

什么叫数据挖掘_数据挖掘技术解析
人工智能
描述
数据挖掘(data mining)是指从大量的资料中自动搜索隐藏于其中的有着特殊关联性的信息的过程。在全世界的计算机存储中,存在未使用的海量数据并且它们还在快速增长,这些数据就像待挖掘的金矿,而进行数据分析的科学家、工程师、分析员的数量变化一直相对较小,这种差距称为数据挖掘产生的主要原因。数据挖掘是一个多学科交叉领域,涉及神经网络、遗传算法、回归、统计分析、机器学习、聚类分析、特异群分析等,开发挖掘大型海量和多维数据集的算法和系统,开发合适的隐私和安全模式,提高数据系统的使用简便性。
数据挖掘与传统意义上的统计学不同。统计学推断是假设驱动的,即形成假设并在数据基础上验证他;数据挖掘是数据驱动的,即自动地从数据中提取模式和假设。数据挖掘的目标是提取可以容易转换成逻辑规则或可视化表示的定性模型,与传统的统计学相比,更加以人为本。
数据挖掘技术简述
数据挖掘的技术有很多种,按照不同的分类有不同的分类法。下面着重讨论一下数据挖掘中常用的一些技术:统计技术,关联规则,基于历史的分析,遗传算法,聚集检测,连接分析,决策树,神经网络,粗糙集,模糊集,回归分析,差别分析,概念描述等十三种常用的数据挖掘的技术。
1、统计技术
数据挖掘涉及的科学领域和技术很多,如统计技术。统计技术对数据集进行挖掘的主要思想是:统计的方法对给定的数据集合假设了一个分布或者概率模型(例如一个正态分布)然后根据模型采用相应的方法来进行挖掘。
2、关联规则
数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之I司存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,即使知道也是不确定的,因此关联分析生成的规则带有可信度。
3、基于历史的MBR(Memory-based Reasoning)分析
先根据经验知识寻找相似的情况,然后将这些情况的信息应用于当前的例子中。这个就是MBR(Memory Based Reasoning)的本质。MBR首先寻找和新记录相似的邻居,然后利用这些邻居对新数据进行分类和估值。使用MBR有三个主要问题,寻找确定的历史数据;决定表示历史数据的最有效的方法;决定距离函数、联合函数和邻居的数量。
4、遗传算法GA(Genetic Algorithms)
基于进化理论,并采用遗传结合、遗传变异、以及自然选择等设计方法的优化技术。主要思想是:根据适者生存的原则,形成由当前群体中最适合的规则组成新的群体,以及这些规则的后代。典型情况下,规则的适合度(Fitness)用它对训练样本集的分类准确率评估。
5、聚集检测
将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其它簇中的对象相异。相异度是根据描述对象的属眭值来计算的,距离是经常采用的度量方式。
6、连接分析
连接分析,Link analysis,它的基本理论是图论。图论的思想是寻找一个可以得出好结果但不是完美结果的算法,而不是去寻找完美的解的算法。连接分析就是运用了这样的思想:不完美的结果如果是可行的,那么这样的分析就是一个好的分析。利用连接分析,可以从一些用户的行为中分析出一些模式;同时将产生的概念应用于更广的用户群体中。
7、决策树
决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法。
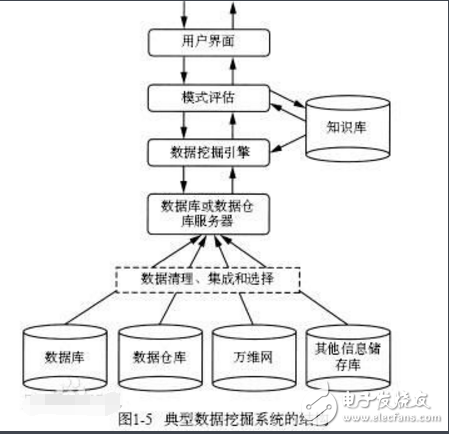
8、神经网络
在结构上,可以把一个神经网络划分为输入层、输出层和隐含层。输入层的每个节点对应—个个的预测变量。输出层的节点对应目标变量,可有多个。在输入层和输出层之间是隐含层(对神经网络使用者来说不可见),隐含层的层数和每层节点的个数决定了神经网络的复杂度。
除了输入层的节点,神经网络的每个节点都与很多它前面的节点(称为此节点的输入节点)连接在一起,每个连接对应一个权重Wxy,此节点的值就是通过它所有输入节点的值与对应连接权重乘积的和作为—个函数的输入而得到,我们把这个函数称为活动函数或挤压函数。
9、粗糙集
粗糙集理论基于给定训练数据内部的等价类的建立。形成等价类的所有数据样本是不加区分的,即对于描述数据的属性,这些样本是等价的。给定现实世界数据,通常有些类不能被可用的属性区分。粗糙集就是用来近似或粗略地定义这种类。
10、模糊集
模糊集理论将模糊逻辑引入数据挖掘分类系统,允许定义“模糊”域值或边界。模糊逻辑使用0.0和1.0之间的真值表示一个特定的值是一个给定成员的程度,而不是用类或集合的精确截断。模糊逻辑提供了在高抽象层处理的便利。
11、回归分析
回归分析分为线性回归、多元回归和非线性同归。在线性回归中,数据用直线建模,多元回归是线性回归的扩展,涉及多个预测变量。非线性回归是在基本线性模型上添加多项式项形成非线性同门模型。
12、差别分析
差别分析的目的是试图发现数据中的异常情况,如噪音数据,欺诈数据等异常数据,从而获得有用信息。
13、概念描述
概念描述就是对某类对象的内涵进行描述,并概括这类对象的有关特征。概念描述分为特征性描述和区别性描述,前者描述某类对象的共同特征,后者描述不同类对象之间的区别,生成一个类的特征性描述只涉及该类对象中所有对象的共性。
商业应用数据挖掘的实现步骤:
1. 进行多部门访谈,以用户实际发生的行为为主要信息来源,确定并理解商业目标;
2. 数据挖掘的数据准备和数据理解;
3. 建立模型,模型评估,结果发布。
数据挖掘的具体应用举例:
1.商业管理:数据库营销、客户群体划分、背景分析、交叉销售等市场分析行为,以及客户流失性分析、客户信用记分、欺诈发现等。
2.营销方面:通过收集、加工和处理涉及消费者消费行为的大量信息,确定特定消费群体或个体的兴趣、消费习惯、消费倾向和消费需求,进而推断出相应消费群体或个体下一步的消费行为,然后以此为基础,对所识别出来的消费群体进行特定内容的定向营销,提高了营销效果,从而为企业带来更多的利润。
3.企业危机管理:对企业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助经营决策的关键性数据。
4. 产品制造:在产品的生产制造过程中常常伴随有大量的数据,如产品的各种加工条件或控制参数(如时间、温度等控制参数),这些数据反映了每个生产环节的状态,不仅为生产的顺利进行提供了保证,而且通过对这些数据的分析,得到产品质量与这些参数之间的关系。这样通过数据挖掘对这些数据的分析,可以对改进产品质量提出针对性很强的建议,而且有可能提出新的更高效节约的控制模式,从而为制造厂家带来极大的回报。这方面的系统有CASSIOPEE(由Acknosoft公司用KATE发现工具开发的),已用于诊断和预测在制造波音飞机制造过程中可能出现的问题。
5. Internet应用:SNS应用数据挖掘,给用户带来基于直接信息的大量潜在信息和价值,能够一直保持用户对SNS的兴趣。商家能够更方便的将商品推送给目标人群,消费者也更容易买到最实惠的自己最需要的产品。
-
机器学习与数据挖掘方法和应用2023-09-26 778
-
python数据挖掘与机器学习2023-08-17 2294
-
数据挖掘定义及方法 数据挖掘在微电子领域的应用2023-07-18 871
-
数据挖掘之基于关联挖掘的商品销售分析2020-06-09 1867
-
数据挖掘算法有哪几种?2020-03-11 2131
-
NLPIR大数据KGB知识图谱引擎智能挖掘各行数据2018-11-02 2041
-
怎么学习数据挖掘_如何系统地学习数据挖掘2017-12-31 7736
-
数据挖掘方法有哪些_数据挖掘方法分类总结2017-12-29 72199
-
云计算数据挖掘2016-04-19 2992
-
中医毒热数据挖掘系统的设计与实现2009-12-25 639
-
基于隐私保护的数据挖掘2009-04-23 656
-
数据挖掘 (pdf版)2009-01-13 848
-
数据挖掘浅析2009-01-08 605
全部0条评论

快来发表一下你的评论吧 !
