

围绕神经网络知识和网络应用方式展开Python和R语言实战编码
电子说
描述
编者按:当你面对一个新概念时,你会怎么学习和实践它?是耗费大量时间学习整个理论,掌握背后的算法、数学、假设、局限再亲身实践,还是从最简单的基础开始,通过具体项目解决一个个难题来提高你对它的整体把握?在这系列文章中,论智将采用第二种方法和读者一起从头理解机器学习。
“从零学习”系列第一篇从Python和R理解和编码神经网络来自Analytics Vidhya博主、印度资深数据科学开发人员SUNIL RAY。
本文将围绕神经网络构建的基础知识展开,并集中讨论网络的应用方式,用Python和R语言实战编码。
目录
神经网络的基本工作原理
多层感知器及其基础知识
神经网络具体步骤详解
神经网络工作过程的可视化
如何用Numpy实现NN(Python)
如何用R语言实现NN
反向传播算法的数学原理
神经网络的基本工作原理
如果你是一名开发者,或曾参与过编程项目,你一定知道如何在代码中找bug。通过改变输入和环境,你可以用相应的各种输出测试bug位置,因为输出的改变其实是一个提示,它能告诉你应该去检查哪个模块,甚至是哪一行。一旦你找到正确的那个它,并反复调试,你总会得到理想的结果。
神经网络其实也一样。它通常需要几个输入,在经过多个隐藏层中神经元的处理后,它会在输出层返回结果,这个过程就是神经网络的“前向传播”。
得到输出后,接下来我们要做的就是用神经网络的输出和实际结果做对比。由于每一个神经元都可能增加最终输出的误差,所以我们要尽可能减少这个损耗(loss),使输出更接近实际值。那该怎么减少loss呢?
在神经网络中,一种常用的做法是降低那些容易导致更多loss的神经元的权重/权值。因为这个过程需要返回神经元并找出错误所在,所以它也被称为“反向传播”。
为了在减少误差的同时进行更少量的迭代,神经网络也会使用一种名为“梯度下降”(Gradient Descent)的算法。这是一种基础的优化算法,能帮助开发者快速高效地完成各种任务。
虽然这样的表述太过简单粗浅,但其实这就是神经网络的基本工作原理。简单的理解有助于你用简单的方式去做一些基础实现。
多层感知器及其基础知识
就像原子理论中物质是由一个个离散单元原子所构成的那样,神经网络的最基本单位是感知器(Perceptron)。那么,感知器是什么?
对于这个问题,我们可以这么理解:感知器就是一种接收多个输入并产生一个输出的东西。如下图所示:
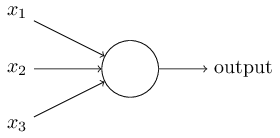
感知器
示例中的它有3个输入,却只有一个输出,由此我们产生的下一个合乎逻辑的问题就是输入和输出之间的对应关系是什么。让我们先从一些基本方法入手,再慢慢上升到更复杂的方法。
以下是我列举的3种创建输入输出对应关系的方法:
直接组合输入并根据阈值计算输出。例如,我们设x1=0,x2=1,x3=1,阈值为0。如果x1+x2+x3>0,则输出1;反之,输出0。可以看到,在这个情景下上图的最终输出是1。
接下来,让我们为各输入添加权值。例如,我们设x1、x2、x3三个输入的权重分别为w1、w2、w3,其中w1=2,w2=3,w3=4。为了计算输出,我们需要将输入乘以它们各自的权值,即2x1+3x2+4x3,再和阈值比较。可以发现,x3对输出的影响比x1、x2更大。
接下来,让我们添加bias(偏置,有时也称阈值,但和上文阈值有区别)。每个感知器都有一个bias,它其实也是一种加权方式,可以反映感知器的灵活性。bias在某种程度上相当于线性方程y=ax+b中的常数b,可以让函数上下移动。如果b=0,那分类线就要经过原点(0,0),这样神经网络的fit范围会非常受限。例如,如果一个感知器有两个输入,它就需要3个权值,两个对应给输入,一个给bias。在这个情景下,上图输入的线性形式就是w1x1 + w2x2 + w3x3+1×b。
但是,这样做之后每一层的输出还是上层输入的线性变换,这就有点无聊。于是人们想到把感知器发展成一种现在称之为神经元的东西,它能将非线性变换(激活函数)用于输入和loss。
什么是激活函数(activation function)?
激活函数是把加权输入(w1x1 + w2x2 + w3x3+1×b)的和作为自变量,然后让神经元得出输出值。
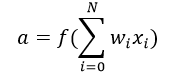
在上式中,我们将bias权值1表示为x0,将b表示为w0.
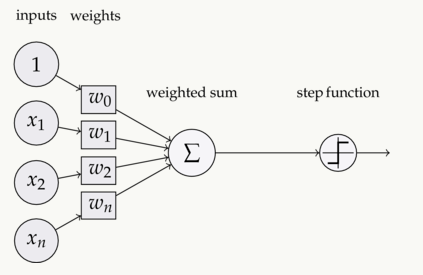
输入—加权—求和—作为实参被激活函数计算—输出
它主要用于进行非线性变换,使我们能拟合非线性假设、估计复杂函数,常用的函数有:Sigmoid、Tanh和ReLu。
前向传播、反向传播和Epoch
到目前为止,我们已经由输入计算获得了输出,这个过程就是“前向传播”(Forward Propagation)。但是,如果产出的估计值和实际值误差太大怎么办?其实,神经网络的工作过程可以被看作是一个试错的过程,我们能根据输出值的错误更新之前的bias和权值,这个回溯的行为就是“反向传播”(Back Propagation)。
反向传播算法(BP算法)是一种通过权衡输出层的loss或错误,将其传回网络来发生作用的算法。它的目的是重新调整各项权重来使每个神经元产生的loss最小化,而要实现这一点,我们要做的第一步就是基于最终输出计算每个节点之的梯度(导数)。具体的数学过程我们会在最后一节“反向传播算法的数学原理”中详细探讨。
而这个由前向传播和反向传播构成的一轮迭代就是我们常说的一个训练迭代,也就是Epoch。
多层感知器
现在,让我们继续回到例子,把注意力放到多层感知器上。截至目前,我们看到的只有一个由3个输入节点x1、x2、x3构成的单一输入层,以及一个只包含单个神经元的输出层。诚然,如果是解决线性问题,单层网络确实能做到这一步,但如果要学习非线性函数,那我们就需要一个多层感知器(MLP),即在输入层和输出层之间插入一个隐藏层。如下图所示:
图片中的绿色部分表示隐藏层,虽然上图只有一个,但事实上,这样一个网络可以包含多个隐藏层。同时,需要注意的一点是,MLP至少由三层节点组成,并且所有层都是完全连接的,即每一层中(除输入层和输出层)的每一个节点都要连接到前/后层中的每个节点。
理解了这一点,我们就能进入下一个主题,即神经网络优化算法(误差最小化)。在这里,我们主要介绍最简单的梯度下降。
批量梯度下降和随机梯度下降
梯度下降一般有三种形式:批量梯度下降法(Batch Gradient Descent)随机梯度下降法(Stochastic Gradient Descent)和小批量梯度下降法(Mini-Batch Gradient Descent)。由于本文为入门向,我们就先来了解满批量梯度下降法(Full BGD)和随机梯度下降法(SGD)。
这两种梯度下降形式使用的是同一种更新算法,它们通过更新MLP的权值来达到优化网络的目的。不同的是,满批量梯度下降法通过反复更新权值来使误差降低,它的每一次更新都要用到所有训练数据,这在数据量庞大时会耗费太多时间。而随机梯度下降法则只抽取一个或多个样本(非所有数据)来迭代更新一次,较之前者,它在耗时上有不小的优势。
让我们来举个例子:假设现在我们有一个包含10个数据点的数据集,它有w1、w2两个权值。
满批量梯度下降法:你需要用10个数据点来计算权值w1的变化情况Δw1,以及权值w2的变化情况Δw2,之后再更新w1、w2。
随机梯度下降法:用1个数据点计算权值w1的变化情况Δw1和权值w2的变化情况Δw2,更新w1、w2并将它们用于第二个数据点的计算。
-
Python自动训练人工神经网络2024-07-19 1214
-
如何使用Python进行神经网络编程2024-07-02 1524
-
卷积神经网络python代码2023-08-21 1892
-
用Python从头实现一个神经网络来理解神经网络的原理12023-02-27 1425
-
什么是神经网络?什么是卷积神经网络?2023-02-23 5190
-
如何构建神经网络?2021-07-12 1973
-
神经网络基础知识2021-04-21 1022
-
神经网络理论到实践(2):理解并实现反向传播及验证神经网络是否正确2020-12-10 1402
-
BP神经网络的基础数学知识分享2020-06-16 2294
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3275
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 3937
-
labview BP神经网络的实现2017-02-22 14394
全部0条评论

快来发表一下你的评论吧 !
