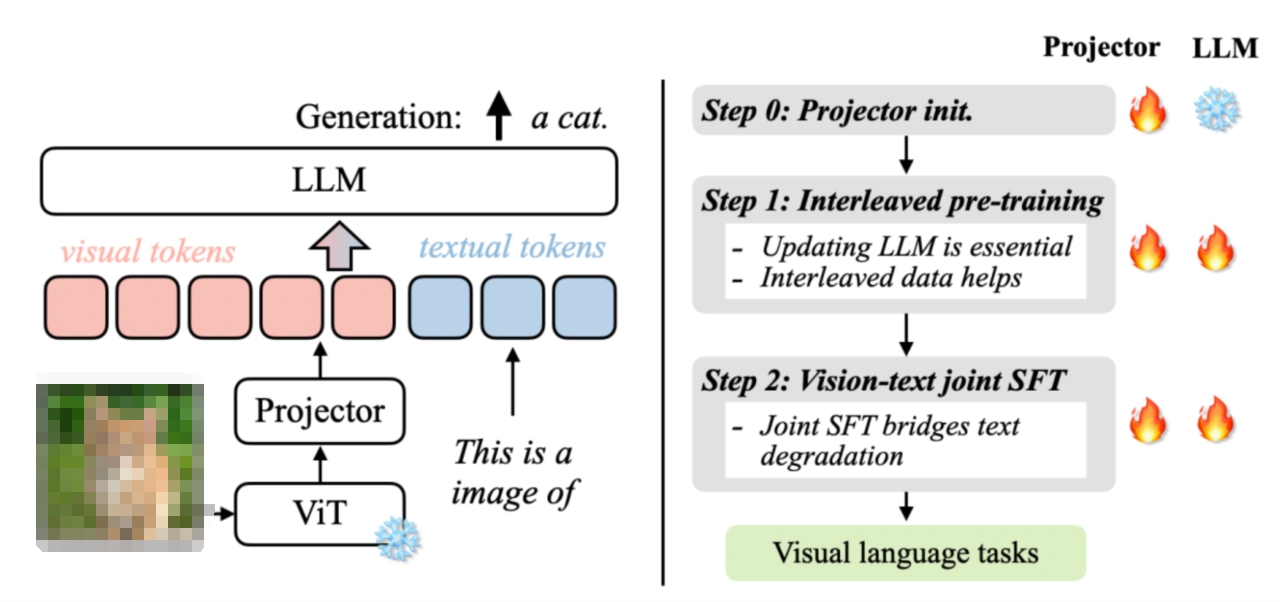
图 1. VILA 模型架构和训练配方
VILA 是一种可将视觉信息引入大语言模型(LLM)的视觉语言模型。VILA 模型由视觉编码器、LLM 和投影仪组成,可连接两种模态的嵌入。为了充分利用功能强大的 LLM,VILA 使用视觉编码器将图像或视频编码为视觉 token,然后将这些视觉 token 作为外语输入 LLM。这种设计可以处理任意数量的交错图像-文本输入。
VILA 的成功源于经过增强的预训练配方。通过对视觉语言模型预训练选择的深入研究,我们获得了三个重要发现:
在预训练过程中冻结 LLM 可以实现不错的零点性能,但缺乏语境学习能力,而这需要解冻 LLM;
交错的预训练数据是有益的,而单独的图像-文本对并不是最佳选择;
在指令微调过程中,将纯文本指令数据与图像-文本数据重新混合,不仅能弥补纯文本任务的不足,还能提高 VLM 任务的准确性。
我们观察到,该预训练过程解锁了模型的几项引人瞩目的能力:
多图像推理,尽管模型在 SFT 期间只能看到单个图像-文本对(监督微调)
更强的语境学习能力
增进的世界知识
NVIDIA Jetson Orin 具有无与伦比的 AI 计算、大容量统一内存和全面的 AI 软件堆栈,是在高能效边缘设备上部署 VILA 的完美平台。Jetson Orin 能够快速推理采用 transformer 架构的任何生成式 AI 模型,在 MLPerf 基准测试中展现出领先的边缘性能。
AWQ 量化
为了在 Jetson Orin 上部署 VILA,我们集成了激活感知权重量化(AWQ)以实现 4 位量化。AWQ 使我们能够将 VILA 量化到精度损失可忽略不计的 4 位精度,这为 VLM 在保持性能标准的同时还能深入改变边缘计算铺平了道路。
尽管采用了 AWQ 等先进技术,但在边缘设备上部署大语言和视觉模型仍然是一项复杂的任务。4 位权重缺乏字节对齐,需要专门的计算才能达到最佳效率。
TinyChat 是专为边缘设备上的 LLM 和 VLM 设计的高效推理框架。无论是 NVIDIA RTX 4070 笔记本电脑 GPU 还是 NVIDIA Jetson Orin,TinyChat 的适应性使其能够在各种硬件平台上运行,这引发了开源社区的极大兴趣。
现在,TinyChat 扩大了对 VILA 的支持,实现了对视觉数据的重要理解和推理。TinyChat 在结合文本和视觉处理方面具有出众的效率和灵活性,使边缘设备能够执行最前沿的多模态任务。
基准测试
下表显示了 VILA 1.5-3B 的基准测试结果。就其规模而言,它在图像质量保证和视频质量保证基准测试中均表现出色。您还可以看到,AWQ 4 位量化并没有降低精度,而且通过与 Scaling on Scales (S2) 集成,它可以感知更高分辨率的图像,并进一步提高性能。
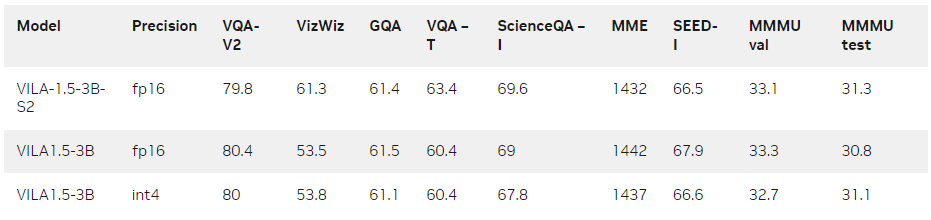
表 1. 模型在图像质量保证基准测试中的
评估结果(量化前/后)

表 2. 模型在视频质量保证基准测试中的评估结果
部署在 Jetson Orin 和 NVIDIA RTX 上
随着摄像头和视觉系统在现实环境中的应用日益普及,在边缘设备上推理 VILA 已成为一项重要的任务。根据模型的规模,从入门级 AI 到七种 Jetson Orin 高性能模块,您都可以选择,来灵活地为智能家居设备、医疗仪器、自主机器人和视频分析构建那些用户可以动态地重新配置和查询的生成式 AI 应用。
图 3 显示了在 Jetson AGX Orin 和 Jetson Orin Nano 上运行 VILA 的端到端多模态管道性能,两者都在视频流上达到了交互速率。
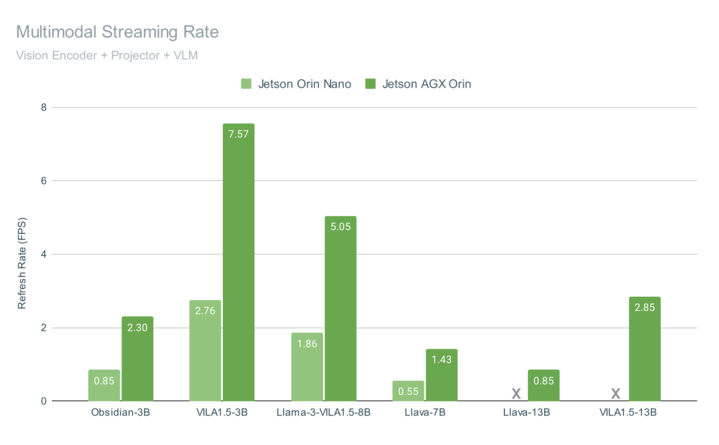
图 3. VILA 推理速度比较
这些基准测试包含查询 1 帧图像的总体时间,包括视觉编码(使用 CLIP 或 SigLIP)、多模态投影、聊天嵌入组装、使用 4 位量化生成语言模型输出等测试。VILA-1.5 模型包括一个新型适配器,可将用于表示每个图像嵌入的 token 数从 729 个减少到 196 个,这不仅提高了性能,而且在视觉编码器空间分辨率提高的情况下保持了准确性。
这一高度优化的 VLM 管道是开源的,并且集成了多模态 RAG 和单样本图像标记等先进功能,能够将图像嵌入高效率地重复用于整个系统中的其他视觉相关任务。
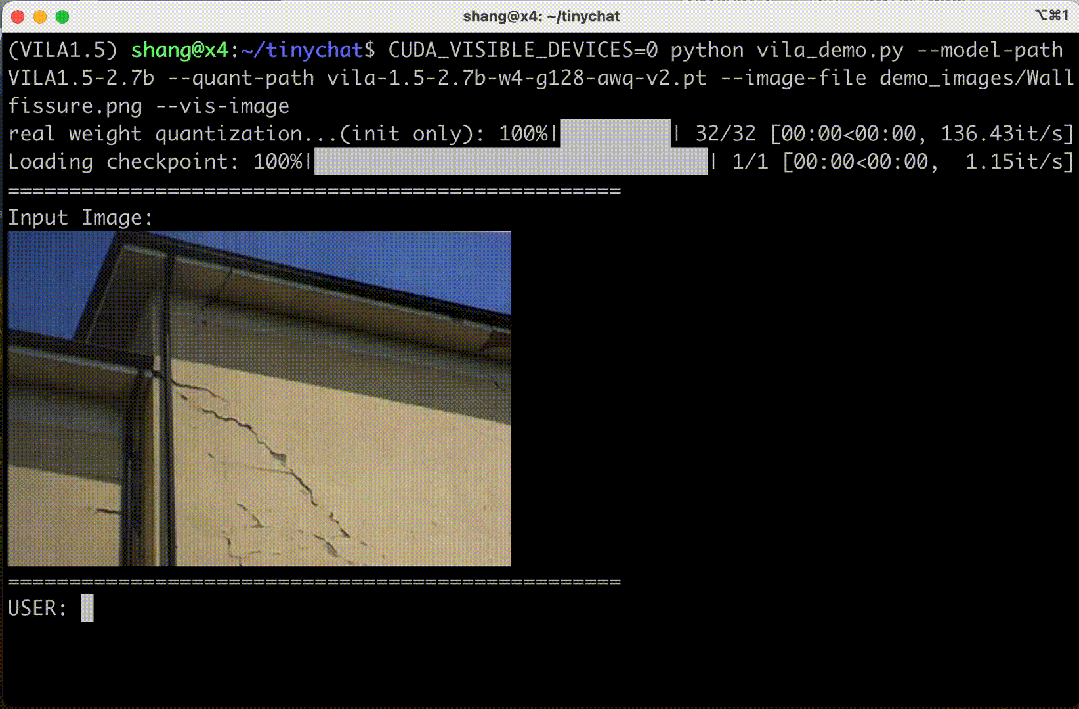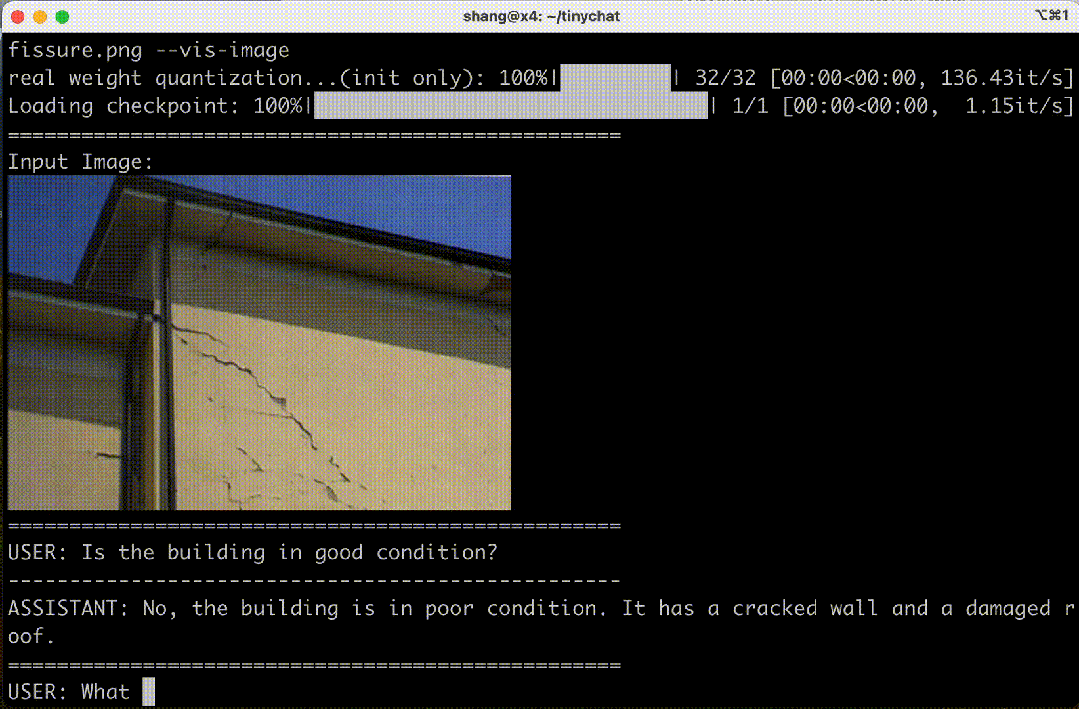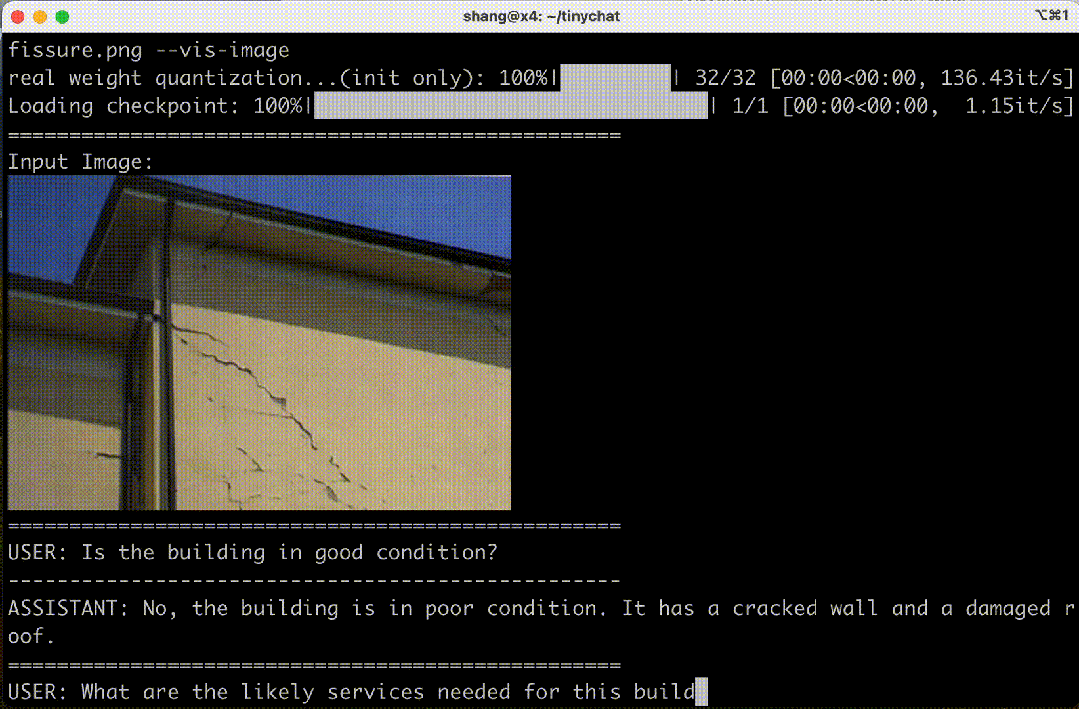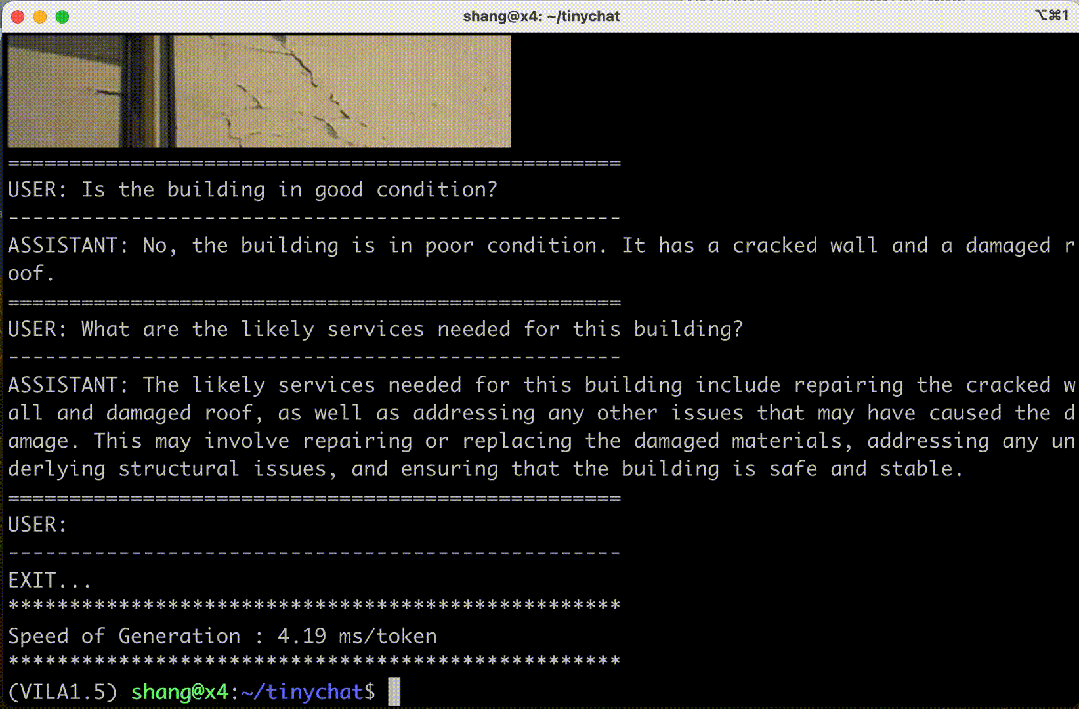
图 4. 在 Jetson Orin 上运行的 VILA-3B(4 位)
在消费级 GPU 上的体验
VILA 还可以部署在笔记本电脑和 PC 工作站上的 NVIDIA RTX 等消费级 GPU 中,以提高用户的工作效率和交互体验。

图 5. 在 NVIDIA RTX 4090 上运行的 VILA-3B(4 位)
多图像推理
TinyChat 的最新版本使用了 VILA 令人印象深刻的多图像推理功能,使您能够同时上传多张图像来增强交互,带来令人兴奋的创新可能性。
图 6 显示 VILA 可以理解图像序列的内容和顺序,为创造性应用开辟了新途径。
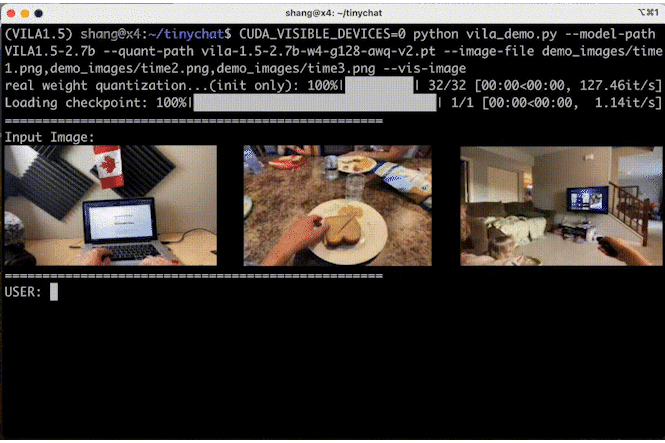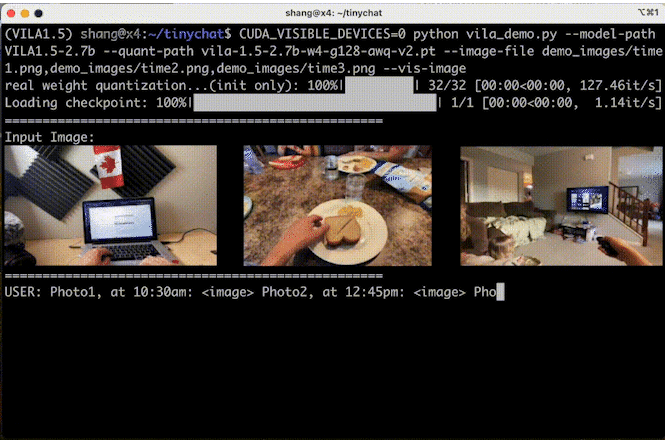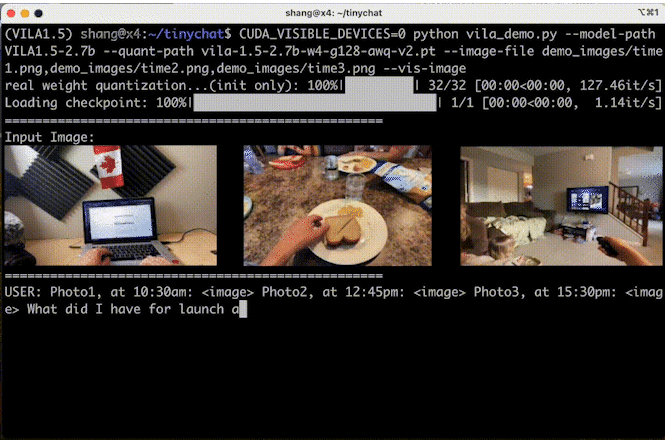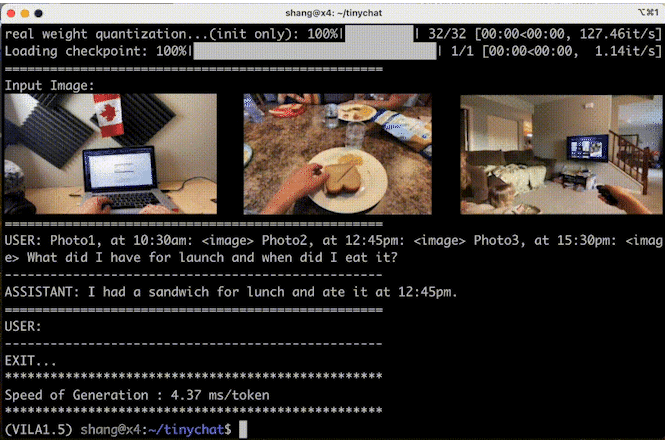
图 6. VILA-3B(4 位)在多图像理解方面的表现
语境学习
VILA 还具有出色的语境学习能力。无需明确的系统提示,VILA 就能从以前的图像-文本对中无缝推理出模式,为新的图像输入生成相关文本。
在图 7 中,VILA 成功识别了 NVIDIA 的徽标,并按照之前示例的风格输出了 NVIDIA 最著名的产品。
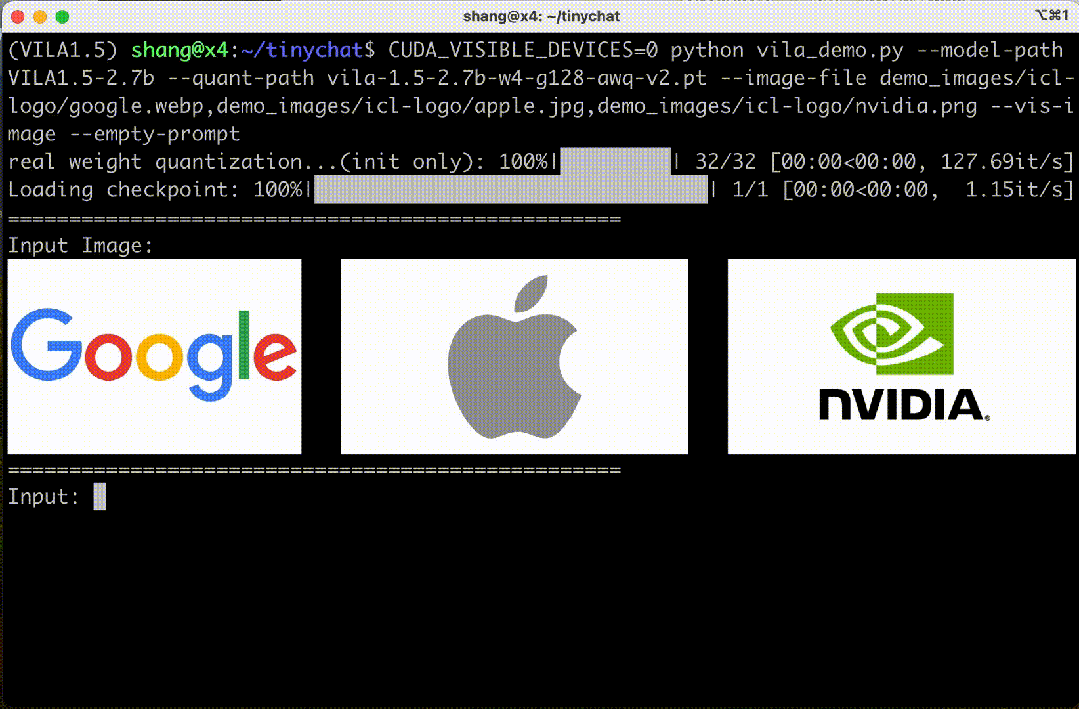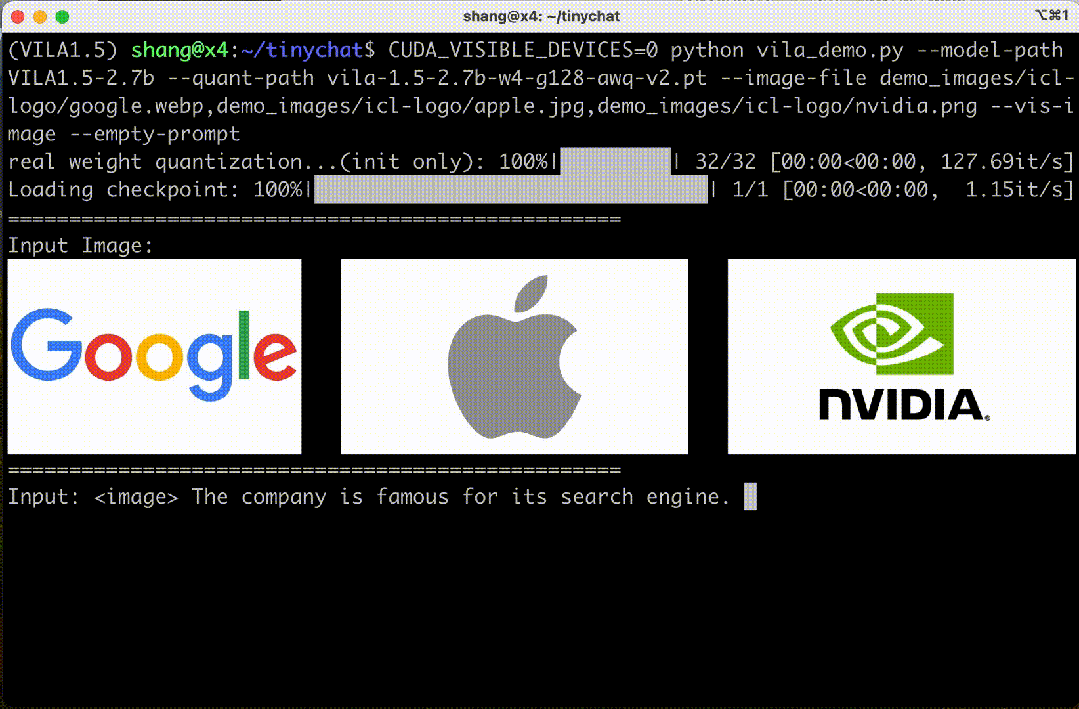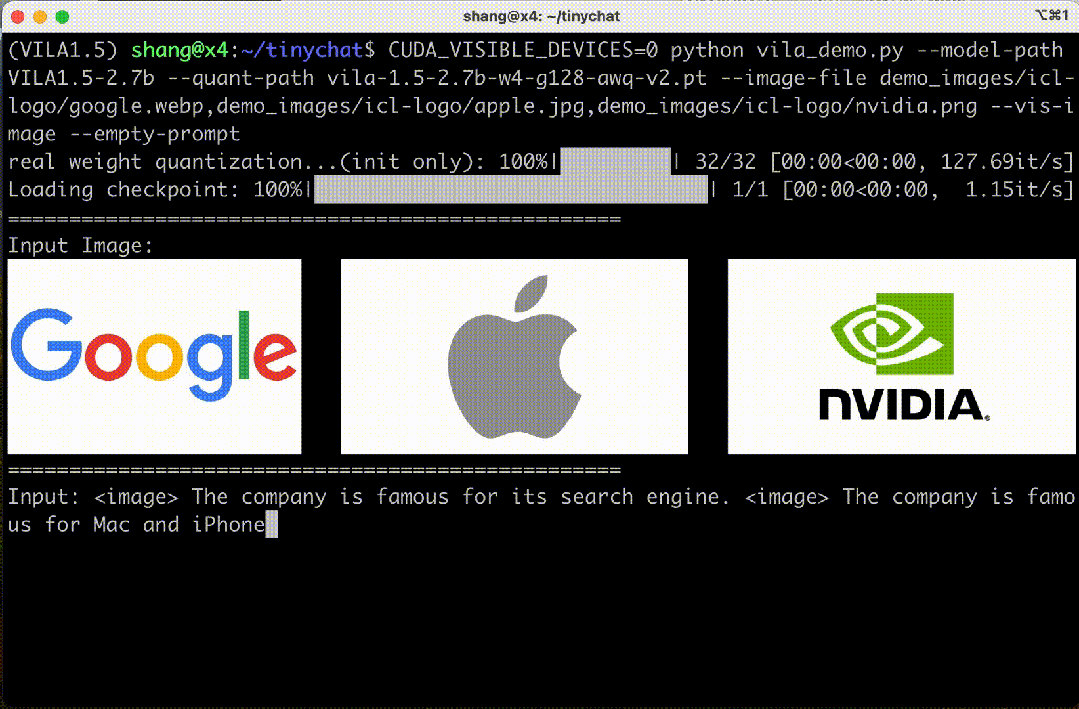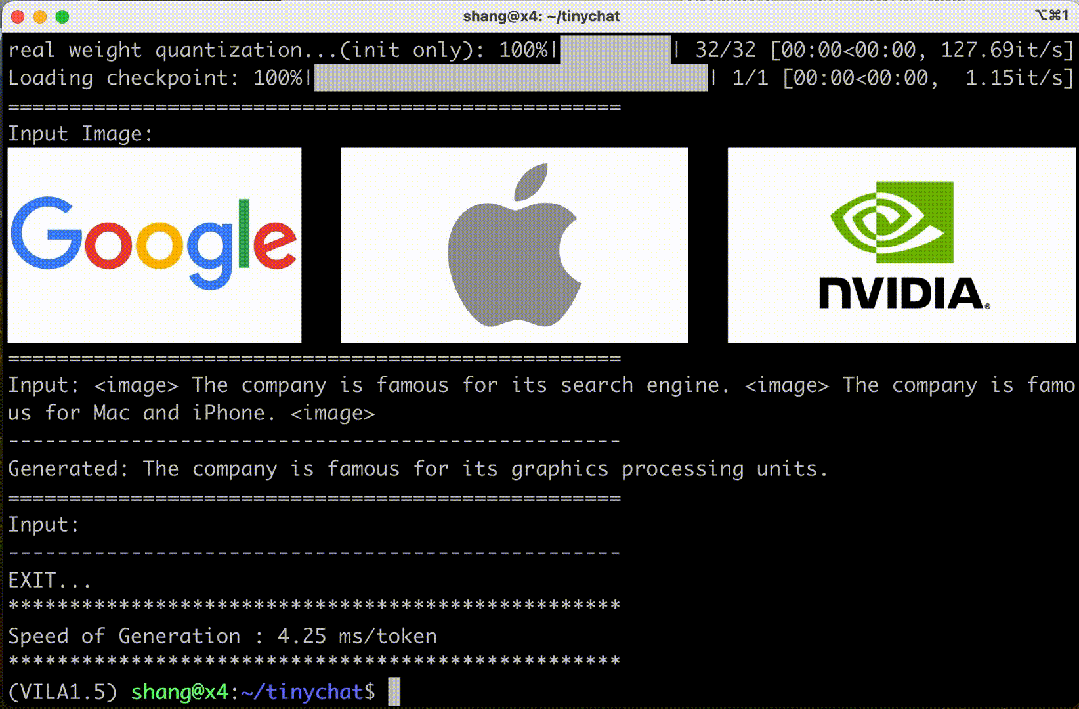
图 7. VILA-3B(4 位)在语境学习任务中的表现
开始使用 VILA
我们计划继续对 VILA 进行创新,包括扩展上下文长度、提高分辨率以及为视觉和语言对齐策划更好的数据集。
-
边缘AI应用越来越普遍,AI模型在边缘端如何部署?2023-07-04 4817
-
risc-v多核芯片在AI方面的应用2024-04-28 1001
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 2770
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1544
-
Deepseek海思SD3403边缘计算AI产品系统2025-04-28 8035
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 979
-
论马斯克的预言:AI使人类边缘化2026-03-14 1003
-
EdgeBoard FZ5 边缘AI计算盒及计算卡2020-08-31 2732
-
网络边缘实施AI的原因2021-02-23 1319
-
嵌入式边缘AI应用开发指南2022-11-03 1488
-
ST MCU边缘AI开发者云 - STM32Cube.AI2023-02-02 1316
-
NVIDIA收购ARM,加速了RISC-V在边缘AI的神经网路方面的应用2020-10-23 3061
-
边缘AI的模型压缩技术2022-10-19 2296
-
NVIDIA在加速识因智能AI大模型落地应用方面的重要作用介绍2024-03-29 1728
-
Llama 3 模型与其他AI工具对比2024-10-27 1998
全部0条评论

快来发表一下你的评论吧 !
