

什么是自然语言处理_自然语言处理常用方法举例说明
人工智能
描述
自然语言处理简介
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
自然语言处理详细介绍
语言是人类区别其他动物的本质特性。在所有生物中,只有人类才具有语言能力。人类的多种智能都与语言有着密切的关系。人类的逻辑思维以语言为形式,人类的绝大部分知识也是以语言文字的形式记载和流传下来的。因而,它也是人工智能的一个重要,甚至核心部分。
用自然语言与计算机进行通信,这是人们长期以来所追求的。因为它既有明显的实际意义,同时也有重要的理论意义:人们可以用自己最习惯的语言来使用计算机,而无需再花大量的时间和精力去学习不很自然和习惯的各种计算机语言;人们也可通过它进一步了解人类的语言能力和智能的机制。
实现人机间自然语言通信意味着要使计算机既能理解自然语言文本的意义,也能以自然语言文本来表达给定的意图、思想等。前者称为自然语言理解,后者称为自然语言生成。因此,自然语言处理大体包括了自然语言理解和自然语言生成两个部分。历史上对自然语言理解研究得较多,而对自然语言生成研究得较少。但这种状况已有所改变。
无论实现自然语言理解,还是自然语言生成,都远不如人们原来想象的那么简单,而是十分困难的。从现有的理论和技术现状看,通用的、高质量的自然语言处理系统,仍然是较长期的努力目标,但是针对一定应用,具有相当自然语言处理能力的实用系统已经出现,有些已商品化,甚至开始产业化。典型的例子有:多语种数据库和专家系统的自然语言接口、各种机器翻译系统、全文信息检索系统、自动文摘系统等。
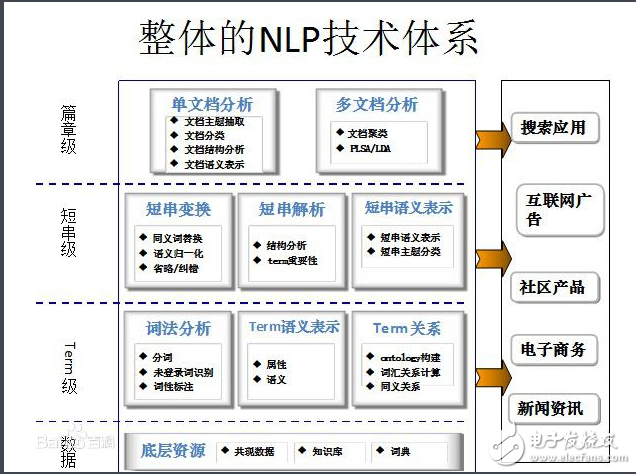
自然语言处理,即实现人机间自然语言通信,或实现自然语言理解和自然语言生成是十分困难的。造成困难的根本原因是自然语言文本和对话的各个层次上广泛存在的各种各样的歧义性或多义性。
一个中文文本从形式上看是由汉字(包括标点符号等)组成的一个字符串。由字可组成词,由词可组成词组,由词组可组成句子,进而由一些句子组成段、节、章、篇。无论在上述的各种层次:字(符)、词、词组、句子、段,……还是在下一层次向上一层次转变中都存在着歧义和多义现象,即形式上一样的一段字符串,在不同的场景或不同的语境下,可以理解成不同的词串、词组串等,并有不同的意义。一般情况下,它们中的大多数都是可以根据相应的语境和场景的规定而得到解决的。也就是说,从总体上说,并不存在歧义。这也就是我们平时并不感到自然语言歧义,和能用自然语言进行正确交流的原因。但是一方面,我们也看到,为了消解歧义,是需要极其大量的知识和进行推理的。如何将这些知识较完整地加以收集和整理出来;又如何找到合适的形式,将它们存入计算机系统中去;以及如何有效地利用它们来消除歧义,都是工作量极大且十分困难的工作。这不是少数人短时期内可以完成的,还有待长期的、系统的工作。
以上说的是,一个中文文本或一个汉字(含标点符号等)串可能有多个含义。它是自然语言理解中的主要困难和障碍。反过来,一个相同或相近的意义同样可以用多个中文文本或多个汉字串来表示。
因此,自然语言的形式(字符串)与其意义之间是一种多对多的关系。其实这也正是自然语言的魅力所在。但从计算机处理的角度看,我们必须消除歧义,而且有人认为它正是自然语言理解中的中心问题,即要把带有潜在歧义的自然语言输入转换成某种无歧义的计算机内部表示。
歧义现象的广泛存在使得消除它们需要大量的知识和推理,这就给基于语言学的方法、基于知识的方法带来了巨大的困难,因而以这些方法为主流的自然语言处理研究几十年来一方面在理论和方法方面取得了很多成就,但在能处理大规模真实文本的系统研制方面,成绩并不显著。研制的一些系统大多数是小规模的、研究性的演示系统。
目前存在的问题有两个方面:一方面,迄今为止的语法都限于分析一个孤立的句子,上下文关系和谈话环境对本句的约束和影响还缺乏系统的研究,因此分析歧义、词语省略、代词所指、同一句话在不同场合或由不同的人说出来所具有的不同含义等问题,尚无明确规律可循,需要加强语用学的研究才能逐步解决。另一方面,人理解一个句子不是单凭语法,还运用了大量的有关知识,包括生活知识和专门知识,这些知识无法全部贮存在计算机里。因此一个书面理解系统只能建立在有限的词汇、句型和特定的主题范围内;计算机的贮存量和运转速度大大提高之后,才有可能适当扩大范围。
以上存在的问题成为自然语言理解在机器翻译应用中的主要难题,这也就是当今机器翻译系统的译文质量离理想目标仍相差甚远的原因之一;而译文质量是机译系统成败的关键。中国数学家、语言学家周海中教授曾在经典论文《机器翻译五十年》中指出:要提高机译的质量,首先要解决的是语言本身问题而不是程序设计问题;单靠若干程序来做机译系统,肯定是无法提高机译质量的;另外在人类尚未明了大脑是如何进行语言的模糊识别和逻辑判断的情况下,机译要想达到“信、达、雅”的程度是不可能的。
自然语言处理常用方法举例说明
自然语言处理或者是文本挖掘以及数据挖掘,近来一直是研究的热点。很多人相想数据挖掘,或者自然语言处理,就有一种莫名的距离感。其实,走进去你会发现它的美,它在现实生活中解决难题的应用之美,跟它相结合的数学之美,还有它与统计学的自然融合。语言只是一种实现工具,真正难度的是模型的理解和对模型的构建。
下面将举例自然语言常用方法小结(JAVA实现,C#类似)
1、实体的基本使用

2、批量读取目录下的文件

3、读取单个文件

4 文件预处理,并以字符串结果返回

5 指定保存文件
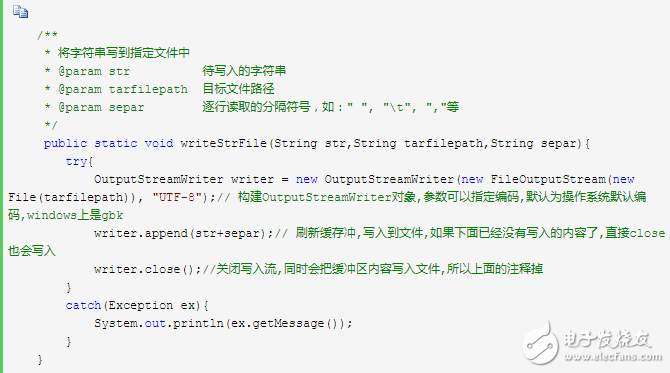
6 词频排序(中英文通用)
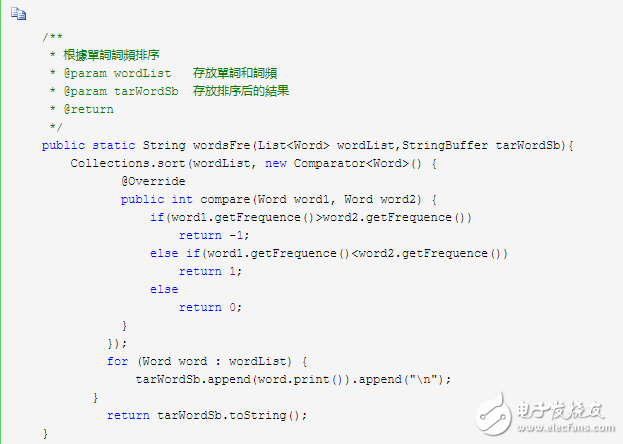
7 根据字符有序排列

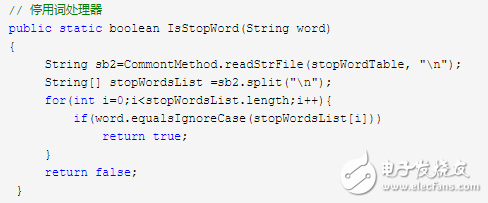
8 停用词处理如何判断?
扩展改进与移植展望:
本项目由于实际需求,对其做了初步完善。基本自然语言处理方法和流程都包含了,诸如词频统计,停用词处理,单词统计,还有文件的基本操作,再结合数学模型或者统计模型可以做复杂的自然语言或者文本处理。比如朴素贝叶斯分类,首先弄明白贝叶斯分类模型,其实就是对贝叶斯公式的理解和推导。之后结合本项目词频统计文件操作,数据清洗,中文分词,停用词处理就做出来了。再如,本体构建,也是需要对数据清洗,词频统计,结果发射概率和转移概率,文本标注等实现。
至于本算法改进,可以对翻译部分改进,一种基于词库的检索,包括词性,词义,词标等匹配。另外一种是对英文词组的分词处理,利用英文分词解决。移植方面,可以利用C#语言在窗体上开发,最后打包应用软件。
- 相关推荐
- 自然语言处理
-
python自然语言2018-05-02 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
自然语言处理的分词方法2020-03-19 0
-
自然语言处理的语言模型2020-04-16 0
-
自然语言处理的词性标注方法2020-04-21 0
-
求自然语言处理笔记2020-06-04 0
-
自然语言处理——总结、习题2020-06-19 0
-
什么是自然语言处理?2021-07-23 0
-
什么是自然语言处理2021-09-08 0
-
自然语言处理常用模型解析2017-12-28 5886
-
自然语言处理怎么最快入门_自然语言处理知识了解2017-12-28 5311
-
自然语言处理(NLP)的学习方向2020-07-06 13178
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 1608
-
自然语言处理和人工智能的概念及发展史 自然语言处理和人工智能的区别2023-08-23 999
-
自然语言处理包括哪些内容2024-07-03 859
全部0条评论

快来发表一下你的评论吧 !
