

hadoop基础知识介绍_hadoop是什么语言开发的_hadoop能做什么
编程语言及工具
描述
一、hadoop是什么?
(1)Hadoop是一个开发和运行处理大规模数据的软件平台,可编写和运行分布式应用处理大规模数据,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算(或专为离线和大规模数据分析而设计的)并不适合那种对几个记录随机读写的在线事务处理模式。
Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。
(2)Hadoop就是一个分布式计算的解决方案。
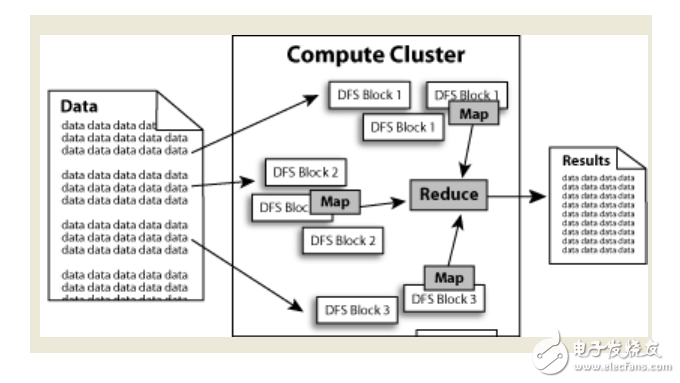
Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,MapReduce提供了对数据的计算。
数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果。
优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。.
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库。
hadoop能做什么?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的 自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
下面举例说明:
设想一下这样的应用场景。 我有一个100M 的数据库备份的sql 文件。我现在想在不导入到数据库的情况下直接用grep操作通过正则过滤出我想要的内容。例如:某个表中 含有相同关键字的记录那么有几种方式,一种是直接用linux的命令 grep 还有一种就是通过编程来读取文件,然后对每行数据进行正则匹配得到结果好了 现在是100M 的数据库备份。上述两种方法都可以轻松应对。
那么如果是1G , 1T 甚至 1PB 的数据呢 ,上面2种方法还能行得通吗? 答案是不能。毕竟单台服务器的性能总有其上限。那么对于这种 超大数据文件怎么得到我们想要的结果呢?
有种方法 就是分布式计算, 分布式计算的核心就在于 利用分布式算法 把运行在单台机器上的程序扩展到多台机器上并行运行。从而使数据处理能力成倍增加。但是这种分布式计算一般对编程人员要求很高,而且对服务器也有要求。导致了成本变得非常高。
Haddop 就是为了解决这个问题诞生的.Haddop 可以很轻易的把 很多linux的廉价pc 组成 分布式结点,然后编程人员也不需要知道分布式算法之类,只需要根据mapreduce的规则定义好接口方法,剩下的就交给Haddop. 它会自动把相关的计算分布到各个结点上去,然后得出结果。
例如上述的例子 : Hadoop 要做的事 首先把 1PB的数据文件导入到 HDFS中, 然后编程人员定义好 map和reduce, 也就是把文件的行定义为key,每行的内容定义为value , 然后进行正则匹配,匹配成功则把结果 通过reduce聚合起来返回.Hadoop 就会把这个程序分布到N 个结点去并行的操作。
那么原本可能需要计算好几天,在有了足够多的结点之后就可以把时间缩小到几小时之内。
这也就是所谓的 大数据 云计算了。如果还是不懂的话再举个简单的例子
比如 1亿个 1 相加 得出计算结果, 我们很轻易知道结果是 1亿。但是计算机不知道。那么单台计算机处理的方式做一个一亿次的循环每次结果+1
那么分布式的处理方式则变成 我用 1万台 计算机,每个计算机只需要计算 1万个 1 相加 然后再有一台计算机把 1万台计算机得到的结果再相加从而得到最后的结果。
理论上讲, 计算速度就提高了 1万倍。 当然上面可能是一个不恰当的例子。但所谓分布式,大数据,云计算 大抵也就是这么回事了。
hadoop是什么语言开发的
(1)Hadoop的创始人是Doug Cutting, 同时也是著名的基于Java的检索引擎库Apache Lucene的创始人。Hadoop本来是用于著名的开源搜索引擎Apache Nutch,而Nutch本身是基于Lucene的,而且也是Lucene的一个子项目。因此Hadoop基于Java就很理所当然了。
(2)用其他语言开发的Hadoop应用大多数是使用Hadoop-Streaming来和框架对接的。 因为Streaming会fork一个java进程来读写Python/Perl/C++的stdin/stdout,开销会大一些。较大的任务、长期运行的任务,推荐使用Java。
- 相关推荐
- 热点推荐
- Hadoop
-
Hadoop新手篇:hadoop入门基础教程2019-01-09 2692
-
大数据hadoop入门之hadoop家族产品详解2018-12-26 3031
-
Hadoop基础入门之发行版本的选择2018-11-28 3015
-
hadoop框架结构的说明介绍2018-10-15 3437
-
Hadoop的集群环境部署说明2018-10-12 2671
-
学hadoop需要什么基础2018-09-20 4055
-
hadoop不同版本有哪些2018-09-18 2177
-
学习hadoop需要什么基础2018-09-13 1726
-
什么是Hadoop? Spark和Hadoop对比2018-06-04 7206
-
Hadoop的整体框架组成2018-05-11 2186
-
从零开始学习hadoop?hadoop快速入门2018-03-13 3742
-
hadoop基本命令大全2018-01-02 8780
-
hadoop开发环境搭建2017-12-25 3188
-
用Linux和Apache Hadoop进行云计算2012-03-31 573
全部0条评论

快来发表一下你的评论吧 !
