

自然语言处理常用模型解析
人工智能
描述
自然语言处理常用模型解析
一、N元模型
思想:
如果用变量W代表一个文本中顺序排列的n个词,即W = W1W2…Wn ,则统计语言 模型的任务是给出任意词序列W 在文本中出现的概率P(W)。利用概率的乘积公式,P(W)可展开为:P(W) = P(w1)P(w2|w1)P(w3| w1 w2)…P(wn|w1 w2…wn-1),不难看出,为了预测词Wn的出现概率,必须已知它前面所有词的出现概率。从计算上来看,这太复杂了。如果任意一个词Wi的出现概率只同它前面的N-1个词有关,问题就可以得到很大的简化。 这时的语言模型叫做N元模型 (N-gram),即P(W) = P(w1)P(w2|w1)P(w3| w1 w2)…P(wi|wi-N+1…wi-1)…实际使用的通常是N=2 或N=3的二元模型(bi-gram)或三元模型(tri-gram)。以三元模型为例,近似认为任意词Wi的出现概率只同它紧接的前面的两个词有关。重要的是这些概率参数都是可以通过大规模语料库来估值的。比如三元概率有P(wi|wi-2wi-1) ≈ count(wi-2 wi-1… wi) / count(wi-2 wi-1)式中count(…) 表示一个特定词序列在整个语料库中出现的累计次数。统计语言模型有点像天气预报的方法。用来估计概率参数的大规模语料库好比是一个地区历年积累起来的气象纪录,而用三元模型来做天气预报,就像是根据前两天的天气情况来预测今天的天气。天气预报当然不可能百分之百正确。这也算是概率统计方法的一个特点吧。(摘自黄昌宁论文《中文信息处理的主流技术是什么?》)
条件: 该模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其 它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
问题:
虽然我们知道元模型中, n越大约束力越强,但由于计算机容量和速度的限制 及数据的稀疏,很难进行大n的统计。
二、马尔可夫模型以及隐马尔可夫模型
思想: 马尔可夫模型实际上是个有限状态机,两两状态间有转移概率;隐马尔可夫模型中状态不可见,我们只能看到输出序列,也就是每次状态转移会抛出个观测值;当我们观察到观测序列后,要找到最佳的状态序列。隐马尔科夫模型是一种用参数表示的用于描述随机过程统计特性的概率模型,是一个双重随机过程,由两个部分组成:马尔科夫链和一般随机过程。其中马尔科夫链用来描述状态的转移,用转移概率描述。一般随机过程用来描述状态与观察序列之间的关系,用观察值概率描述。因此,隐马尔可夫模型可以看成是能够随机进行状态转移并输出符号的有限状态自动机,它通过定义观察序列和状态序列的联合概率对随机生成过程进行建模。每一个观察序列可以看成是由一个状态转移序列生成,状态转移过程是依据初始状态概率分布随机选择一个初始状态开始,输出一个观察值后再根据状态转移概率矩阵随机转移到下一状态,直到到达某一预先指定的结束状态为止,在每一个状态将根据输出概率矩阵随机输出一个观察序列的元素。
一个 HMM有 5个组成部分,通常记为一个五元组{S,K, π,A,B},有时简写为一个三元组{π ,A,B},其中:①S是模型的状态集,模型共有 N个状态,记为 S={s1,s2, ⋯,sN};②K是模型中状态输出符号的集合,符号数为 M,符号集记为K={k1,k2,⋯,kM};③是初始状态概率分布,记为 ={ 1, 2,⋯, N},其中 i是状态 Si作为初始状态的概率;④A是状态转移概率矩阵,记为A={aij},1≤i≤N,1≤j≤N。其中 aij是从状态 Si转移到状态 Sj的概率;⑤B是符号输出概率矩阵,记为B={bik},1≤i≤N,1≤k≤M。其中 bik是状态 Si输出 Vk的概率。要用HMM解决实际问题,首先需要解决如下 3个基本问题:①给定一个观察序列 O=O1O2⋯OT和模型{ π,A,B},如何高效率地计算概率P(O|λ),也就是在给定模型的情况下观察序列O的概率;②给定一个观察序列 O=O1O2⋯OT和模型{ π,A,B},如何快速地选择在一定意义下“最优”的状态序列Q=q1q2⋯qT,使得该状态序列“最好地解释”观察序列;③给定一个观察序列 O=O1O2⋯OT,以及可能的模型空间,如何来估计模型参数,也就是说,如何调节模型{π,A,B}的参数,使得 P(O|λ)最大。
问题:
隐马模型中存在两个假设:输出独立性假设和马尔可夫性假设。其中,输出独立性假设要求序列数据严格相互独立才能保证推导的正确性,而事实上大多数序列数据不能被表示成一系列独立事件。 三、最大熵模型 最大熵原理原本是热力学中一个非常重要的原理,后来被广泛应用于自然语言处理方面。其基本原理很简单:对所有的已知事实建模,对未知不做任何假设。也就是建模时选择这样一个统计概率模型,在满足约束的模型中选择熵最大的概率模型。若将词性标注或者其他自然语言处理任务看作一个随机过程,最大熵模型就是从所有符合条件的分布中,选择最均匀的分布,此时熵值最大。 求解最大熵模型,可以采用拉格朗日乘数法,其计算公式为:
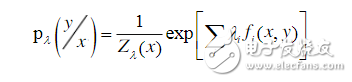
为归一化因子 ,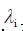 是对应特征的权重,
是对应特征的权重,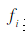 表示一个特征。每个特征对词性选择的影响大小由特征权重
表示一个特征。每个特征对词性选择的影响大小由特征权重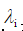 决定,而这些权值可由GIS或IIS 学习算法自动得到。
决定,而这些权值可由GIS或IIS 学习算法自动得到。
三、支持向量机
原理:支持向量机的主要思想可以概括为两点: (1) 它是针对线性可分情况进行分析,对于线性不可分的情况, 通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能; (2) 它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。 支持向量机的目标就是要根据结构风险最小化原理,构造一个目标函数将两类模式尽可能地区分开来, 通常分为两类情况来讨论,:(1) 线性可分;(2) 线性不可分。
线性可分情况 在线性可分的情况下,就会存在一个超平面使得训练样本完全分开,该超平面可描述为: w ·x + b = 0 (1) 其中,“·”是点积, w 是n 维向量, b 为偏移量。
最优超平面是使得每一类数据与超平面距离最近的向量与超平面之间的距离最大的这样的平面。
最优超平面可以通过解下面的二次优化问题来获得:
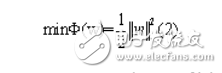
满足约束条件: 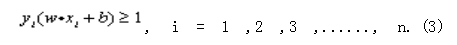
在特征数目特别大的情况,可以将此二次规划问题转化为其对偶问题:
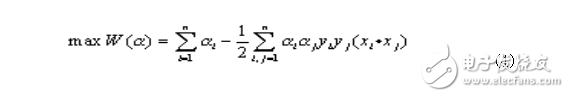

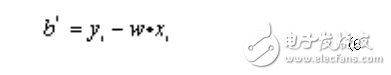
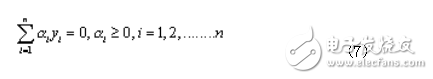
满足约束条件:

线性不可分的情况 对于线性不可分的情况,可以把样本X 映射到一个高维特征空间H,并在此空间中运用原空间的函 数来实现内积运算,这样将非线性问题转换成另一空间的线性问题来获得一个样本的归属。 根据泛函的有关理论,只要一种核函数满足Mercer 条件,它就对应某一空间中的内积,因此只要在最优分类面上采用适当的内积函数就可以实现这种线性不可分的分类问题。 此时的目标函数为:图十二
特点:
概括括地说,支持向量机就是首先通过内积函数定义的非线性变换将输入空间变换到另一个高维空间,在这个空间中求最优分类面。SVM分类函数形式上类似于一个神经网络,输出是中间节点的线性组合,每个中间节点对应一个输入样本与一个支持向量的内积,因此也叫做支持向量网络。 SVM方法的特点: ① 非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射; ② 对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心; ③ 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。 SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。 SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种 “鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响; ②支持向量样本集具有一定的鲁棒性; ③有些成功的应用中,SVM 方法对核的选取不敏感
四、条件随机场 原理: 条件随机场(CRFs)是一种基于统计的序列标记识别模型,由John Lafferty等人在2001年首次提出。它是一种无向图模型,对于指定的节点输入值,它能够计算指定的节点输出值上的条件概率,其训练目标是使得条件概率最大化。线性链是CRFs中常见的特定图结构之一,它由指定的输出节点顺序链接而成。一个线性链与一个有限状态机相对应,可用于解决序列数据的标注问题。在多数情况下,CRFs均指线性的CRFs。用x=(x1,x2,…,xn)表示要进行标注的数据序列,y=(y1,y2,…,yn)表示对应的结果序列。例如对于中文词性标注任务,x可以表示一个中文句子x=(上海,浦东,开发,与,法制,建设,同步),y则表示该句子中每个词的词性序列y=(NR,NR,NN,CC,NN,NN,VV)。 对于(X,Y),C由局部特征向量f和对应的权重向量λ确定。对于输入数据序列x和标注结果序列y,条件随机场C的全局特征表示为

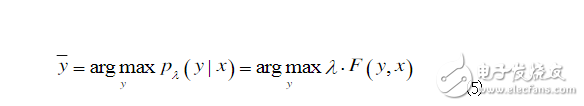
CRFs模型的参数估计通常采用L—BFGS算法实现,CRFs解码过程,也就是求解未知串标注的过程,需要搜索计算该串上的一个最大联合概率,解码过程采用Viterbi算法来完成。 CRFs具有很强的推理能力,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得模型能够获取的信息非常丰富。CRFs通过仅使用一个指数模型作为在给定观测序列条件下整个标记序列的联合概率,使得该模型中不同状态下的不同特征权值可以彼此交替,从而有效地解决了其他非生成有向图模型所产生的标注偏置的问题。这些特点,使得CRFs从理论上讲,非常适合中文词性标注。
总结
首先,CRF,HMM(隐马模型)都常用来做序列标注的建模,像词性标注,True casing。但隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择,而另外一种称为最大熵隐马模型则解决了这一问题,可以任意的选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题(label bias),即凡是训练语料中未出现的情况全都忽略掉,而条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。目前,条件随机场的训练和解码的开源工具还只支持链式的序列,复杂的尚不支持,而且训练时间很长,但效果还可以。最大熵隐马模型的局限性在于其利用训练的局部模型去做全局预测。其最优预测序列只是通过viterbi算法将局部的最大熵模型结合而成的。 条件随机场,隐马模型,最大熵隐马模型这三个模型都可以用来做序列标注模型。但是其各自有自身的特点,HMM模型是对转移概率和表现概率直接建模,统计共现概率。而最大熵隐马模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率。
中,统计了全局概率,在 做归一化时,考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。
- 相关推荐
- 自然语言处理
-
python自然语言2018-05-02 0
-
自然语言处理怎么最快入门?2018-11-28 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
关于自然语言处理之54 语言模型(自适应)2020-04-09 0
-
自然语言处理的语言模型2020-04-16 0
-
自然语言处理的词性标注方法2020-04-21 0
-
自然语言处理——总结、习题2020-06-19 0
-
什么是自然语言处理2021-09-08 0
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18310
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5312
-
自然语言处理的优点有哪些_自然语言处理的5大优势2017-12-29 28043
-
自然语言处理的ELMO使用2019-05-02 3336
-
基于深度学习的自然语言处理对抗样本模型2021-04-20 817
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 1650
-
自然语言处理与机器学习的关系 自然语言处理的基本概念及步骤2024-12-05 496
全部0条评论

快来发表一下你的评论吧 !
